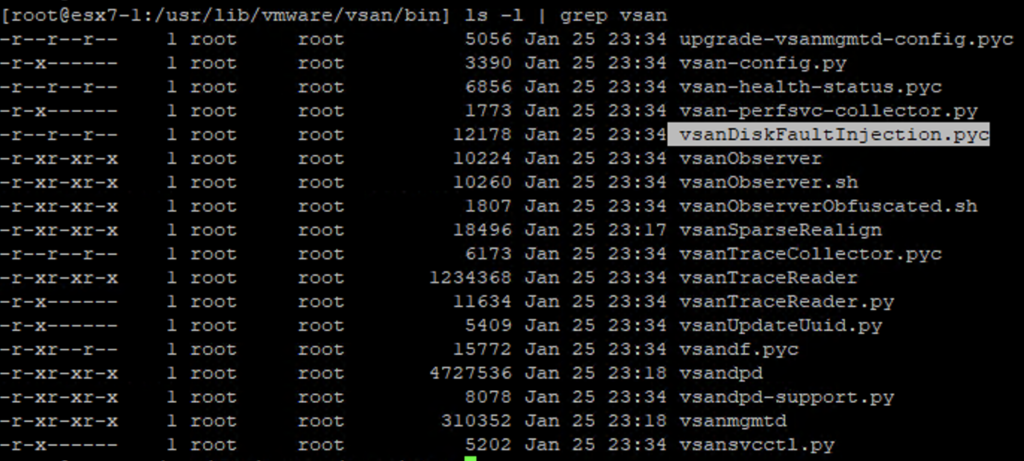
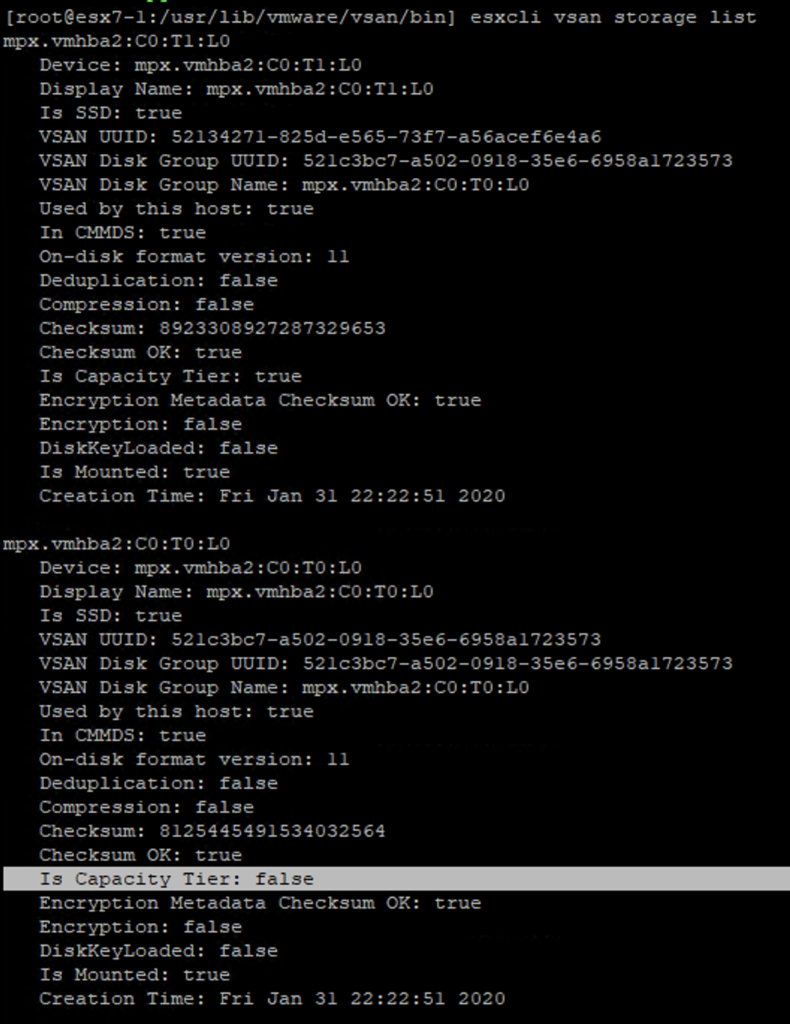
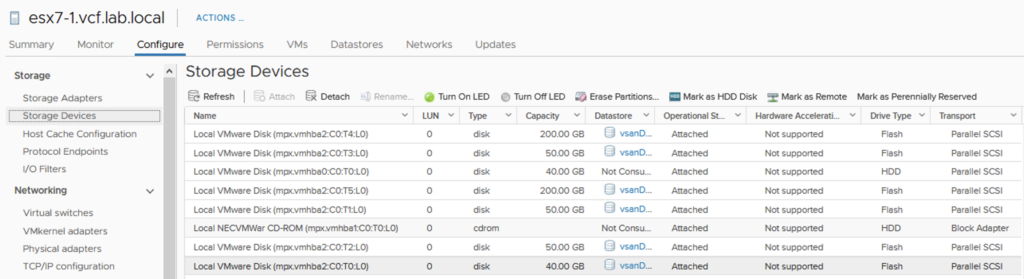
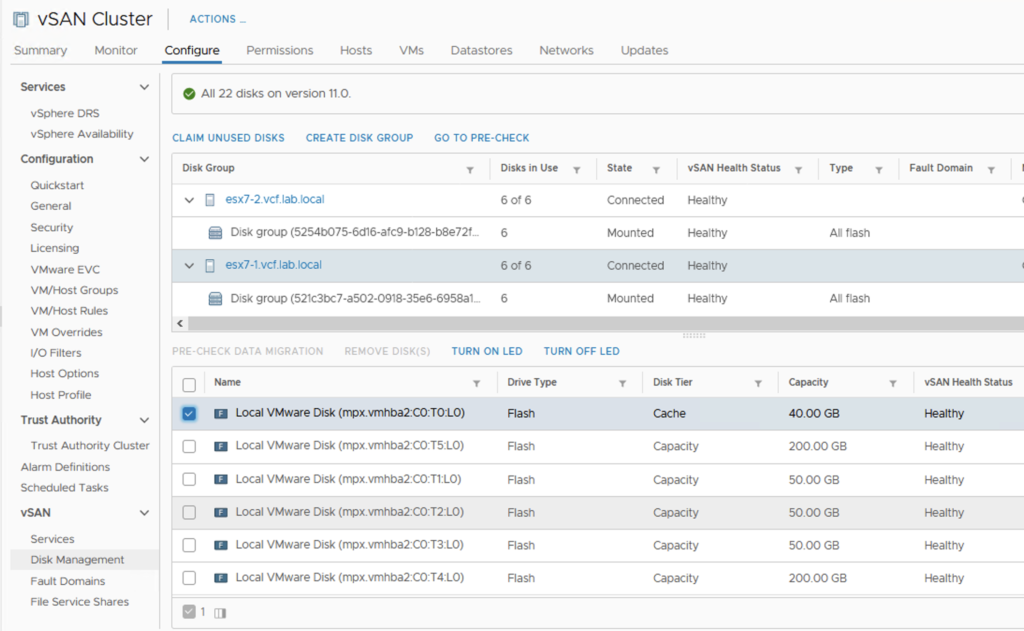
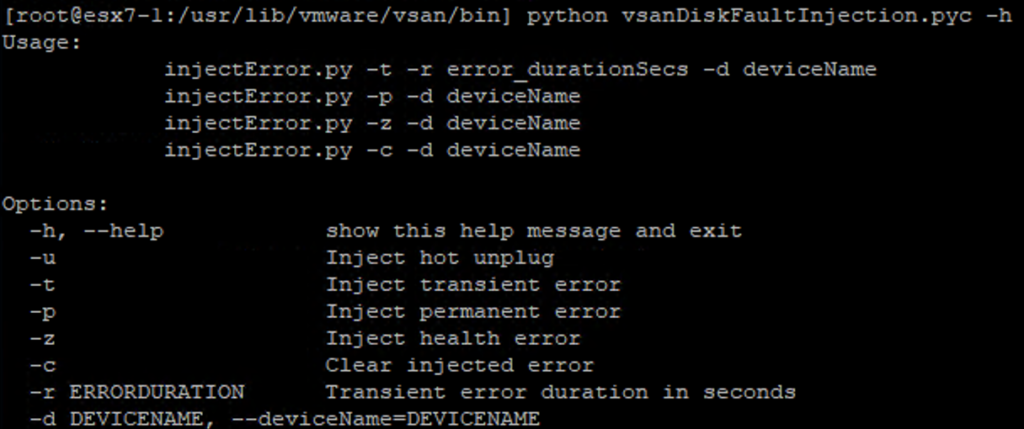
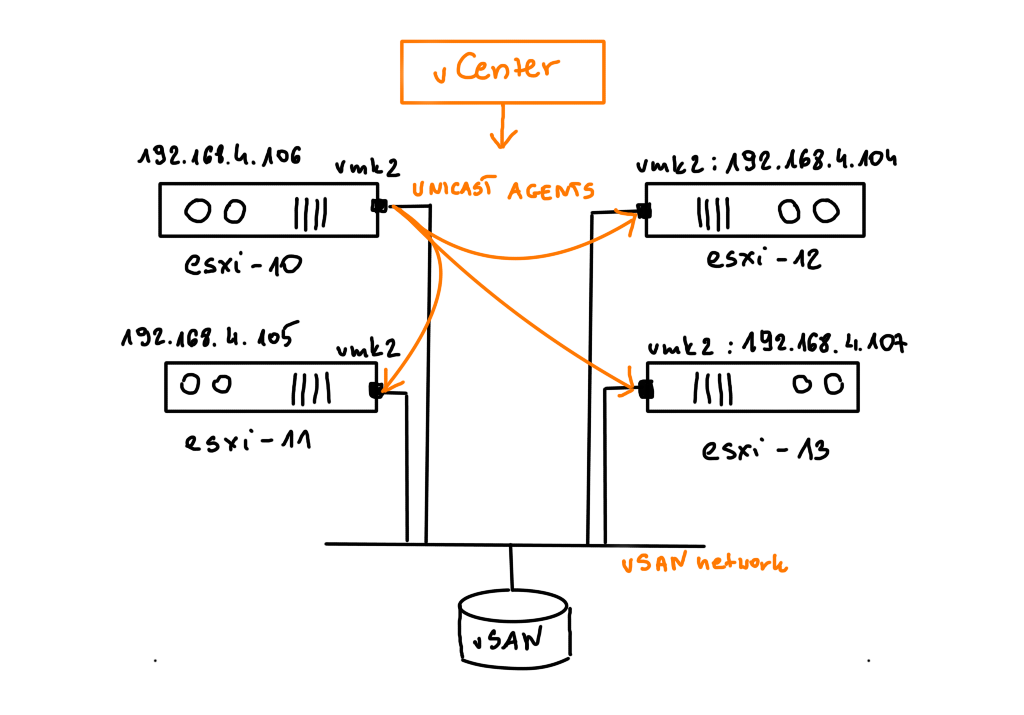
Some time ago I had a booth duty during a conference. My task was to present VxRail demo. If you are familiar with it, you know that after successful installation of the whole VMware stack, you get the Hooray page.
And vSAN magic was so strong that event Geralt of Rivia couldn’t resist it. And if you are familiar with The Witcher you also know he was generally immune to magic 😉

During Proof of Concept tests, when we run various complex failure scenarios, we might be lucky to see some of the vSAN magic too…. 😉
For me Intelligent Rebuilds are pure magic. I really like the smart way vSAN handles resync, always trying to rebuild as little as possible. Imagine we have a disk group failure in a host. After Object Repair Time is up, vSAN starts to rebuild the components on other hosts. Do you know what happens when a failed disk group comes back in the middle of this process? vSAN calculates what will be more sufficient – updating existing components or building new ones.
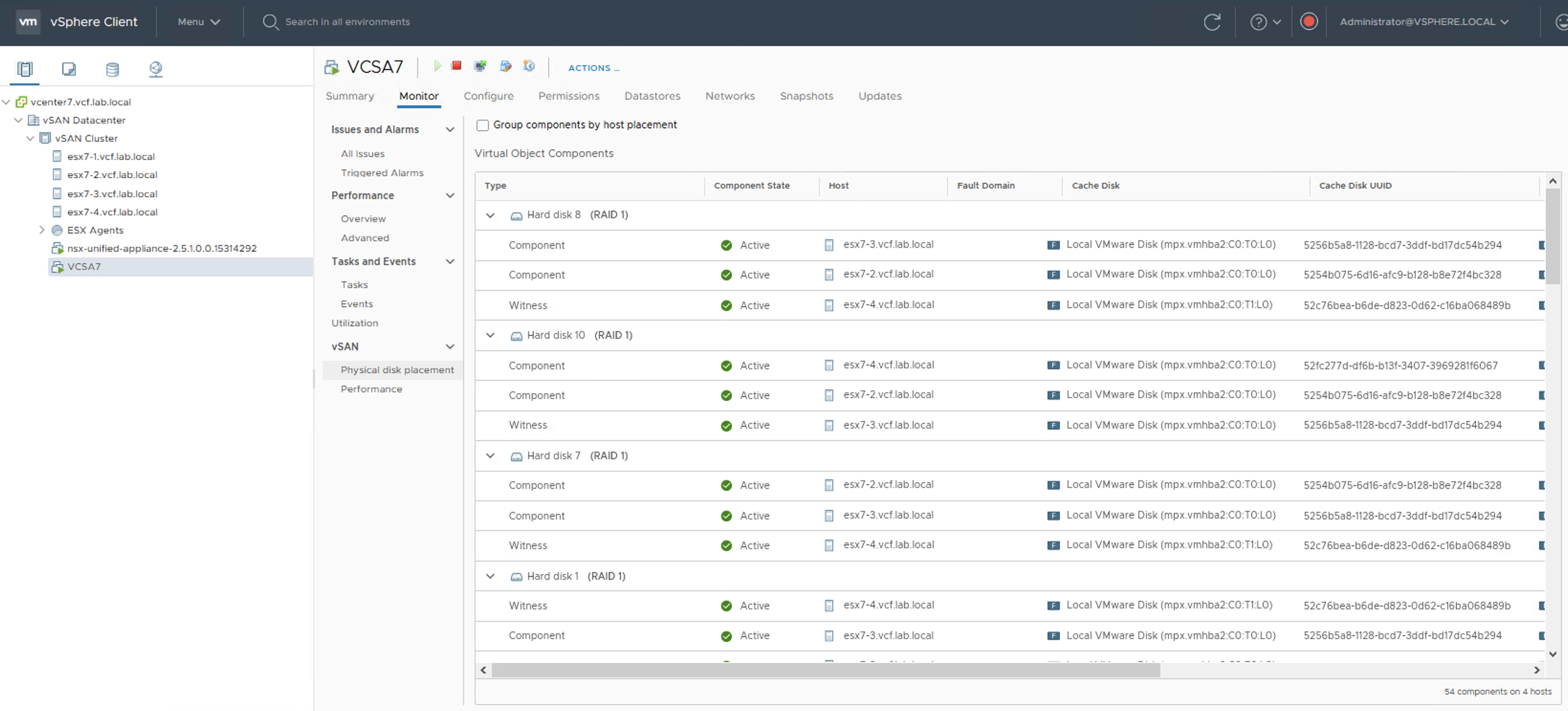
In the example below I have a vSAN cluster that consists of 4 hosts. Physical disk placement shows the components of the VMDK objects and all objects are ok.
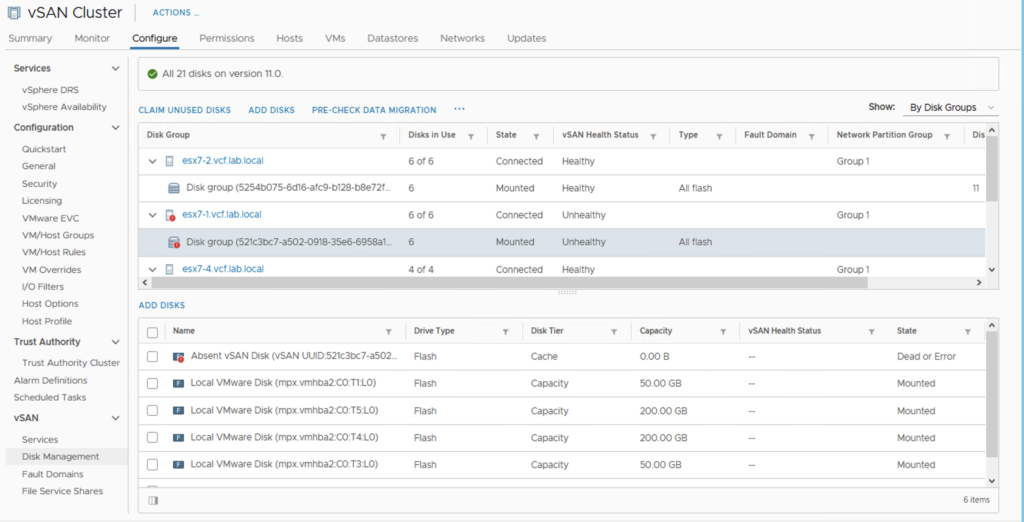
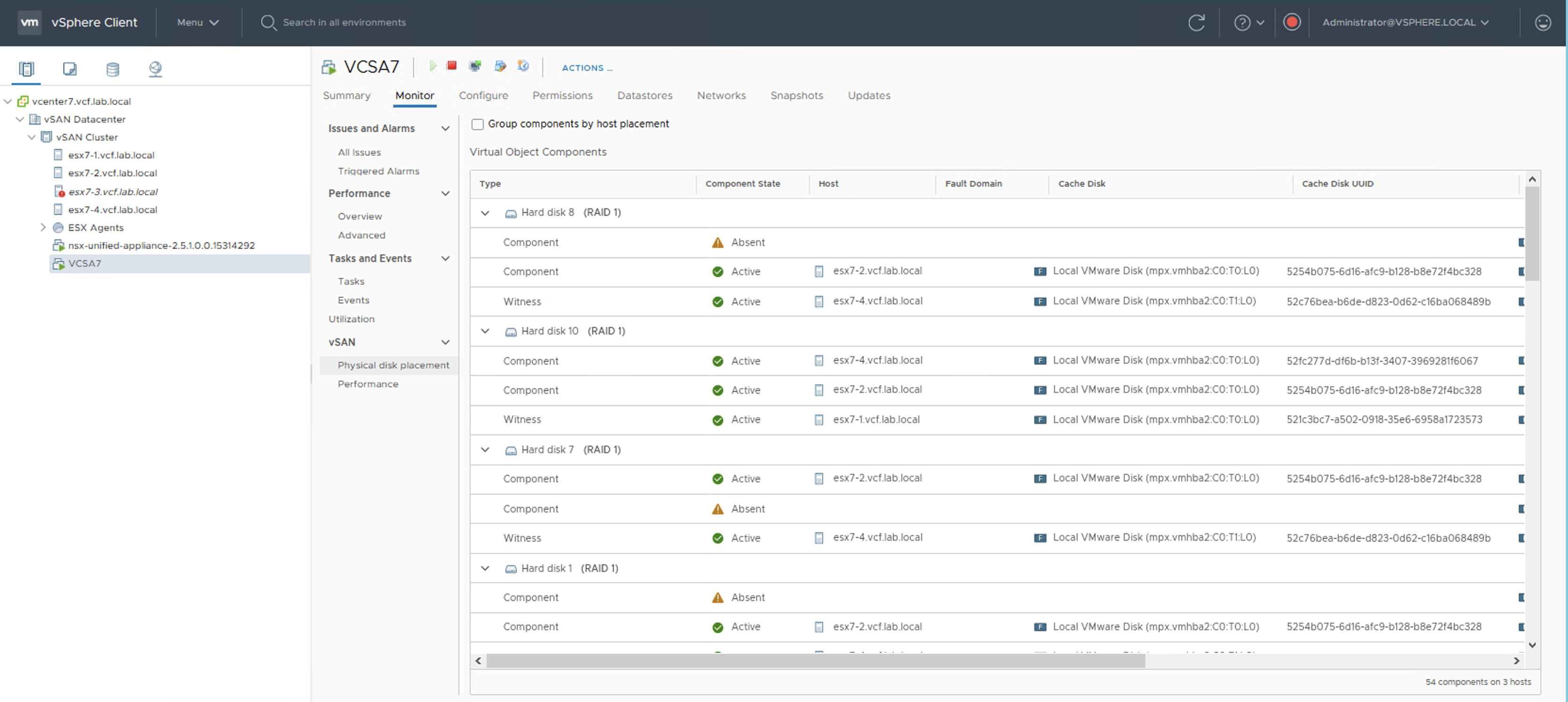
When I introduce a disk group failure on the host number 3 (esx7-3), disk placement reports that some components are absent but objects are still available, because those VMDKs have FTT-1 mirror policy (two copies and a witness).
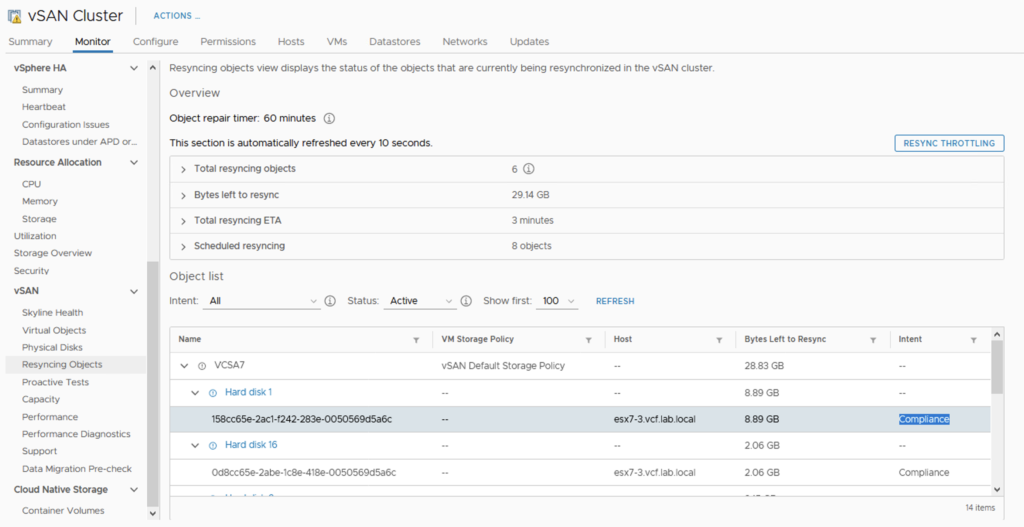
When the rebuild process kicks in, we can observe how vSAN resynchronizes objects:
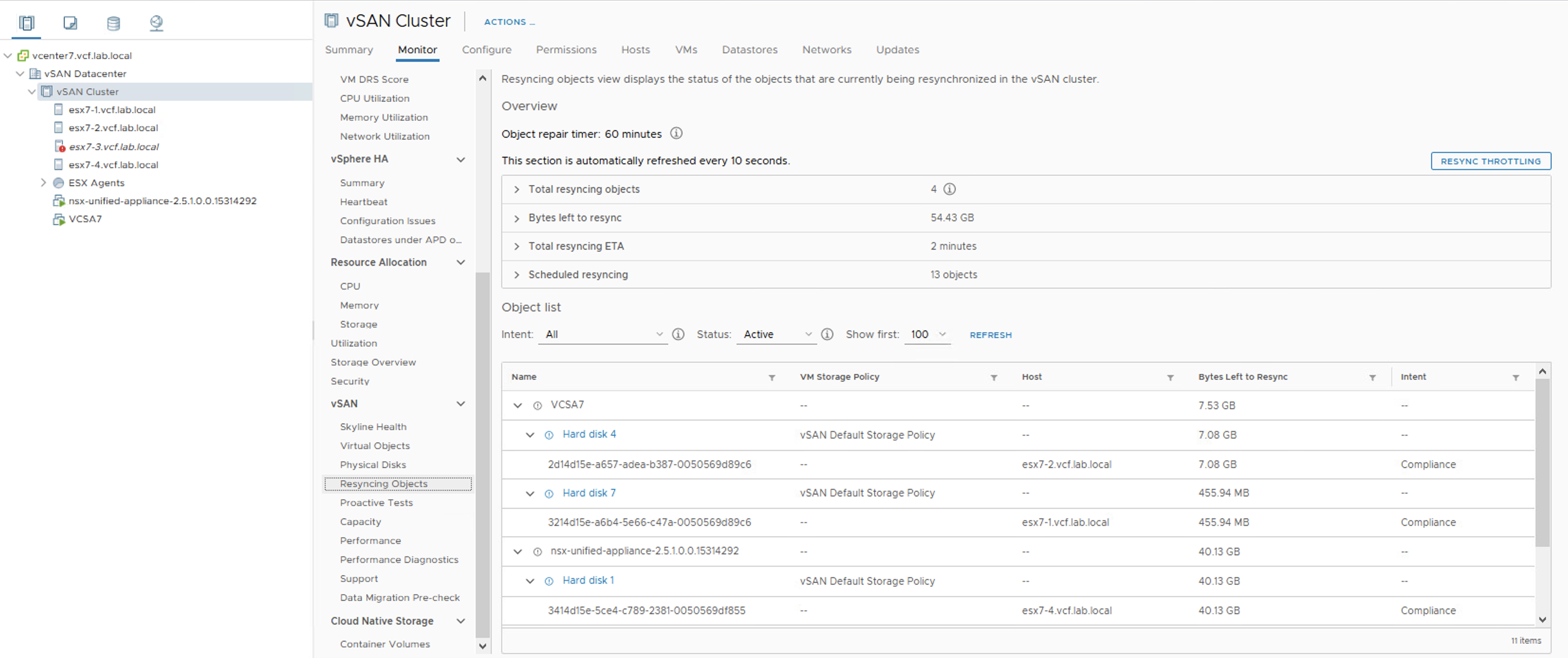
In the meantime I put the disk group of the esx7-3 host back in. And here it is – for a brief second we can see two components in the Resync view. One is a new one on esx7-1 that still has 11.07 GB to resync and the second is an old one on esx7-3 that has only 262.19 MB of data to resync.

A couple of seconds later, resync process ends because vSAN chooses to resync an old object to make the process more efficient.
Ok, ok, this is not magic but it is awesome anyway 😉