How quickly can vSAN evacuate data from my disk? Great question and of course the answer is “it depends”. On disks performance, network performance but also on the current I/O load of the cluster.
It seems there are a lot of dependencies, but vSAN has it covered. Resync dashboards, resync throttling (use with care), fairnes scheduler, performance dashboards, pre-checks and esxtop – all of those are there to make the data evacuation easier, regardless of the reason of the evacuation. It can be a migration to a larger disk, disk group rebuild or moving from hybrid to all-flash cluster.
Let’s check those tools.
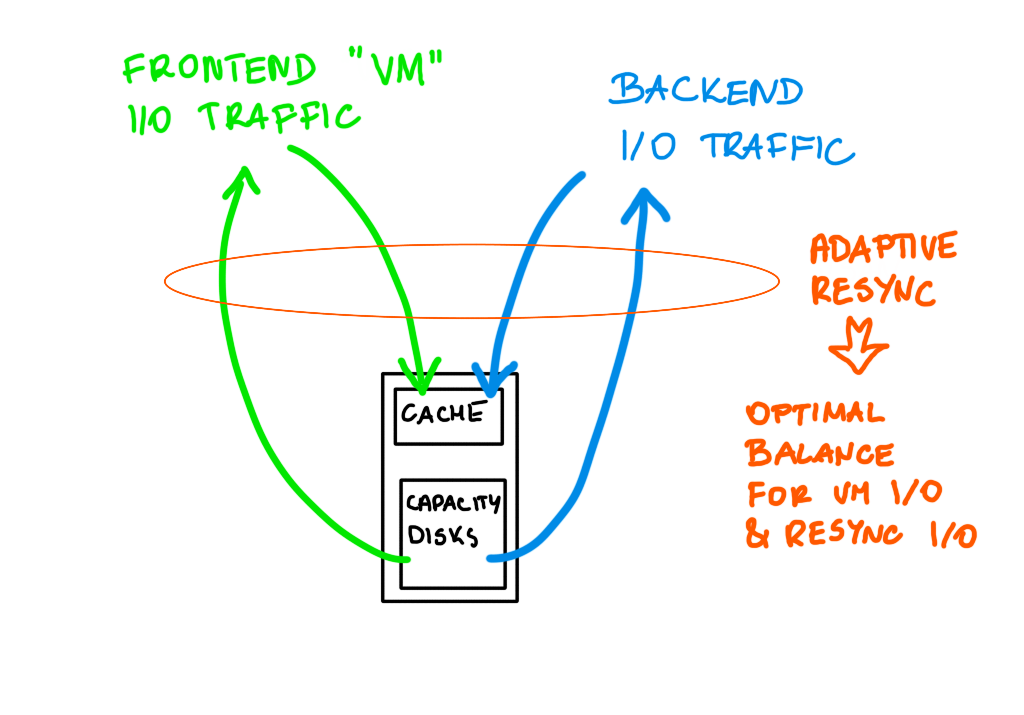
Fairness scheduler is a mechanizm that keeps a healthy balance between frontend I/O (VM I/O) and backend I/O (policy changes, evacuations, rebalancing, repairs). It is very important because the disk group throughput has to be shared between many types of I/O traffic and on one hand we want the resync to complete as fast as possible, on the other, it cannot affect VM I/O.
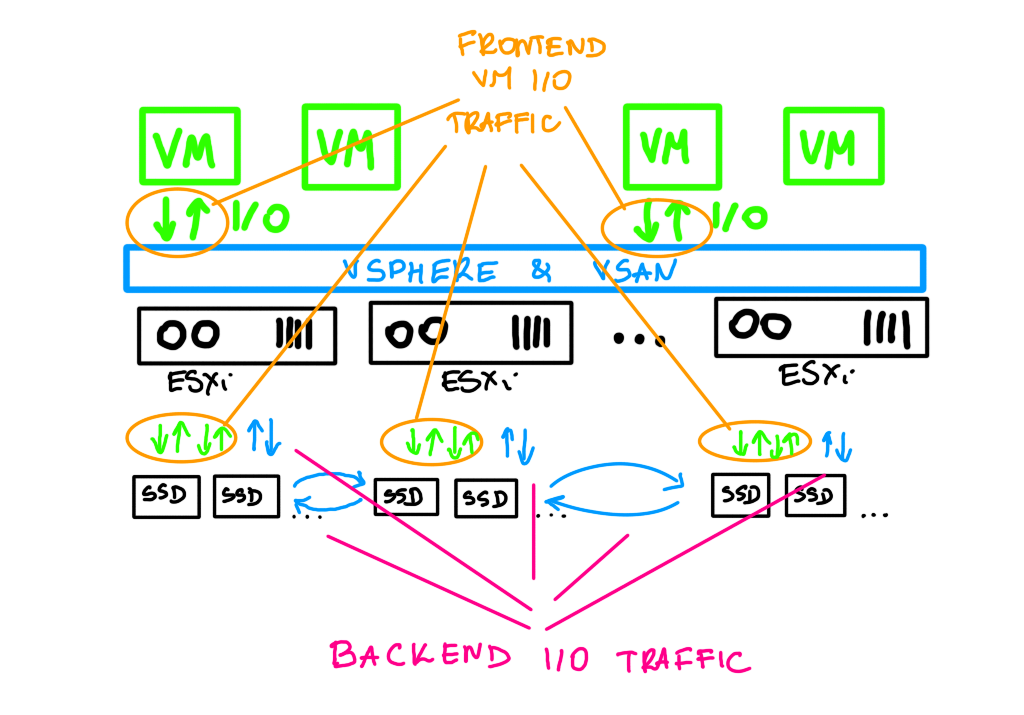
vSAN can distinguish traffic types, prioritize the traffic and adapt to the current condition of the cluster.
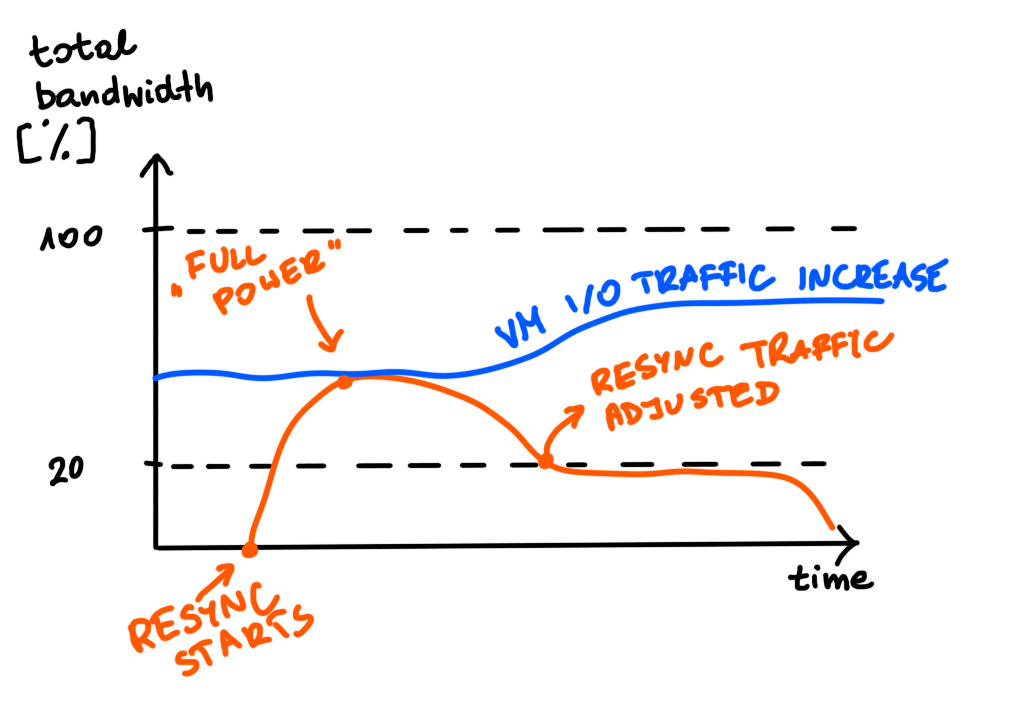
It is like in the picture below. If there is no contention, resync or VM I/O use “full speed”. If VMs need more of the disk throughput, resync I/O is throttled for this period of time to max 20% of the disk throughput.
Pre-check evacuation option will help you to determine what components of the object can be potentially affected by the disk evacuation. You can select the preferred ‘vSAN data migration’ option: this can be a full migration, ensuring the accessibility of the object or no data migration at all.
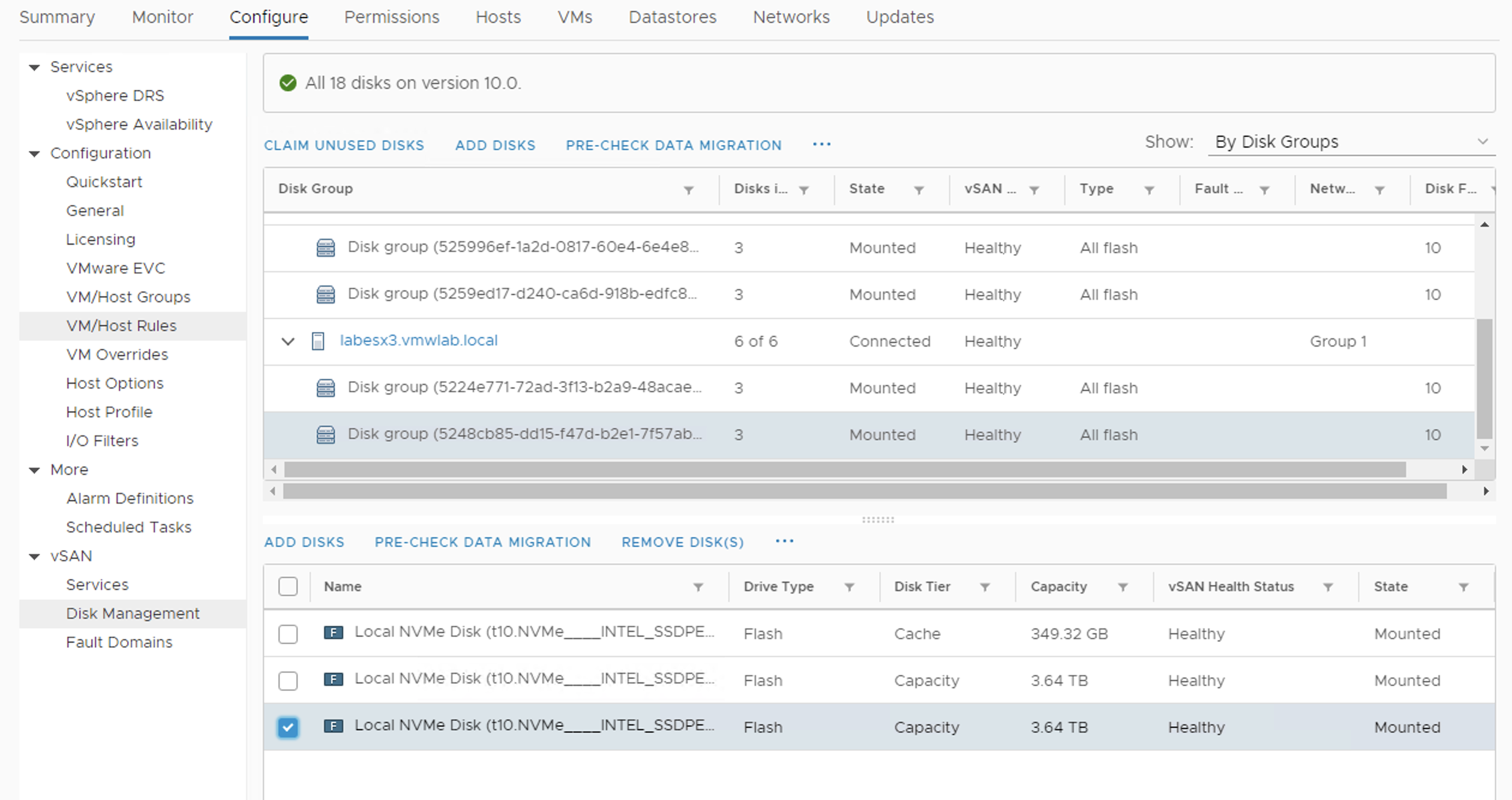
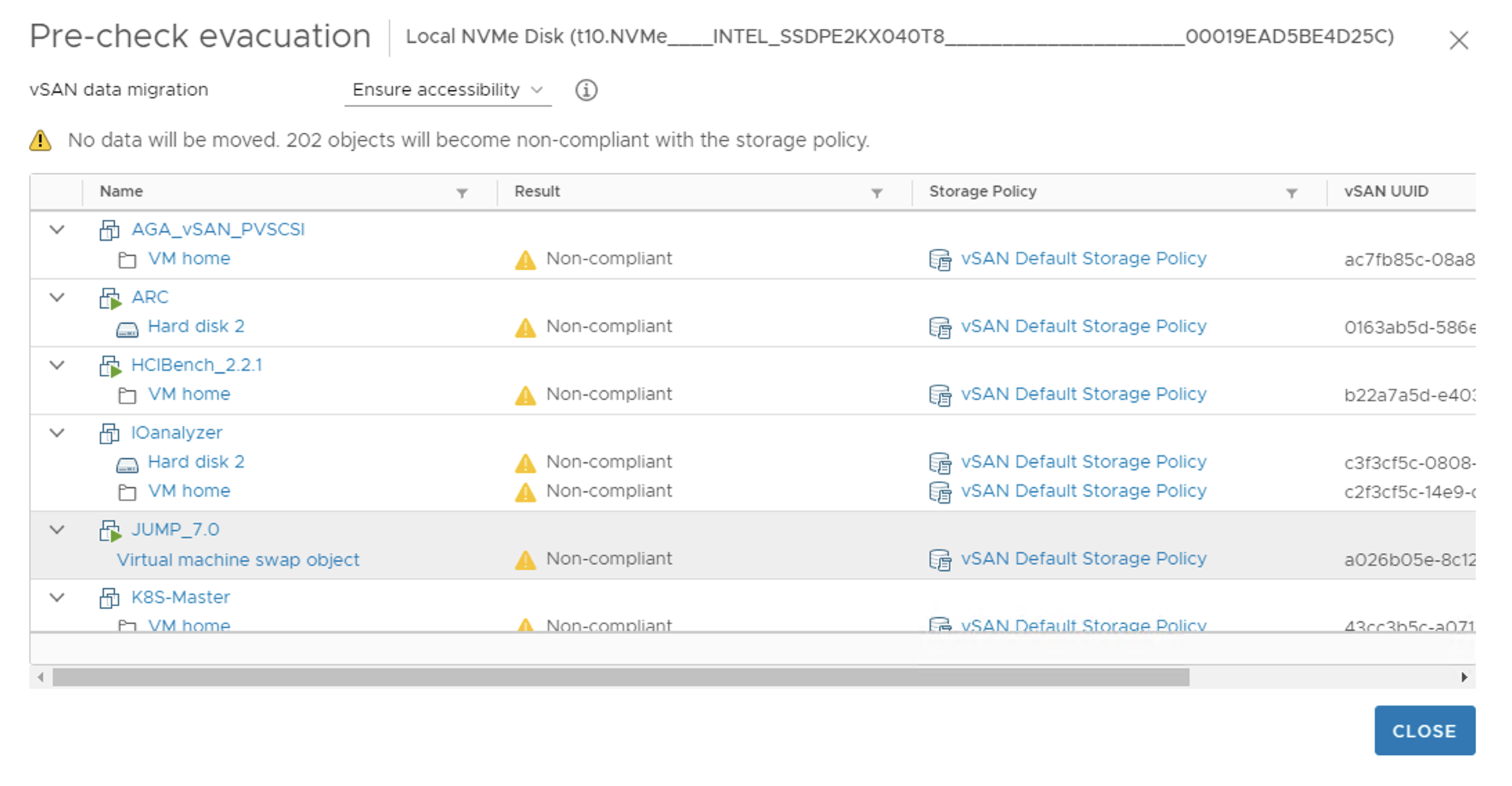
The potential status of the components can vary. The pre-check will also let you know if you have enough space to move the data. Non-Compliant status of the object means the object will be accessible but it will not be compliant to the vSAN Storage Policy. At least for some time till the rebuild is finished.
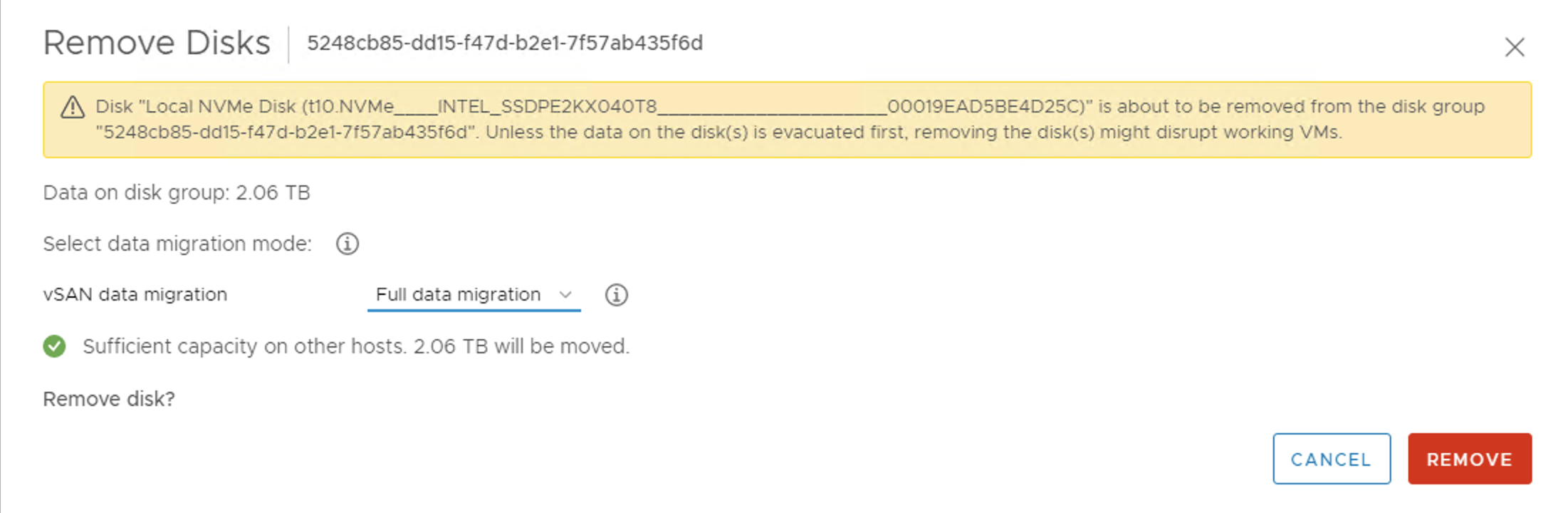
You can use resyncing objects dashboard to monitor the status if the vSAN background activities. With each activity you can check the reason for it. It can be a decommissioning like on the screen below when we remove a disk and evacuate data.
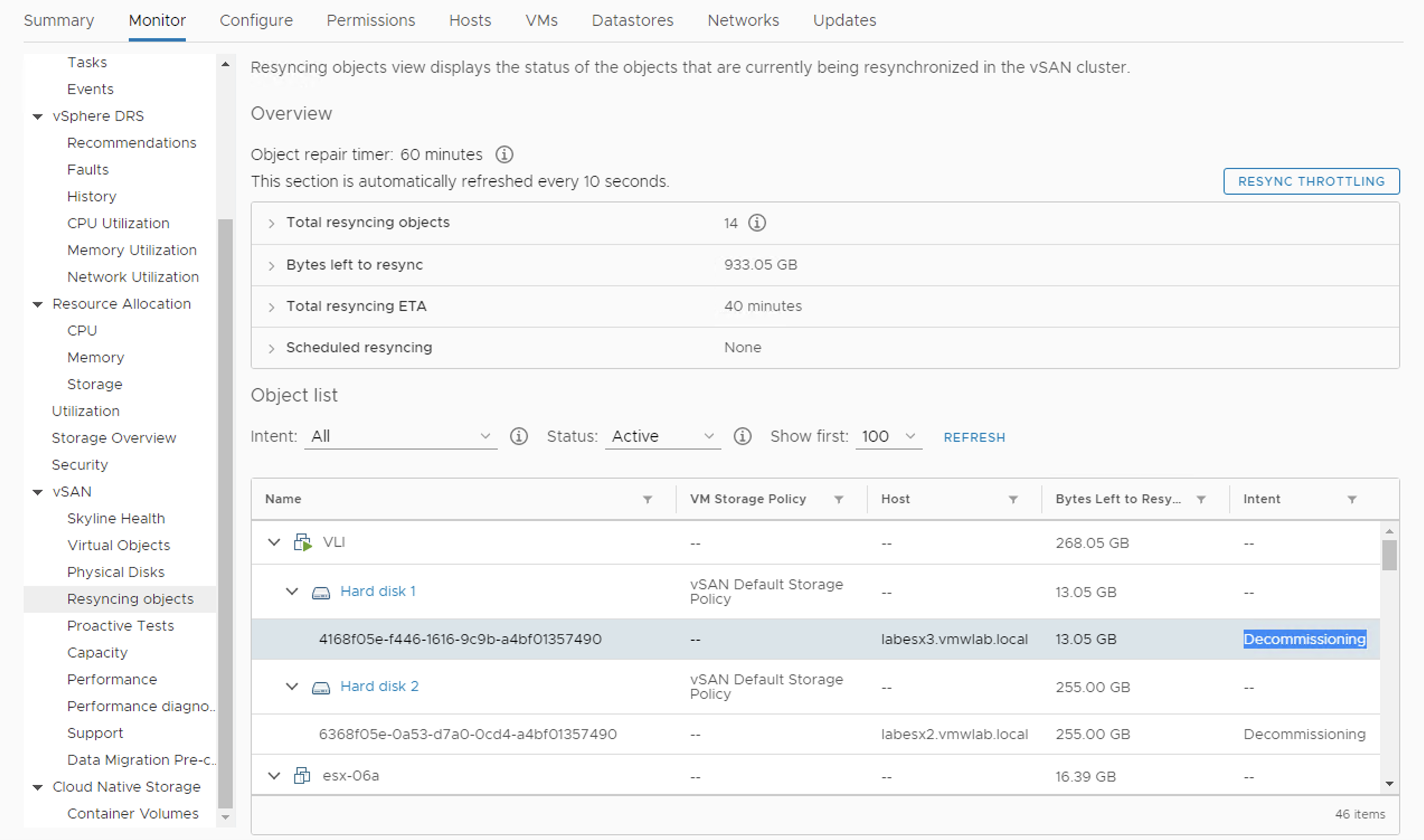
The full list of the reasons (from Resyncin objects tab):
- Decommissioning: The component is created and is resyncing after evacuation of disk group or host, to ensure accessibility and full data evacuation.
- Compliance: The component is created and is resyncing to repair a bad component, or after vSAN object was resized, or its policy was changed.
- Disk evacuation: The component is being moved out because a disk is going to fail.
- Rebalance: The component is created and is resyncing for cluster rebalancing.
- Stale: Repairing component which are out of sync with it’s replica.
- Concatenation merge: Cleanup concatenation by merging them. Concatenation can be added to support the increased size requirement when object grows.
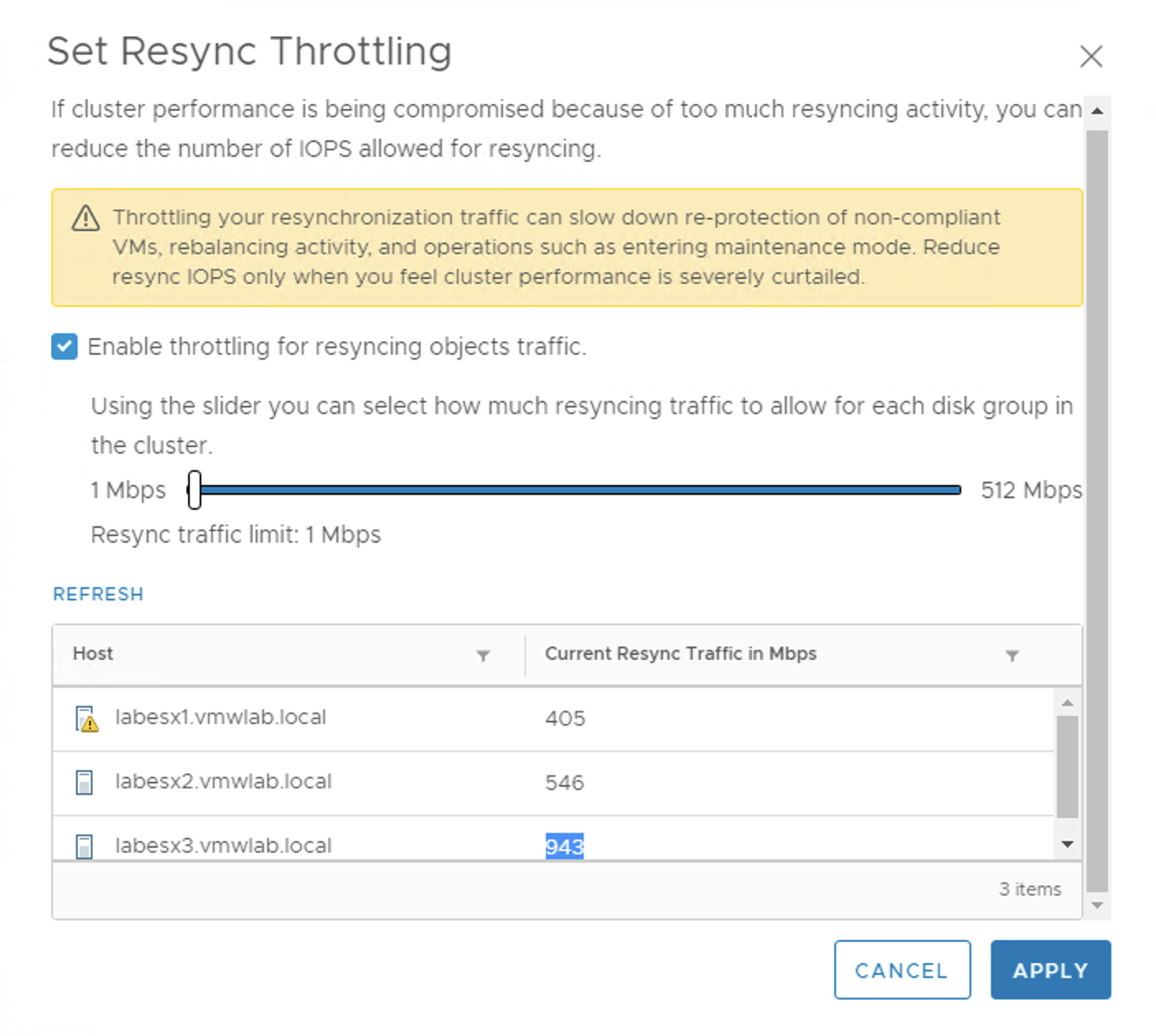
You can also set Resync Throttling, if you wish to manually control the bandwidth. Usually with vSAN fairness scheduler we do not need to modify anything, but it is good to know we can control it in case the need arises.
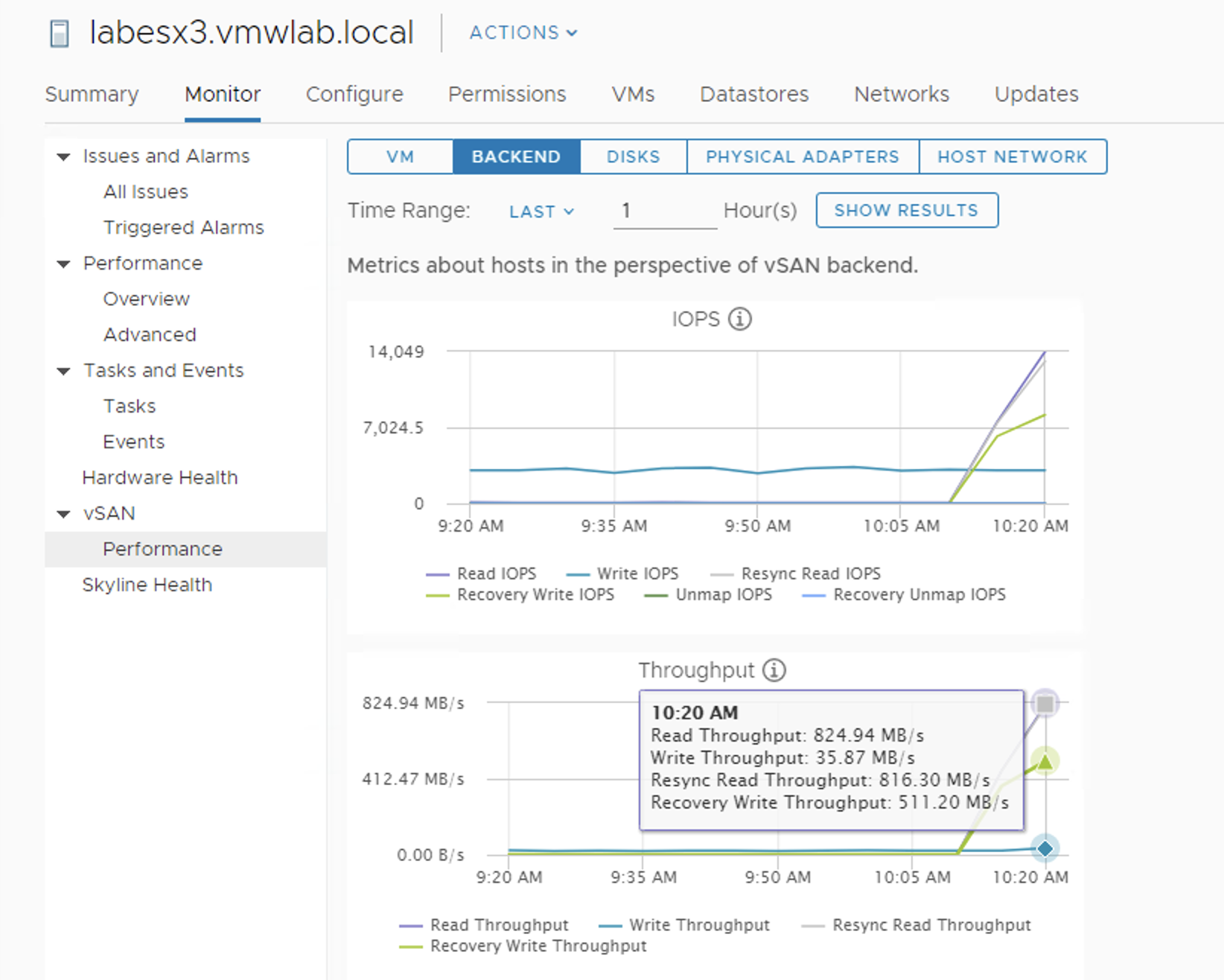
Frontend and backend traffic can be monitored with Performance Dashboard. It is very detailed. We can observe the traffic on the host level, disk group level or even on the disk level. All the traffic types are presented there.
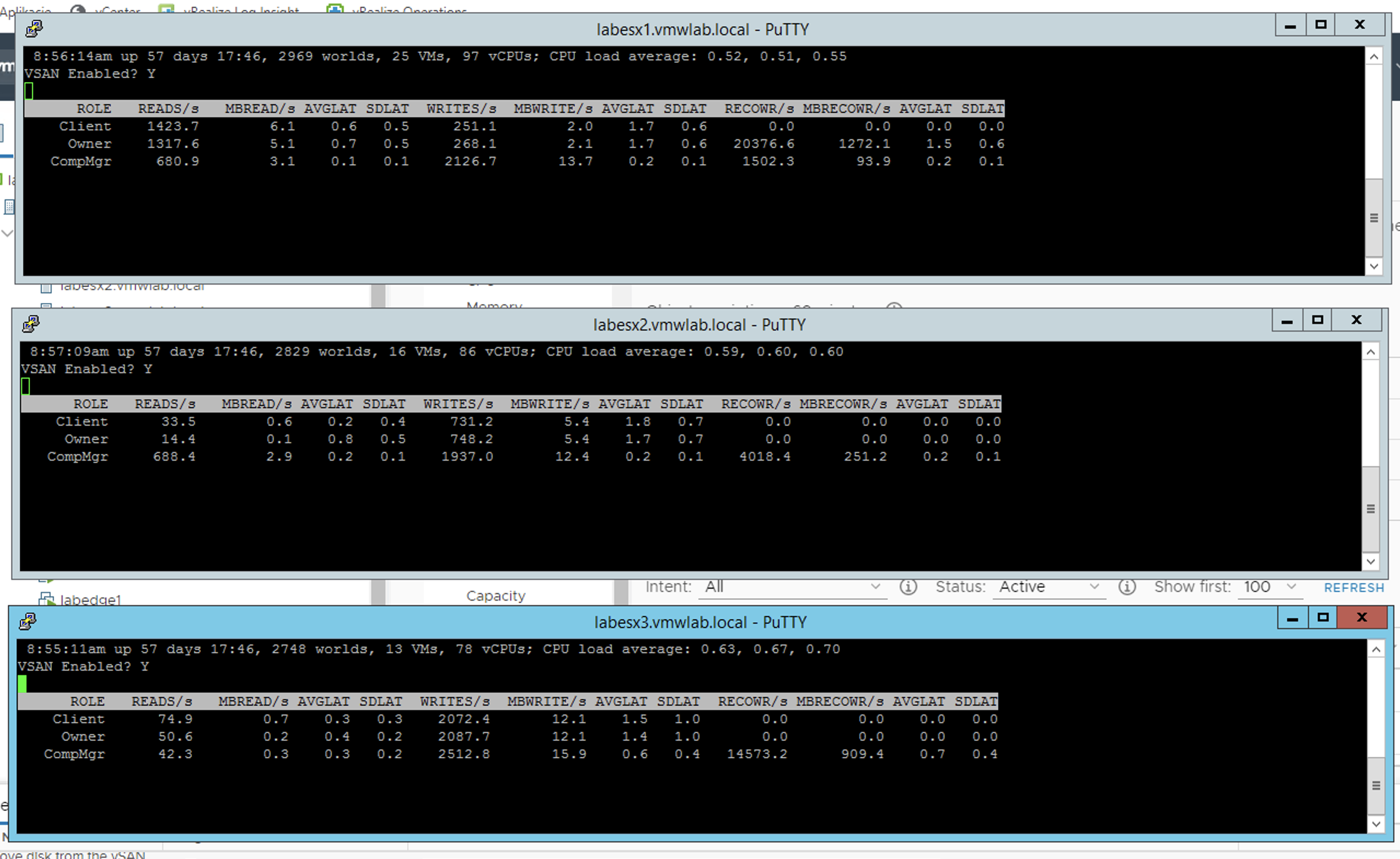
If 5-min granularity is not enough (this is what is being offered by vCenter), we can always ssh to an ESXi. esxtop + x will show near real-time vSAN stats per host. To be able to observe rebuild traffic we need to use option ‘f’ and select ‘D’ for ‘recovery write stats’.

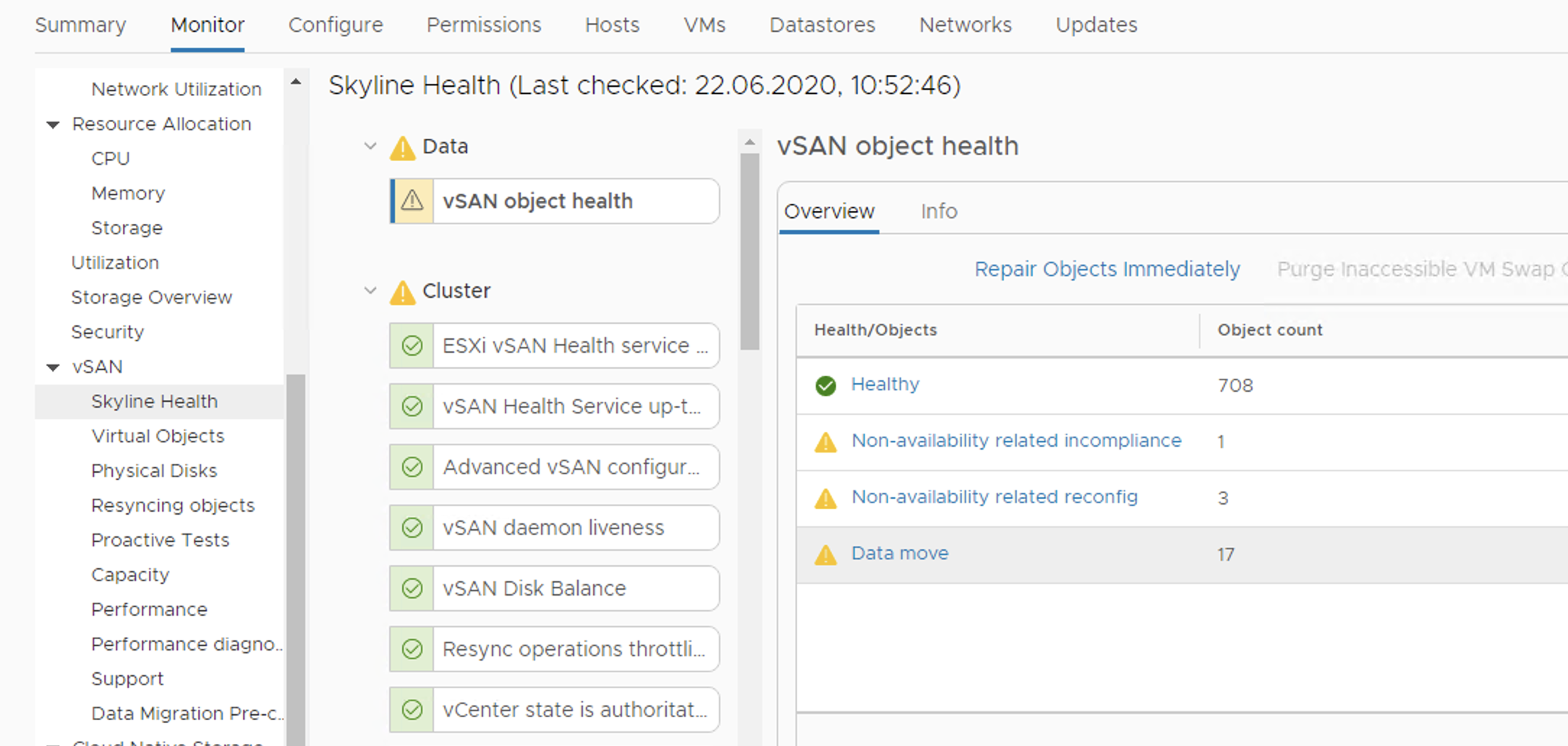
vSAN Health can be also used when we evacuate data from a disk. vSAN Object Health will show us how many objects are being rebuilt. And vSAN Health is also always a good place to check the overall status of the cluster.