Reading Release Notes for vSAN 6.7 U3 you might overlook a very important improvement that was introduced with this release: Increased hardening during capacity-strained scenarios.
“This release includes new robust handling of capacity usage conditions for improved detection, prevention, and remediation of conditions where cluster capacity has exceeded recommended thresholds.“
The question: what happens when vSAN datastore gets full, is a very common one but rarely we have an option to test it. Every admin knows that monitoring free space on EVERY datastore is critical but it doesn’t mean we are not curious how the system reacts when datastore gets full.
Long story short – vSAN has always handled it very well but with 6.7 U3 we get lots of additional new guardrails. I always wanted to test it and now I have some time to do this.
How to fill a datastore with data? Usually I am using HCI Bench that creates lots of VMs with lots of thin provisioned VMDKs and let it run for a while.
First signals
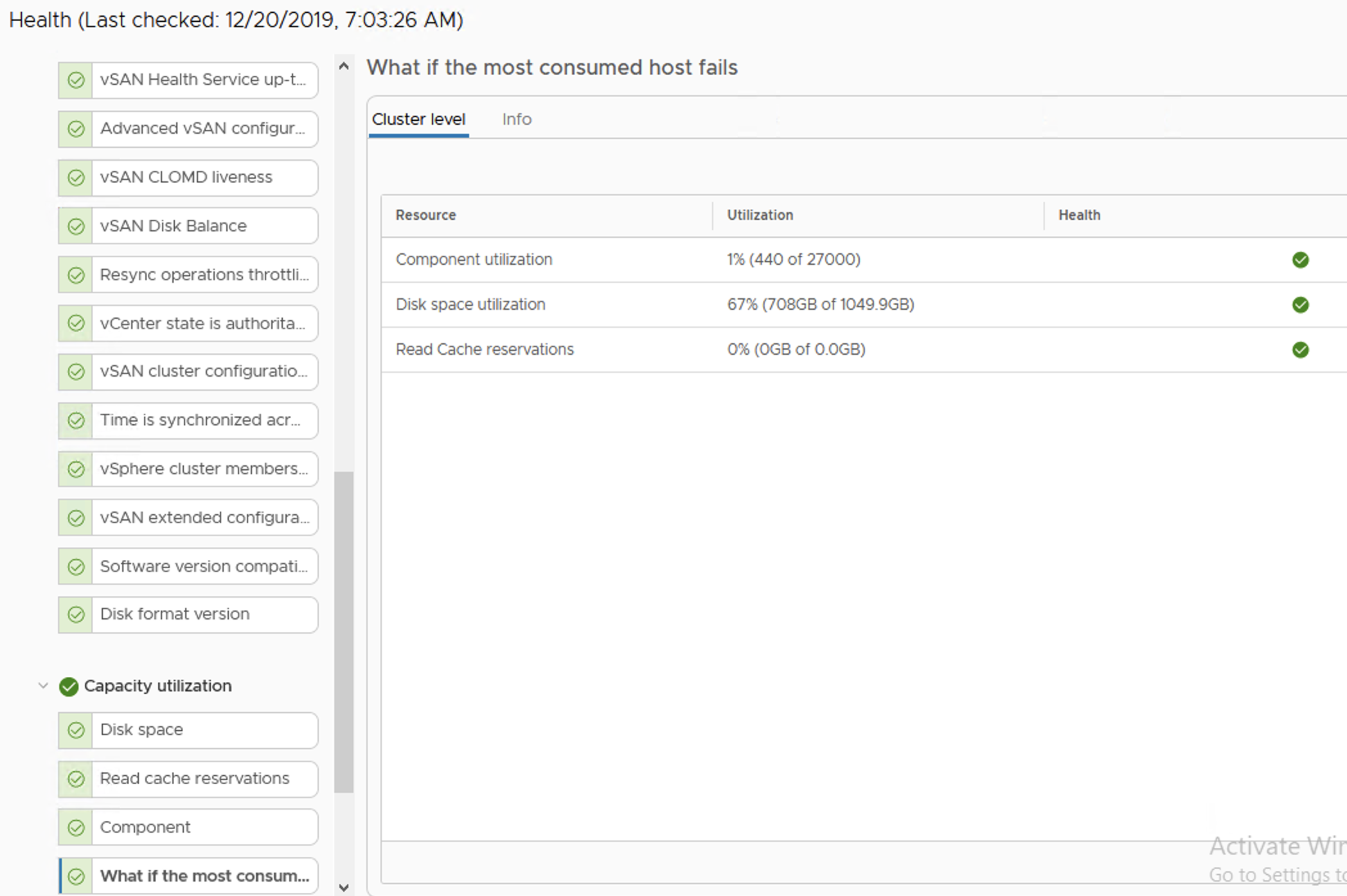
We are informed in a very early phase that something is going on with our datastore. vSAN Health shows a Warning that if we now loose one of the hosts in a cluster, disk space utilization will be high.
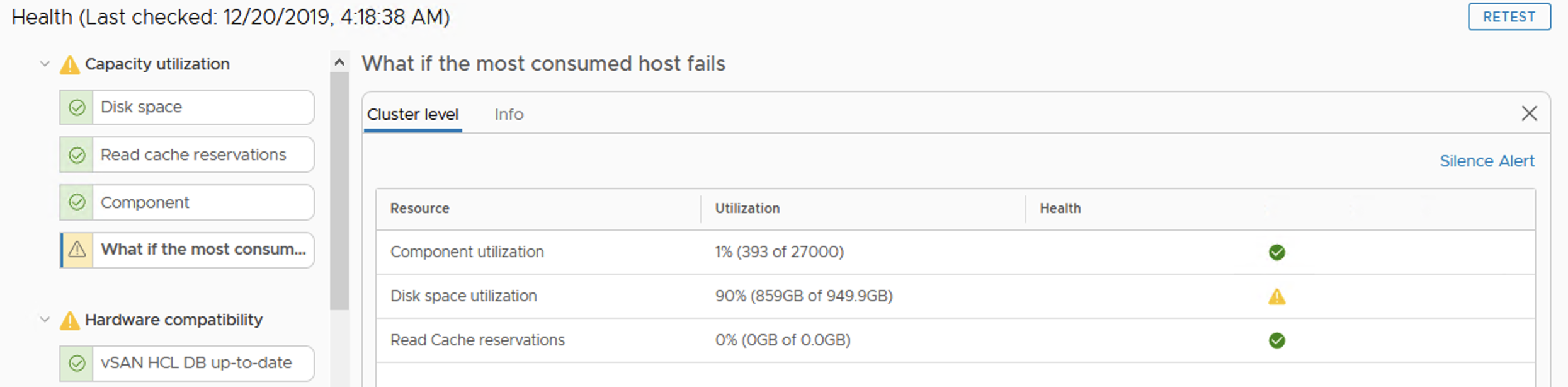
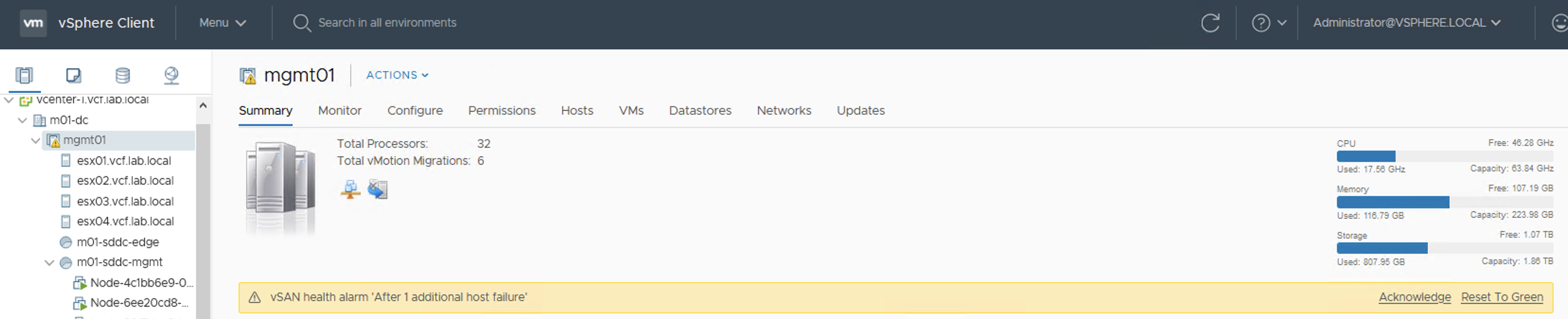
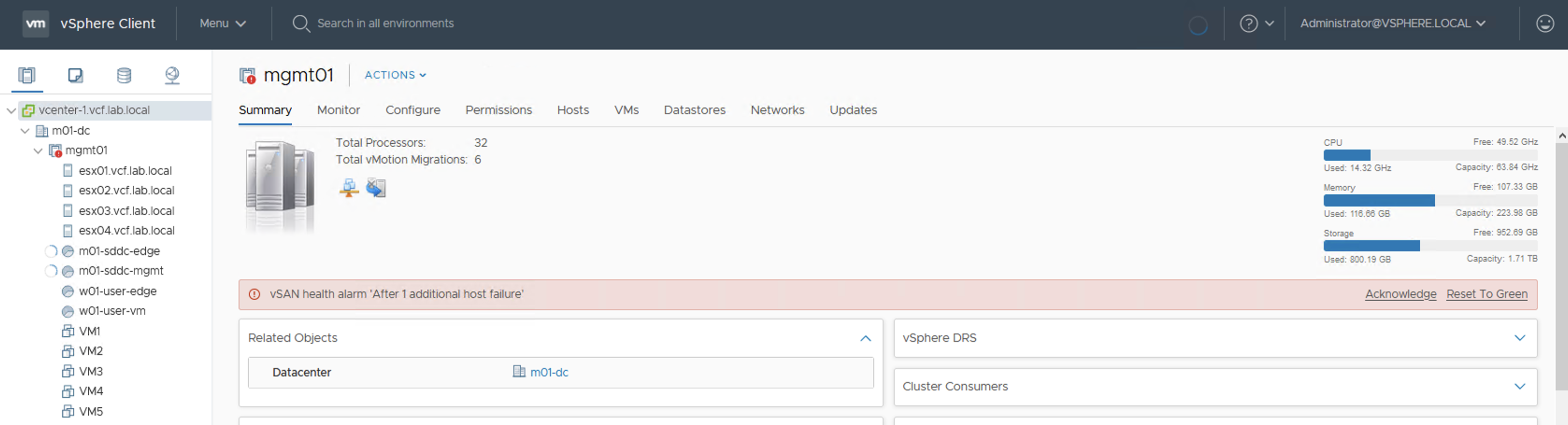
Because more data is filling up this datastore, a Warning turns into an Error. With one host offline there will be no free space on datastore to create VMs. Datastore size doesn’t seem to be full now but this is a summary of all of the datastores in the cluster, not only the vSAN datastore.
End now a very popular datastore alarm appears: “Datastore Usage on disk”. It is the same for VMFS and for vSAN.


If we do not modify alarm settings, we will get a warning at 75% usage and Critical at 85%.
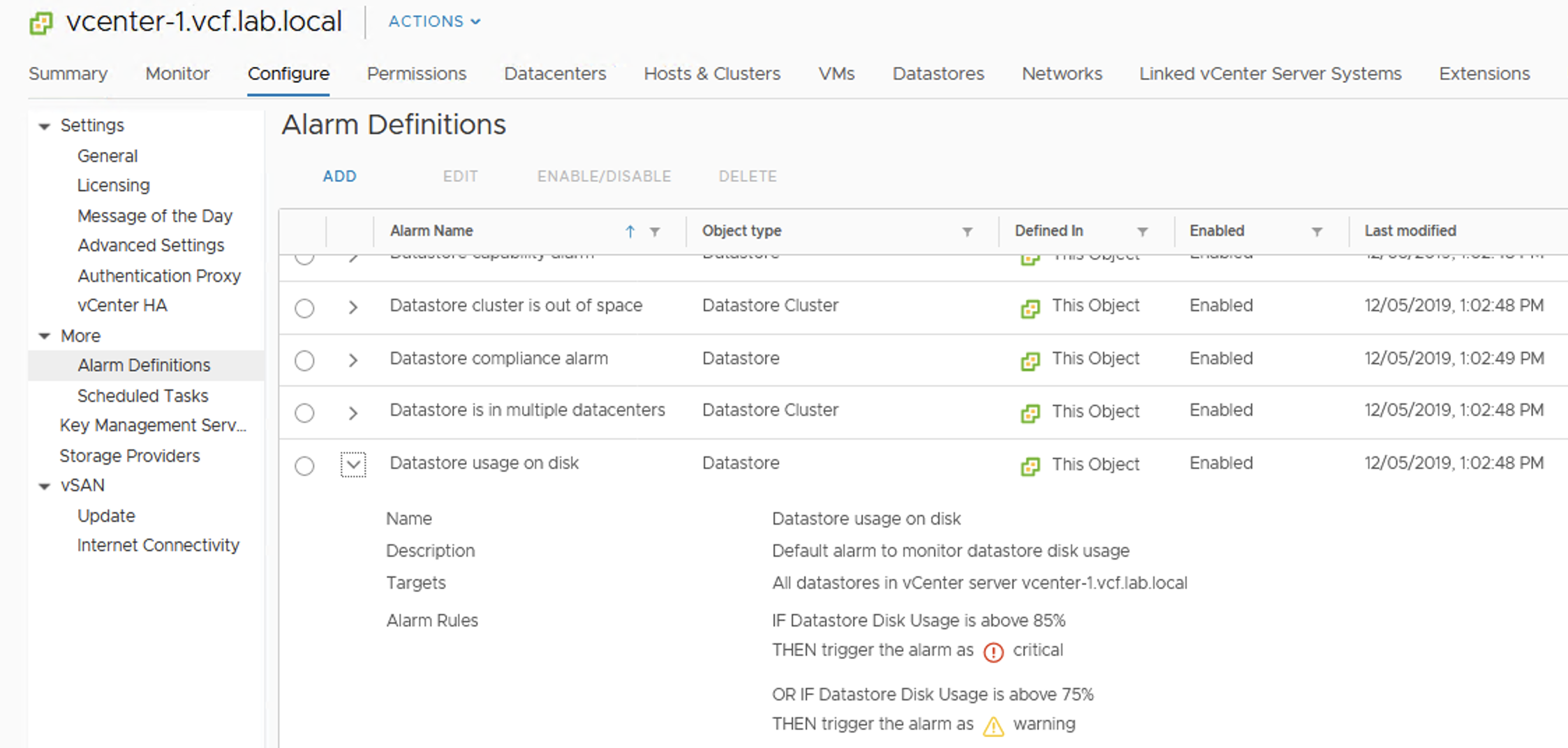
And here it is …


Datasore view and vSAN Capacity view turned red.
It is getting serious
VMs are working fine (especially those that do not write to disks much) but at this point we will not be able to create new VMs (+ FTT-1 mirror policy requires 2 copies of data ).
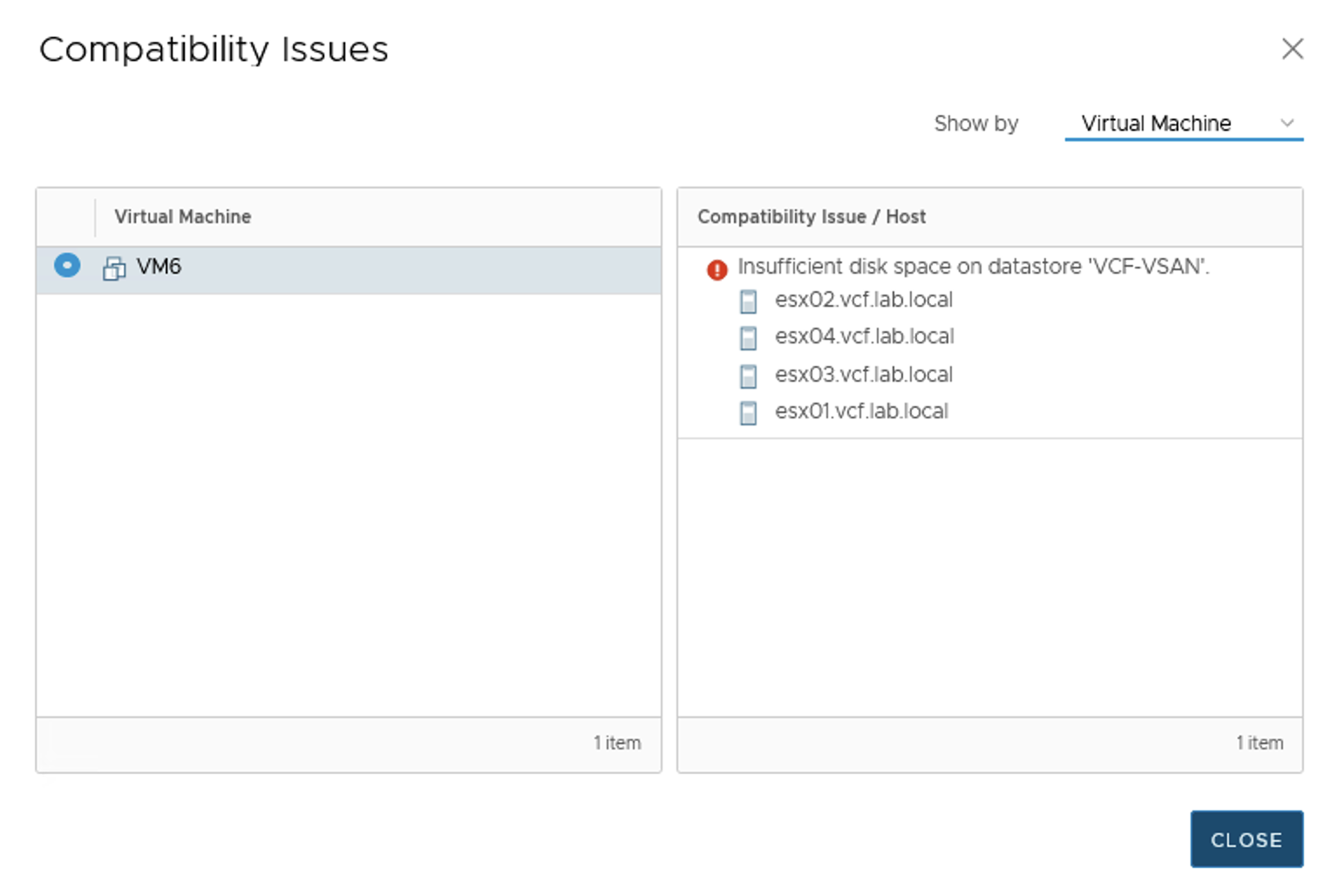
Or clone a VM.
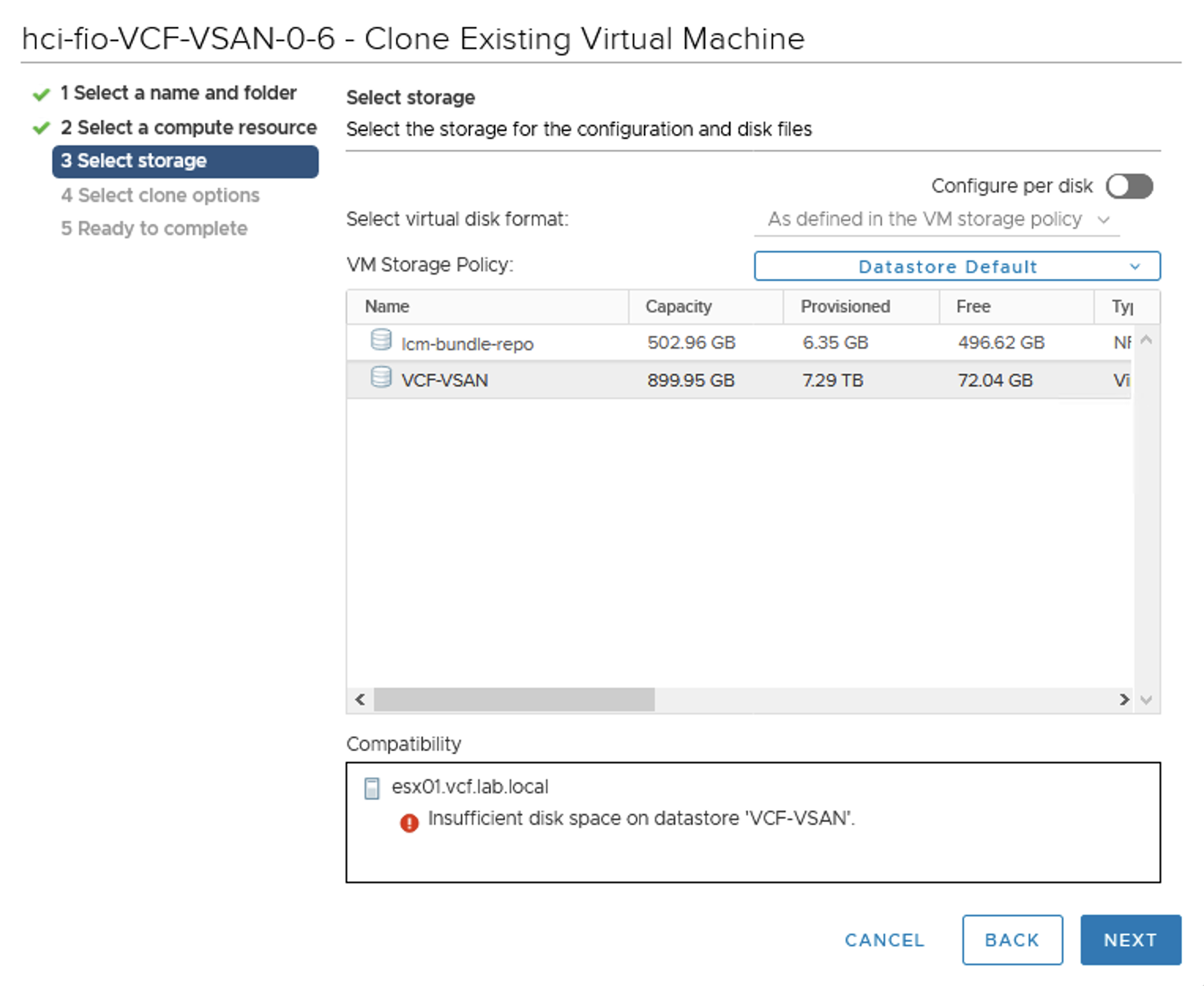
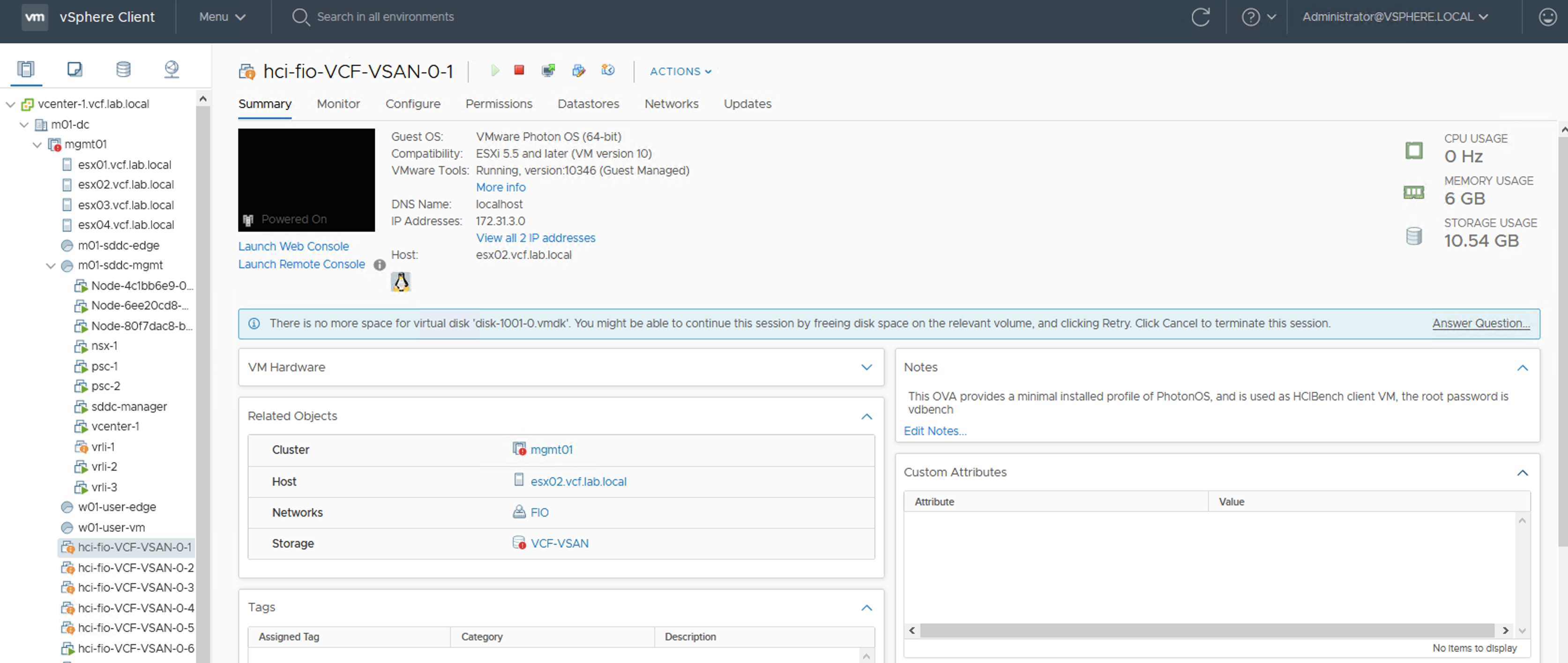
Now some of thin provisioned VMs are stunned. I deliberately run fio 100% sequential write test on them to invoke this process. It looks like datastore full test affected also my vRLI VM that was probably writing new datastore full logs on its VMDKs. Other VMs run fine.
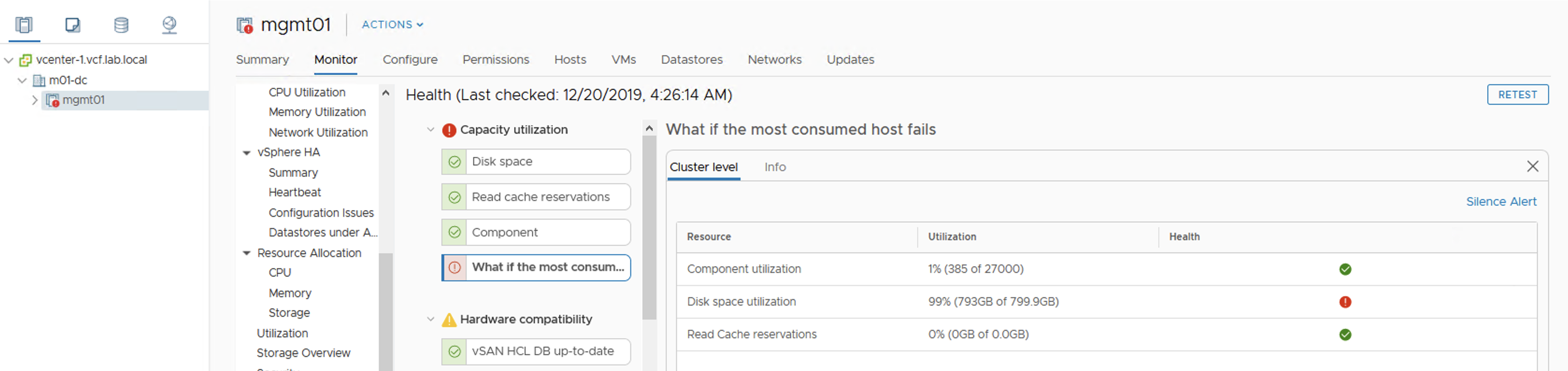
Quick check on vSAN Health:
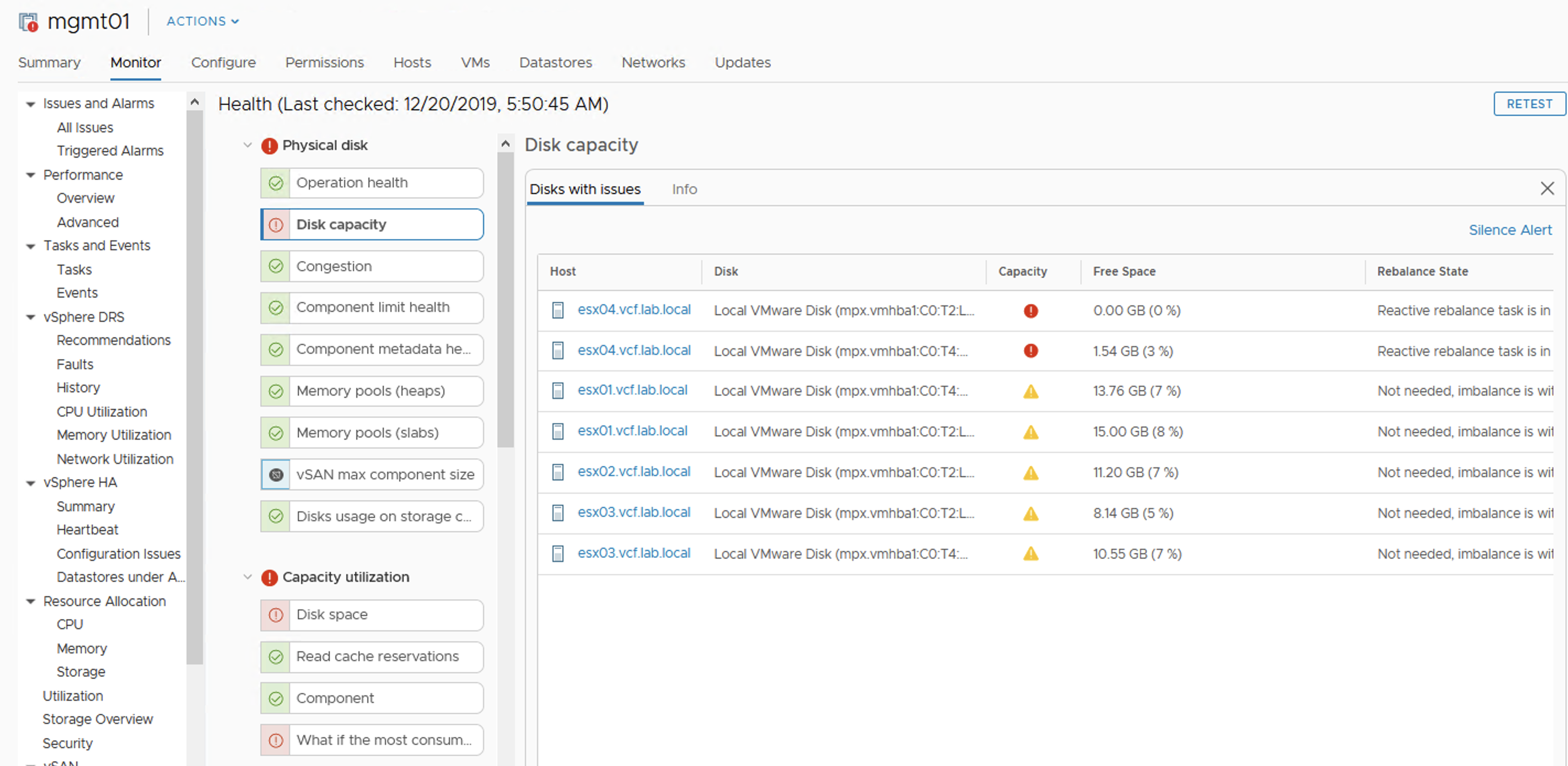
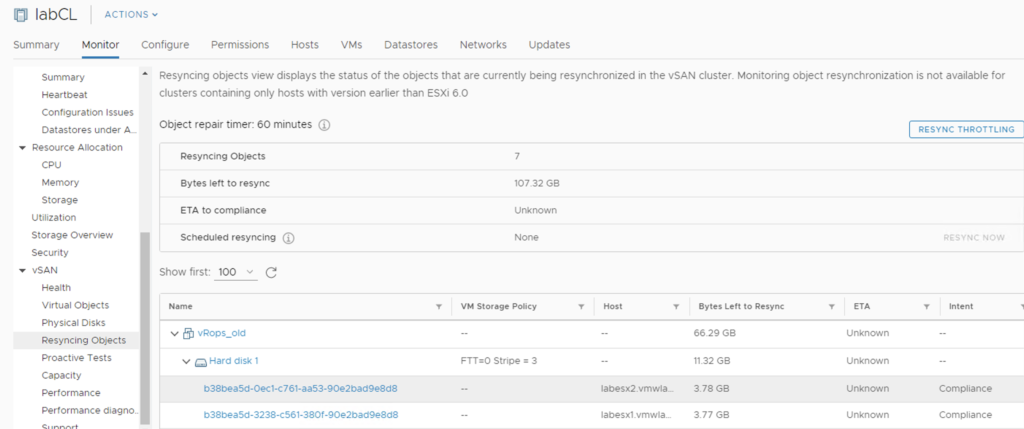
At this point rebalancing is scheduled but not running, because datastore is getting full so there is no point in doing this. It looks like vSAN will not allow to get 100% full, it queues some activities. Hosts are fully responsive, vCenter as well. I am able to power off VMs, run some management activities. Well done vSAN!
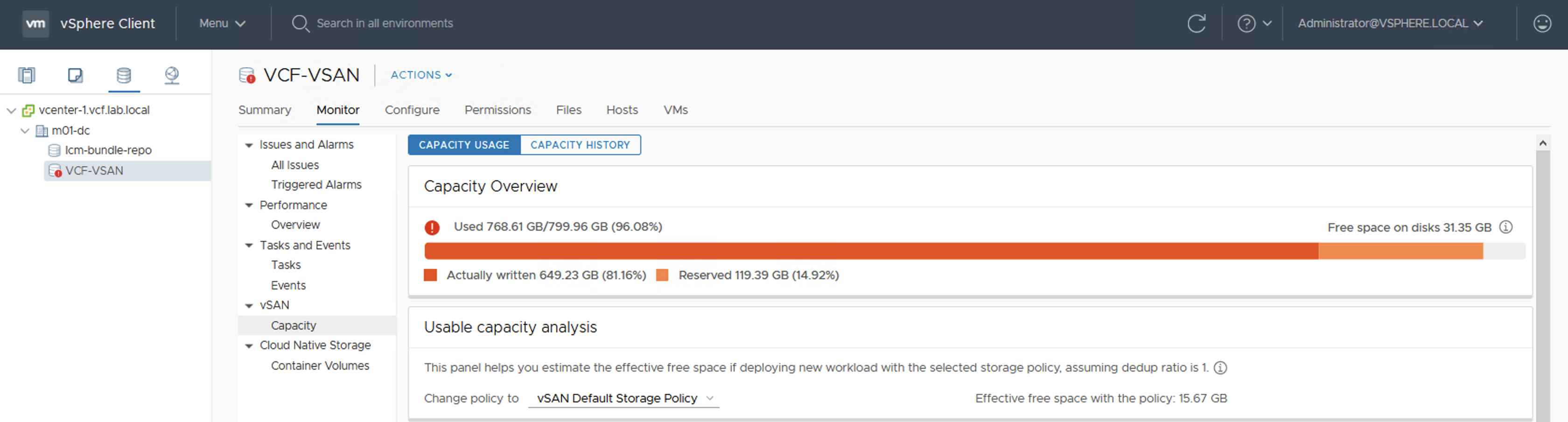
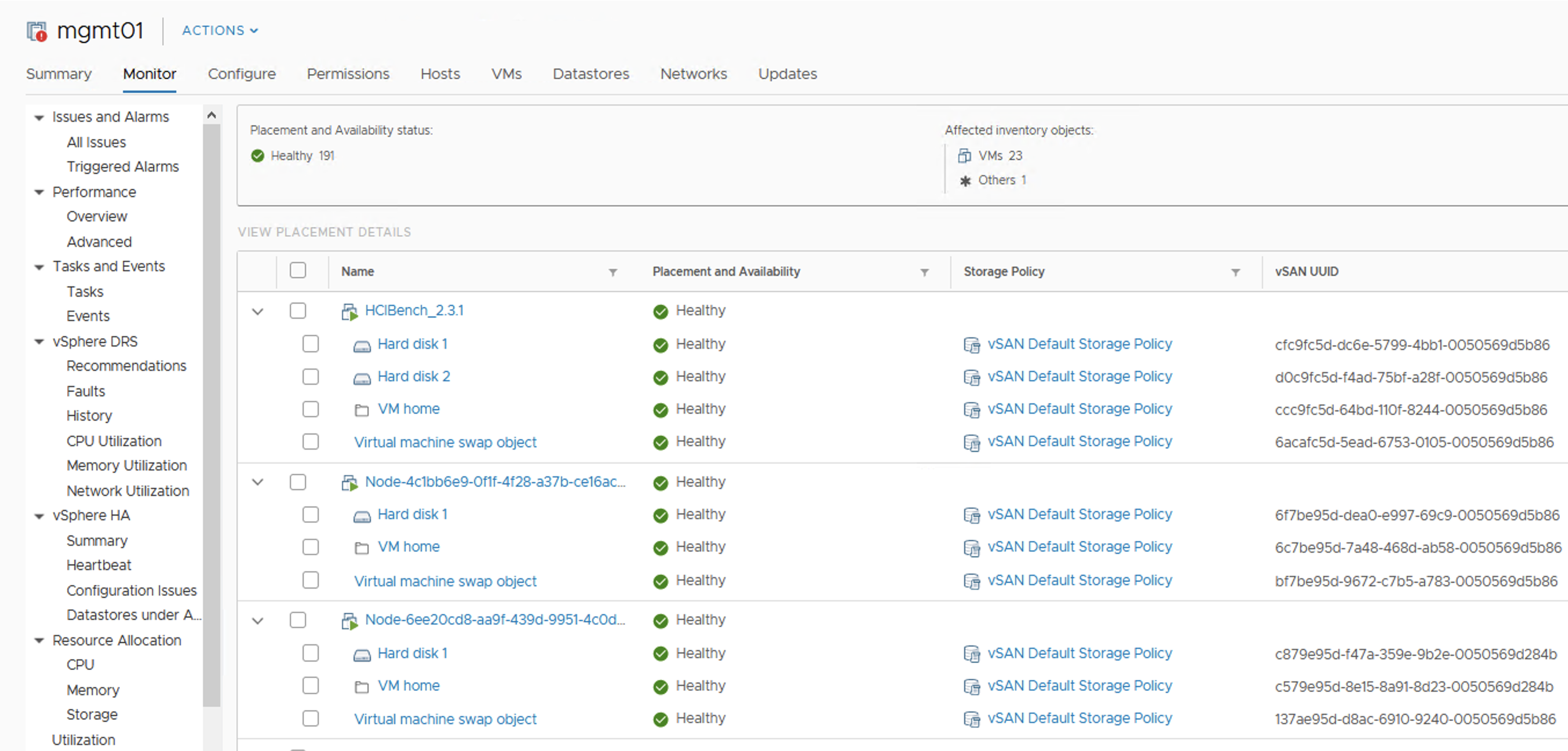
Ultimate test
Ok, let’s get one of the hosts offline. I was not able to evacuate all data from the host because of the lack of free space, so I used “Ensure Accessibility” option. Objects are still Healthy but some of them that had components on the esx04 have just lost one copy. I tried to force rebuild them, some of them actually did rebuild but then process paused. vSAN really guards the last free GBs for the sake of the health of the whole cluster.
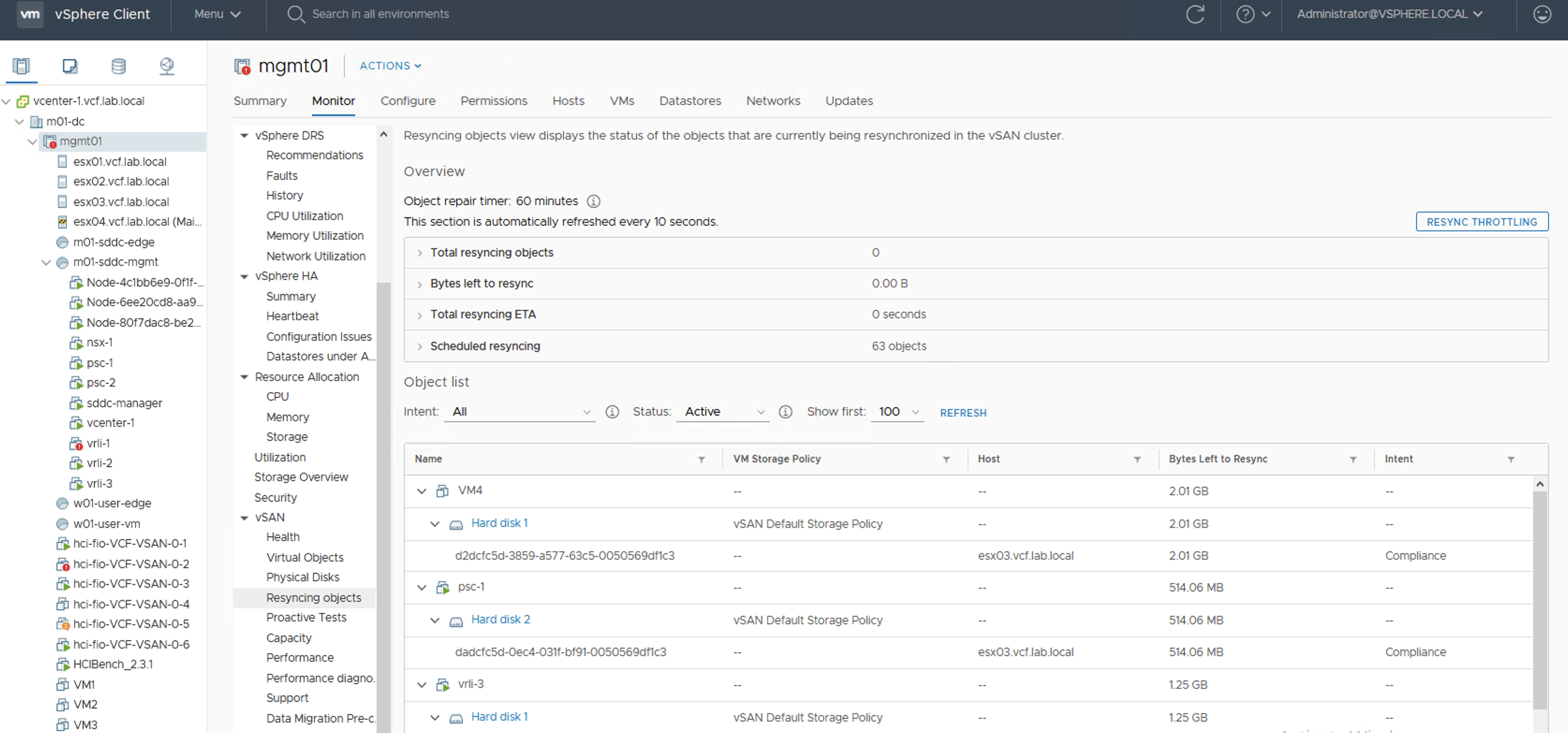
How to get out of it?
Exactly the same way like we do with VMFS. We can power off some VMs (free some swap, but it is thin provisioned so this may be not enough), we can delete VMs (bad idea in production) but we can also…download a VM from vSAN Datastore. In 6.7.U3 it finally works! 😉
The VMDK on the datastore will be twice as big as downloaded one for VMs with mirror storage policy. My VMDK is around 500MB.
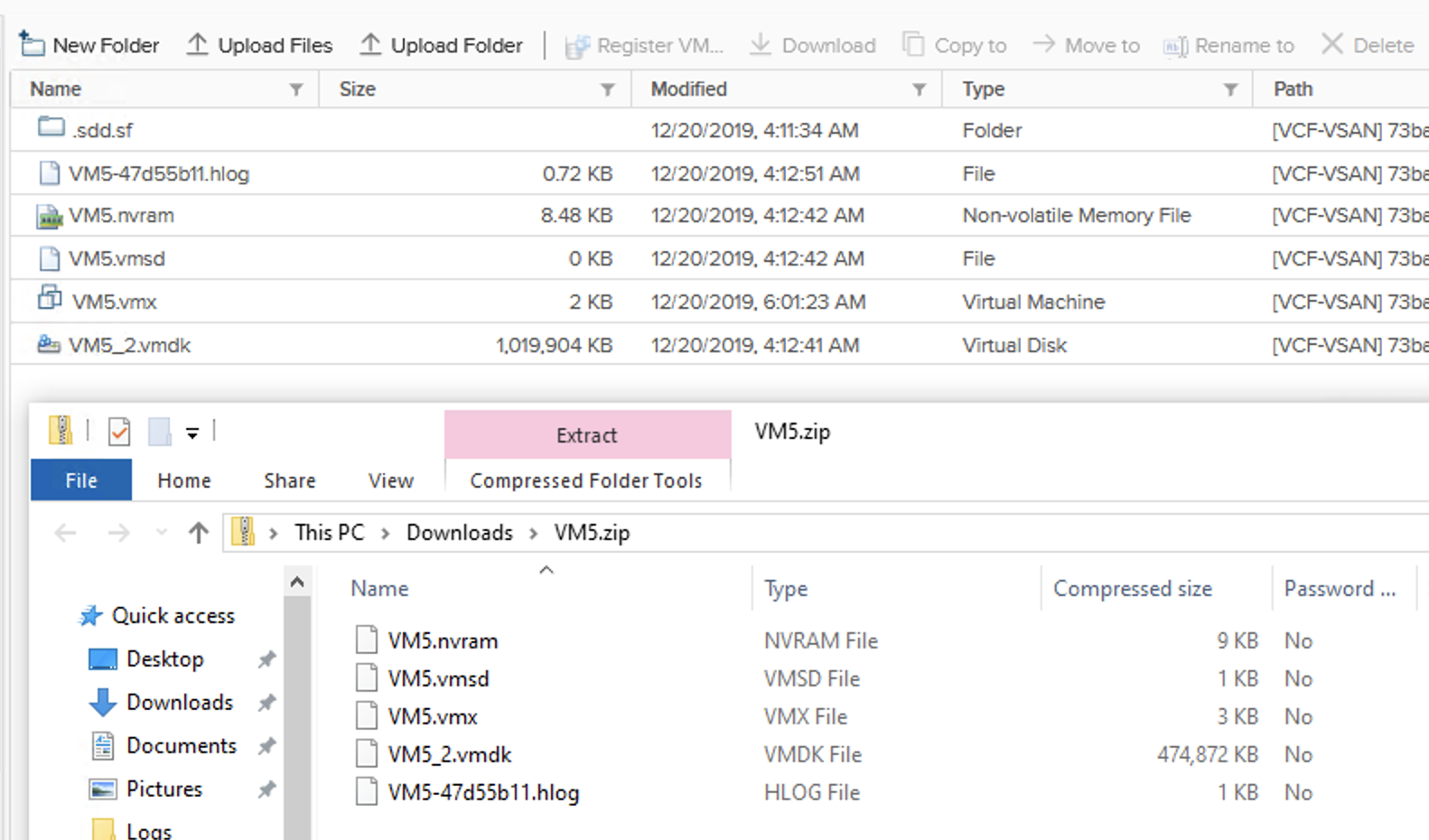
We can also add capacity disks to our vSAN disk groups to get more free space.
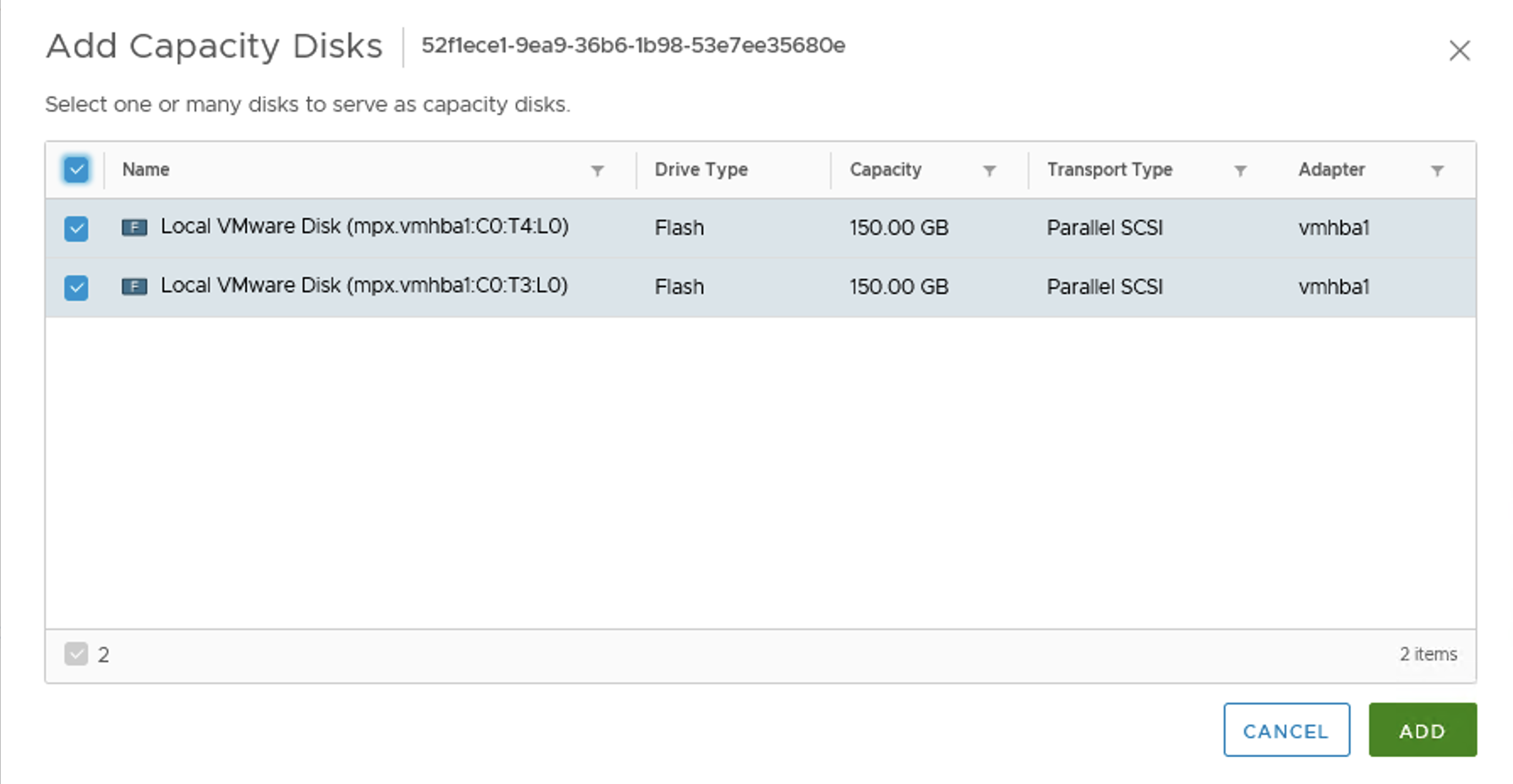
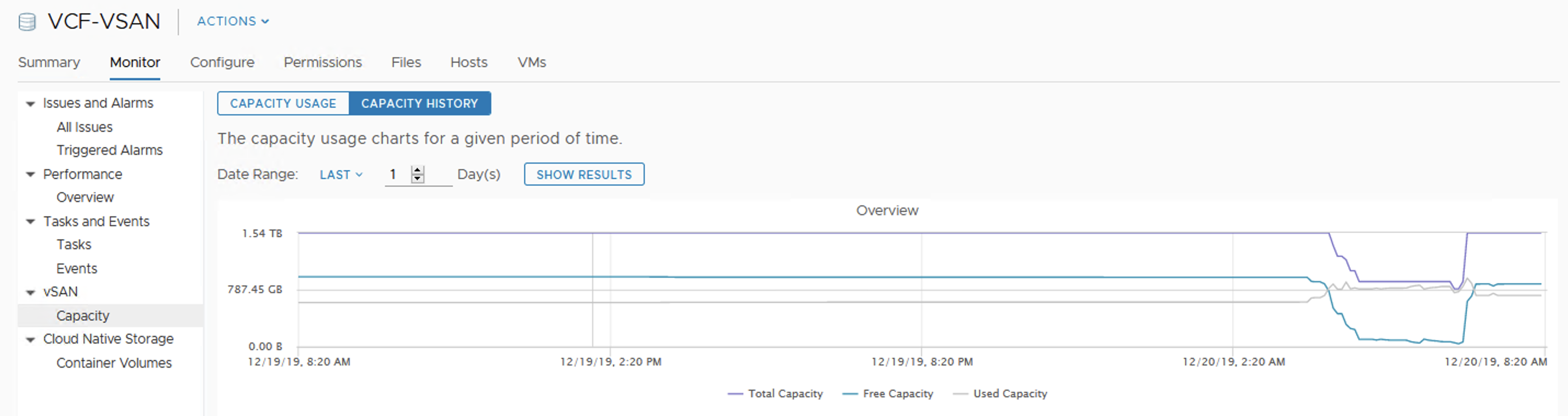
After we add disks the reaction of the cluster is immediate. We get more space, paused resync jobs start again, still in a controlled way, not all of them at once. Depending on our disk balance policy, rebalancing kicks in when certain threshold is exceeded.
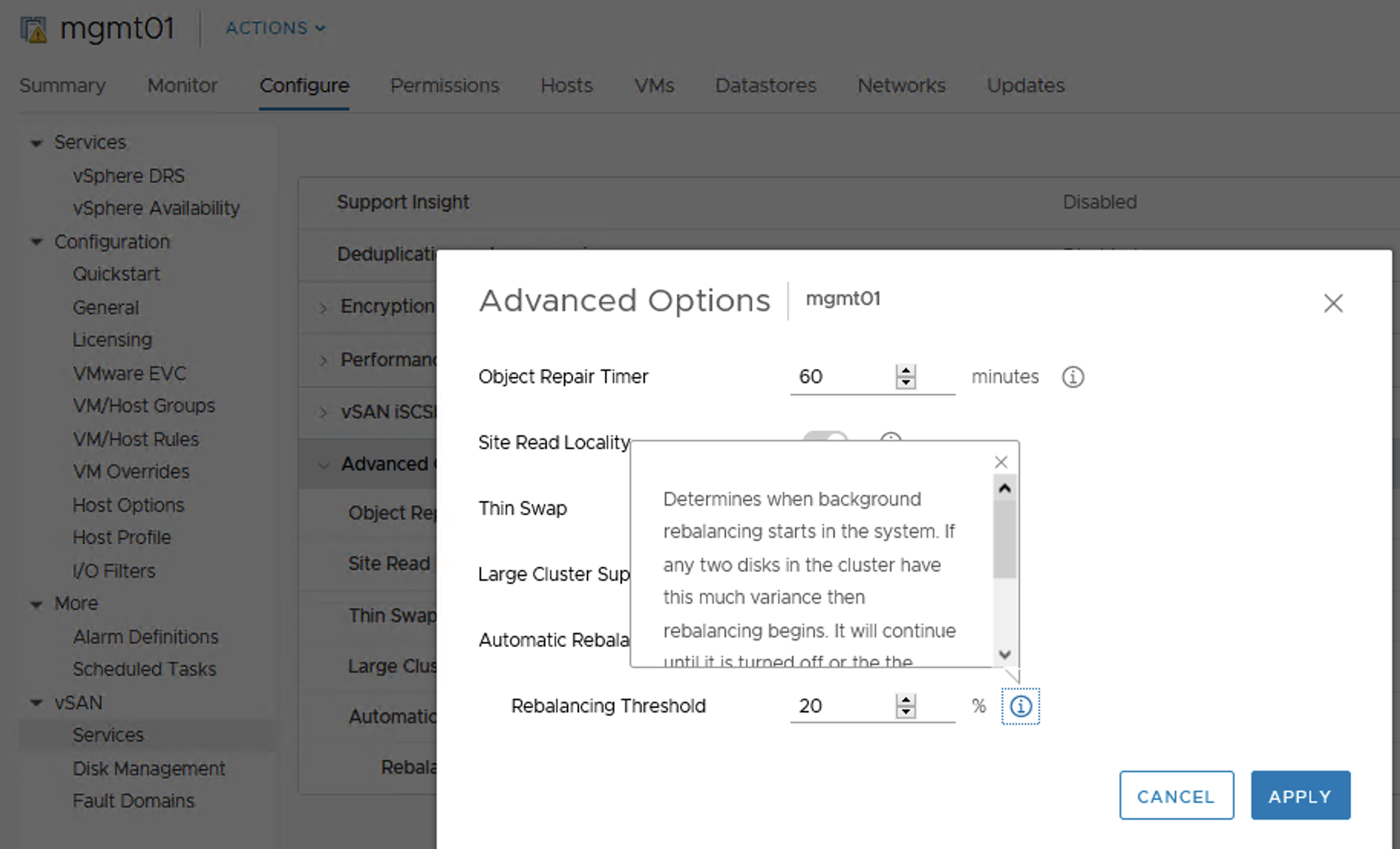
And finally everything is back to normal.
vRealize Log Insight survived my tests as well: