Recently I got a question about this particular case described in Stretched Cluster Desing Considerations :
When a host is disconnected or not responding, you cannot add or remove the witness host. This limitation ensures that vSAN collects enough information from all hosts before initiating reconfiguration operations.
It seems to be true and valid for vSAN 6.7. Is it a problem that we cannot change witness in this type of a corner case?
It would be a problem if we were not able to change witness when a host is in maintenance mode meaning that it would not be possible to replace a witness during an upgrade or a planned reboot. But we CAN change a witness in such a situation.
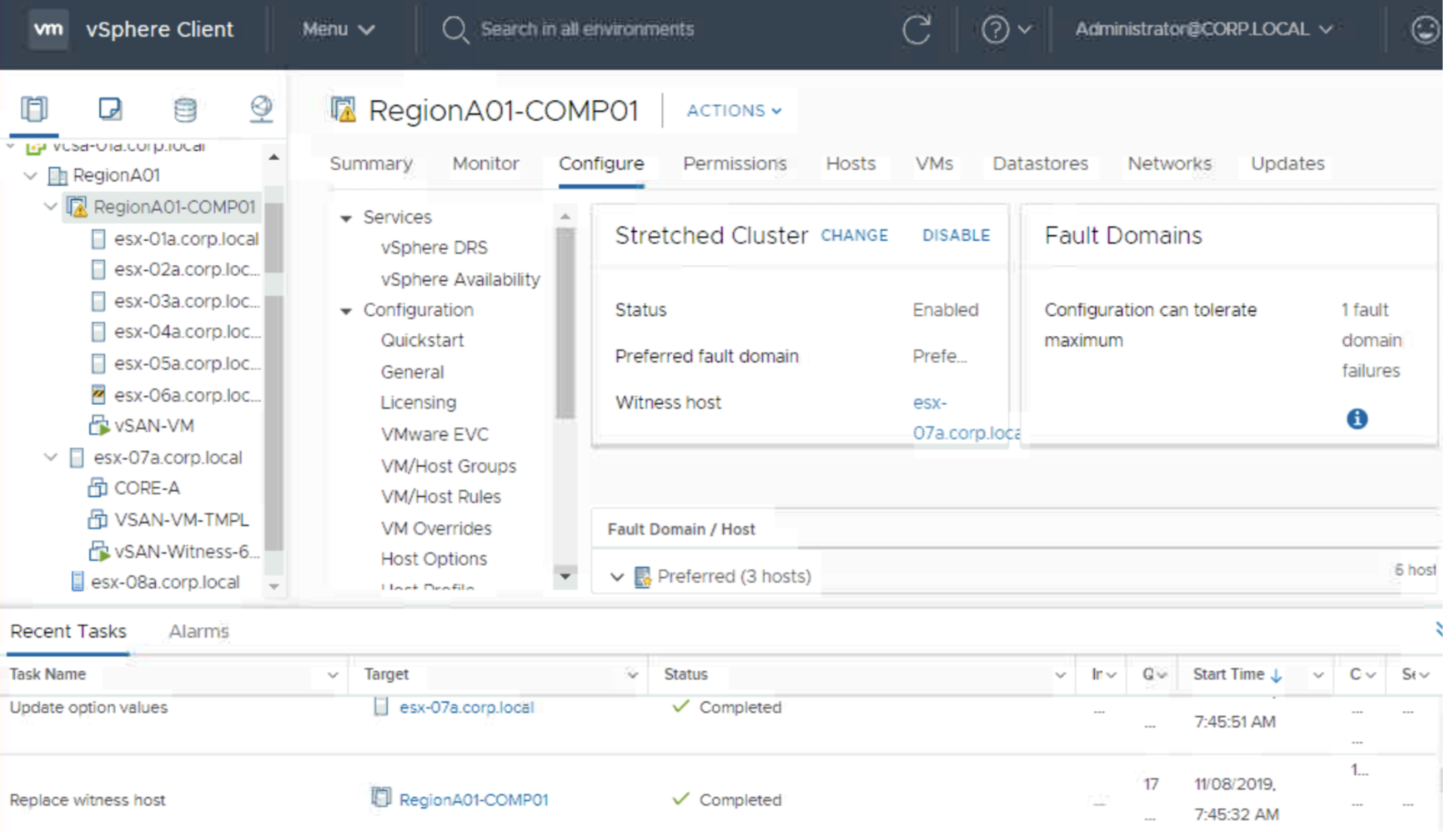
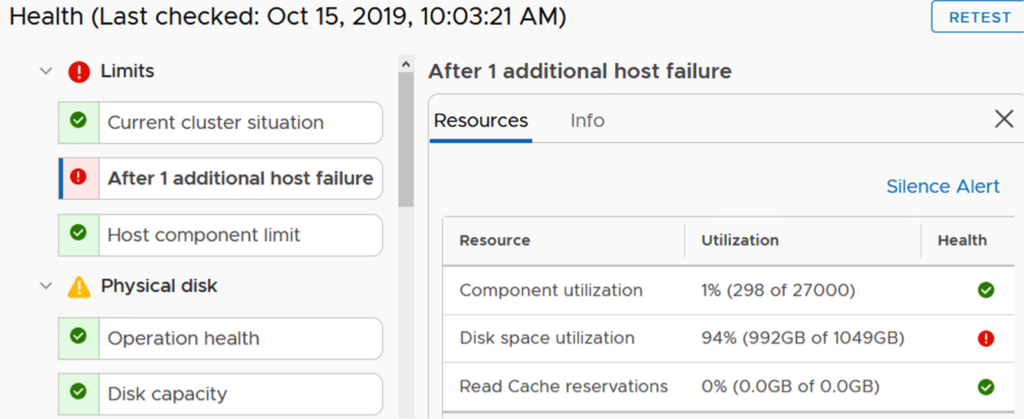
Let’s check what will happen if a host disconnects.
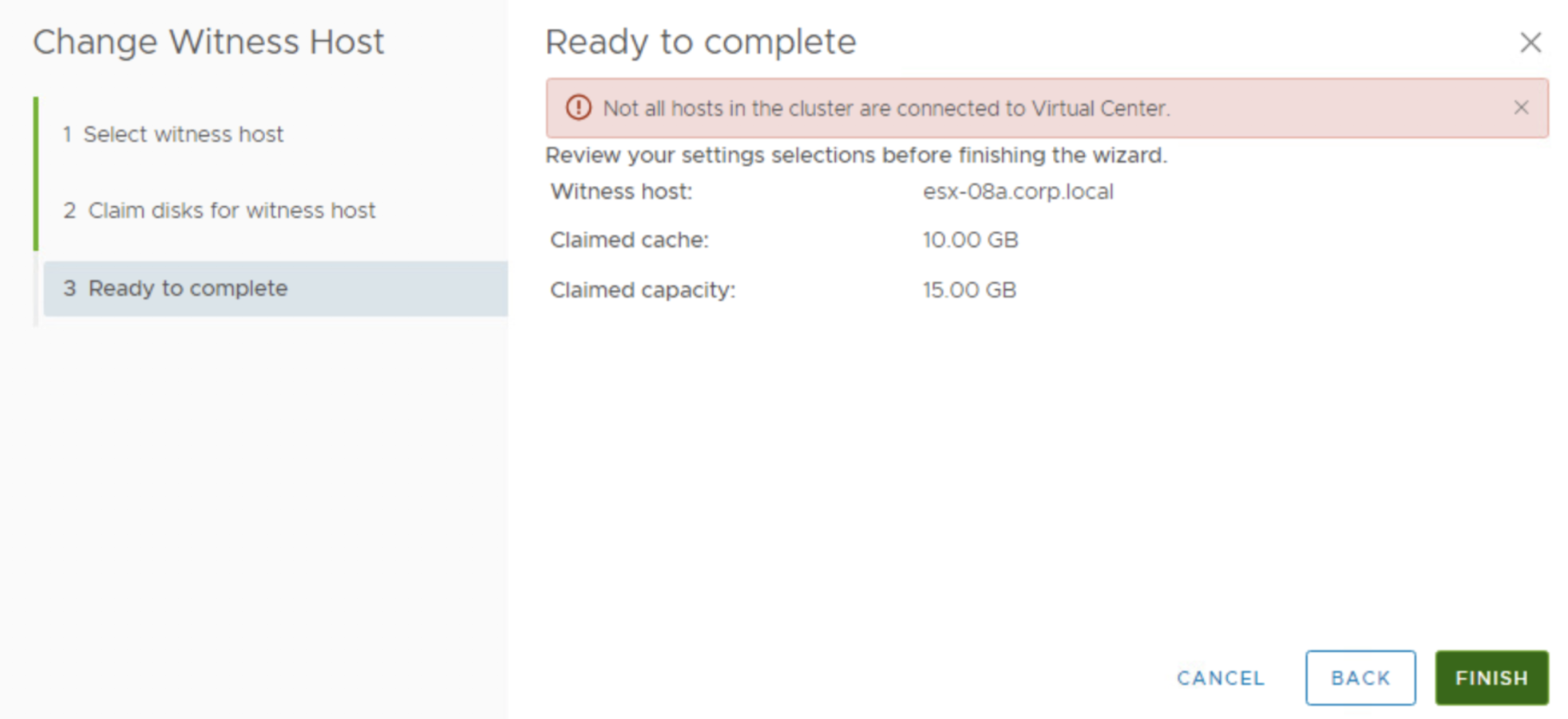

This is exactly the case described in documentation and confirms we need to have all the hosts connected to vCenter to be able to replace a witness.
Is there a workaround for a failed host scenario? Sure. We can always disconnect it and remove from the vSAN cluster and then change our witness. If a host is not available, vSAN will rebuild data on some other host anyway (if we have enough hosts), so this should not be a problem.
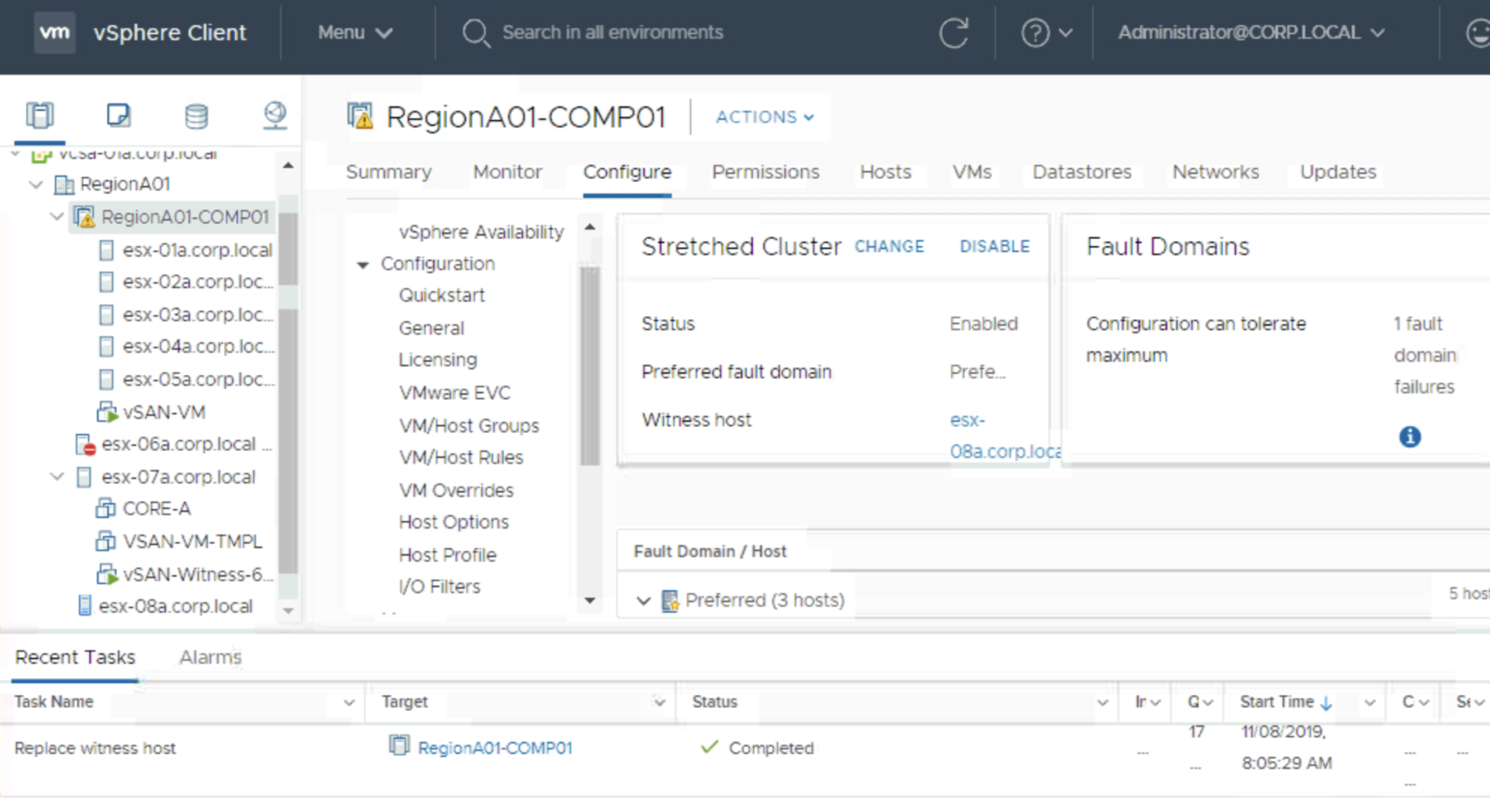
I have no idea why anyone would want to change witness exactly at the same time when a host is not responding. I hope to find an answer someday.