The High Availability feature for HCX Network Extension appliances was introduced in the version 4.3. This was a big deal, because if someone needed HA for their appliances that extend L2 networks (as this is a basic requirement for the resiliency) to the cloud and wanted to use VMware’s stack in particular, they had to deploy a pair of NSX-T standalone Edges on-prem leveraging NSX-T on the cloud side and setup a L2VPN.
VMware documentation mentions the following important prerequisites to consider before deploying HCX NE HA:
Network Extension HA requires the HCX Enterprise license.Network Extension High Availability protects against one Network Extension appliance failure in a HA group.Network Extension HA operates without preemption, with no automatic failback of an appliance pair to the Active role.Network Extension HA Standby appliances are assigned IP addresses from the Network Profile IP pool.The Network Extension appliances selected for HA activation must have no networks extended over them.
Also an interesting thing about NE in HA mode is the upgrade process:
In-Service upgrade is not available for Network Extension High Availability (HA) groups. HA groups use the failover process to complete the upgrade. In this case, the Standby pair is upgraded first. After the Standby upgrade finishes, a switchover occurs and the Standby pair takes on the Active role. At that point, the previously Active pair is upgraded and takes on the Standby role.
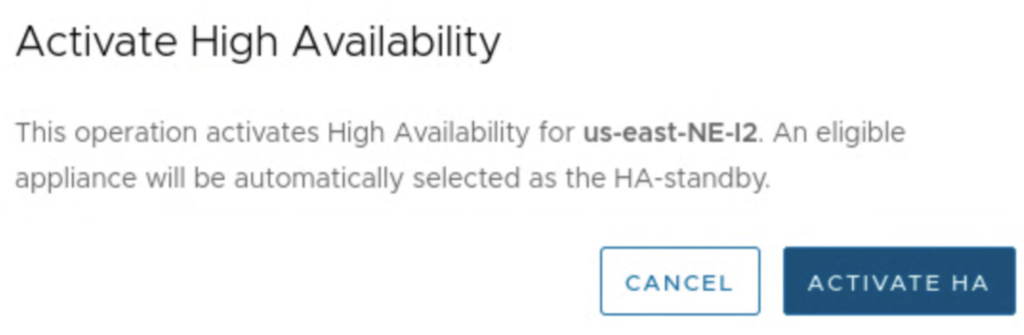
Let’s take a look at this new feature. In the HCX UI 4.3+, in the Interconnect -> Service Mesh -> View Appliances view, there is a new option called ACTIVATE HIGH AVAILABILITY.
First, you need to have a pair of deployed NE appliances, the option won’t work when there is no eligible partner for HA.
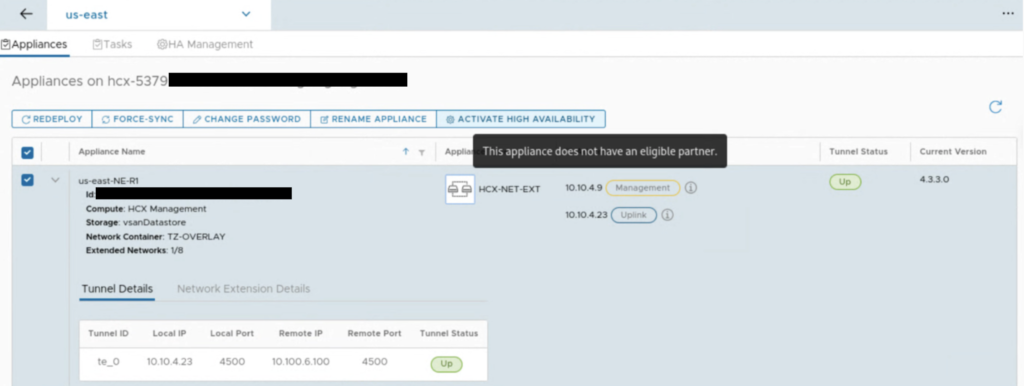
Also, system checks, if there are extended networks on an appliance that you select for HA.
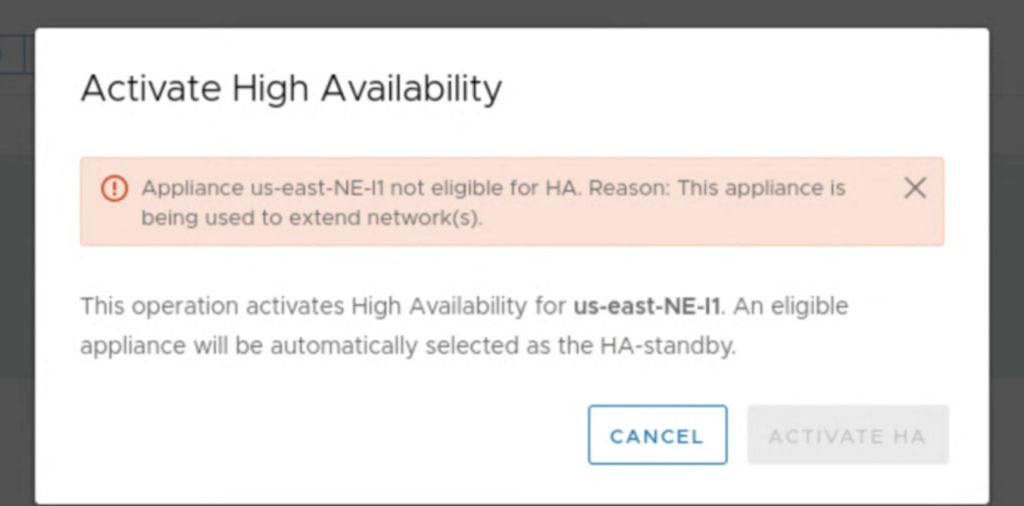
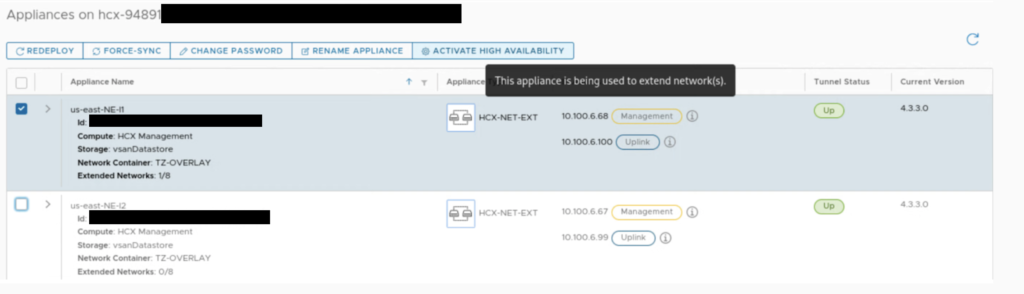
It can be a challenge to enable HA in an environment, where networks are already extended. In most cases this would require a downtime because we would have to unextend existing networks on NE appliances for the time of the HA configuration.
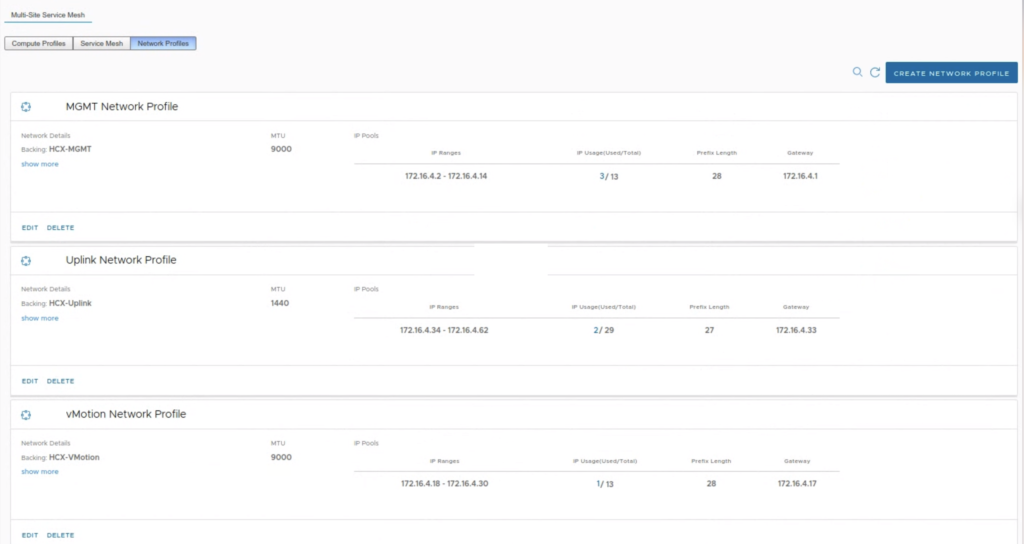
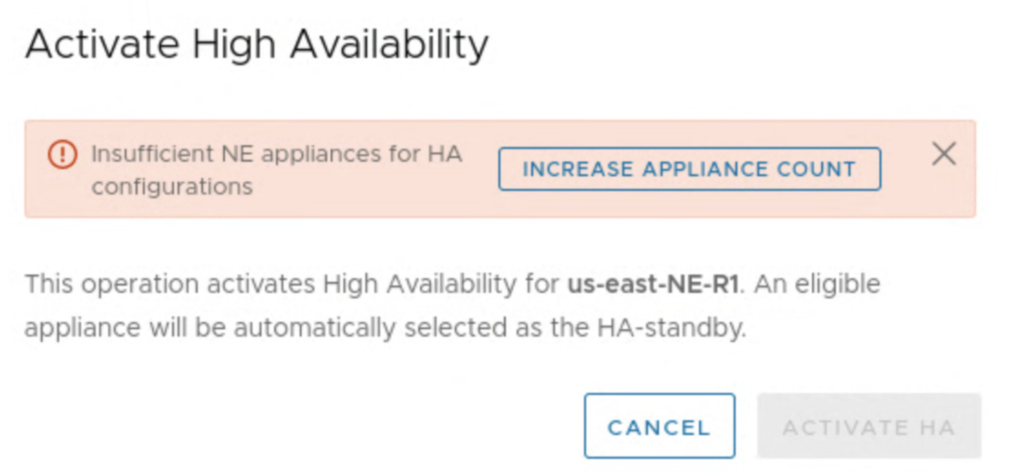
The system also checks if there are eligible NE appliances to activate HA feature and we get a button that is a shortcut to edit a Service Mesh and add more appliances. It can also be a challenge, if we don’t have a sufficient number of free IPs in our Network Profile’s IP pool. For 2 additional NE appliances on-prem and at the cloud side, we need one management IP and one uplink IP for each of them.
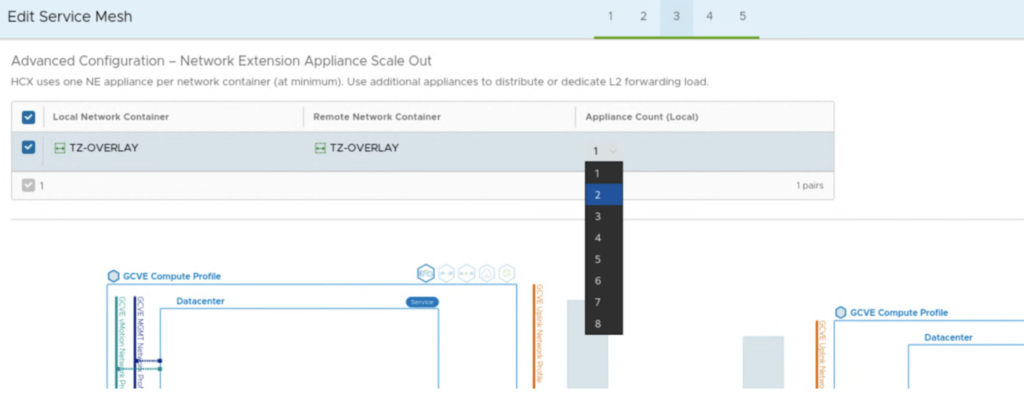
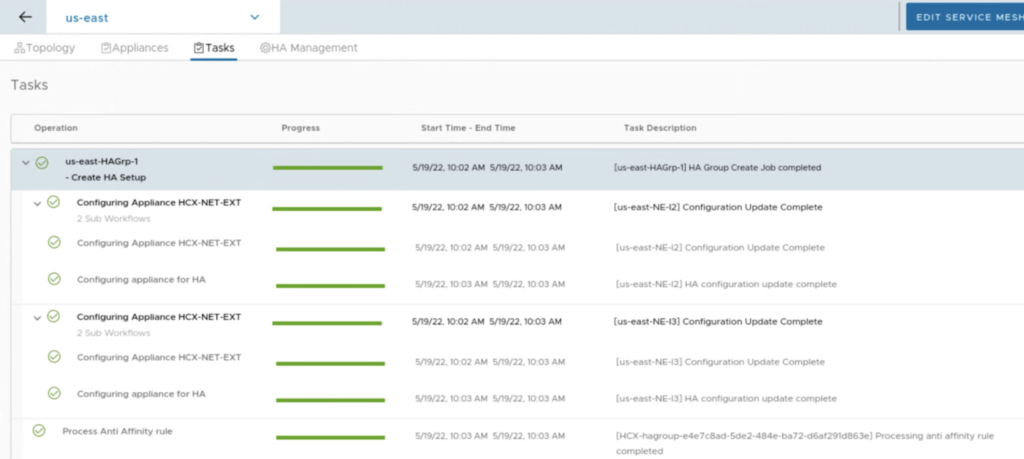
Once appliances are deployed, you only need to press a button Activate HA. Everything is configured for us, like in vSphere HA. New HA appliances create a HA group with a specific uuid.
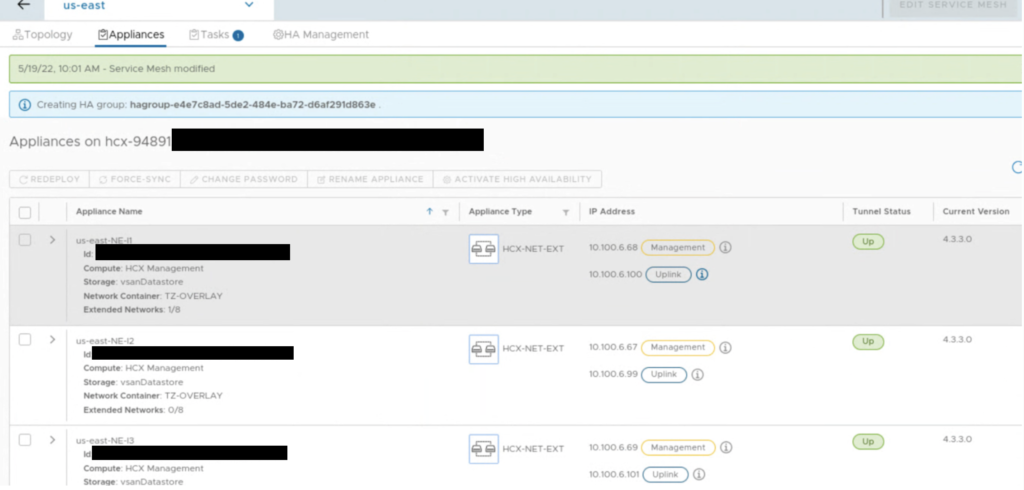
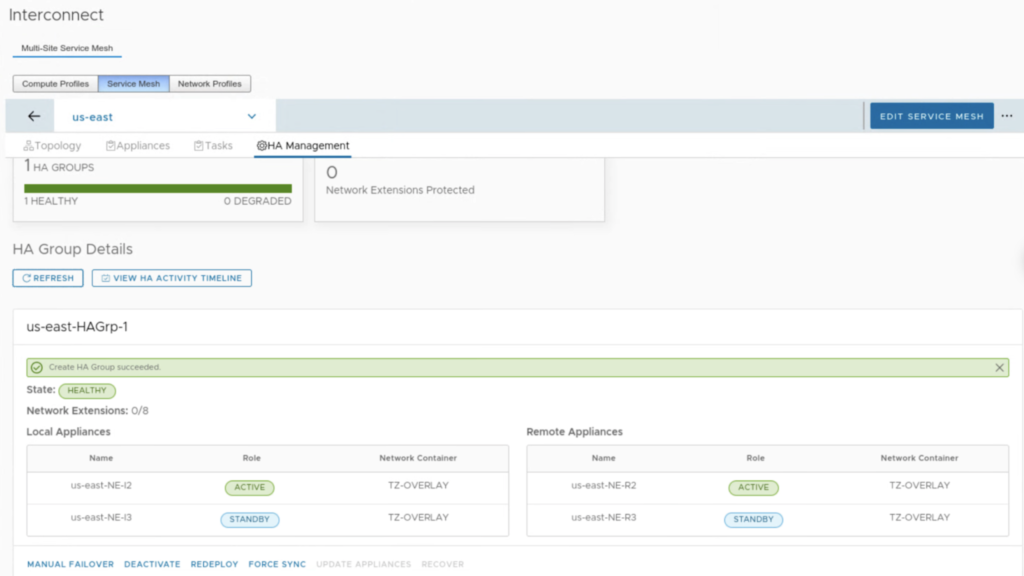
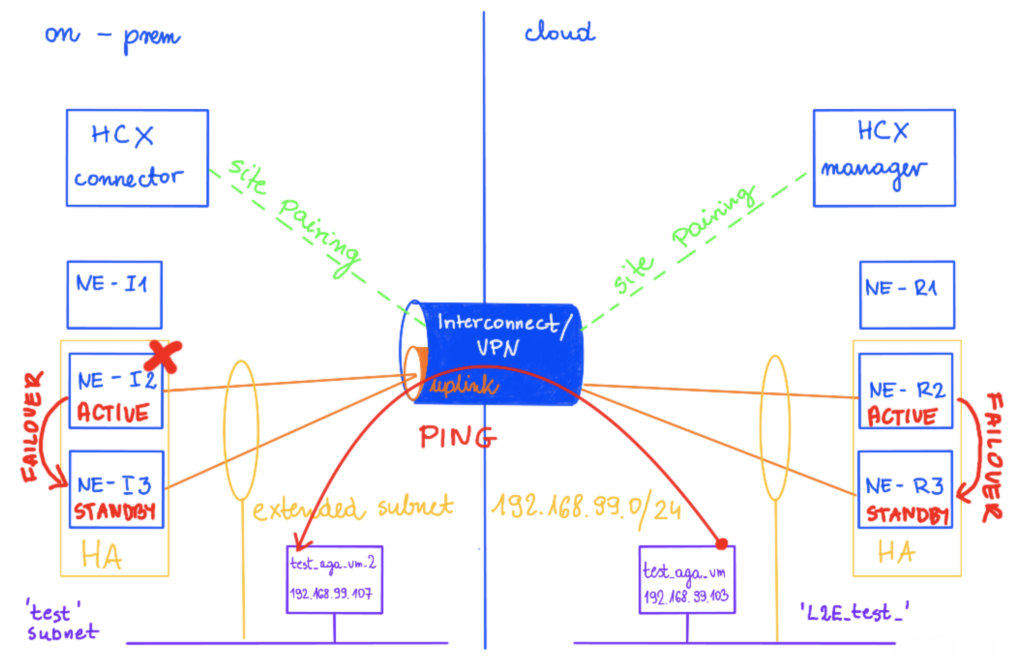
When HA is enabled, we can monitor its health in the HA Management tab. In the example below, we have 2 pairs: us-east-NE-I2 (on-prem) with us-east-NE-R2 (the cloud side) and us-east-NE-I3 (on-prem) with us-east-NE-R3 (the cloud side). Right after creation, the first pair is ACTIVE and the second is STANDBY.
Also in the Appliances view we can quickly check with NE appliance is ACTIVE and which one is STANDBY.
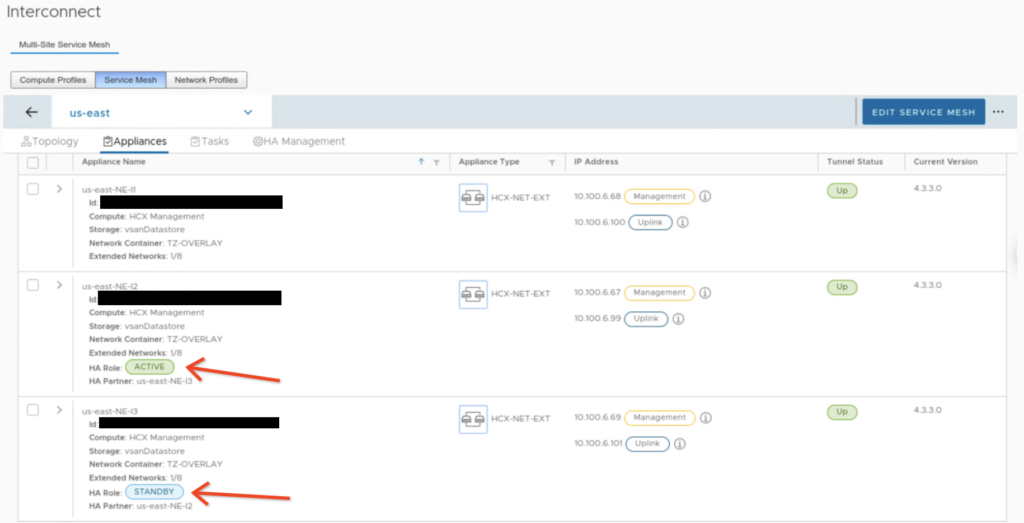
NE appliances with HA enabled can coexist with other NE appliances. This means we can still use single NE appliances for less critical workloads and HA groups only for selected networks.
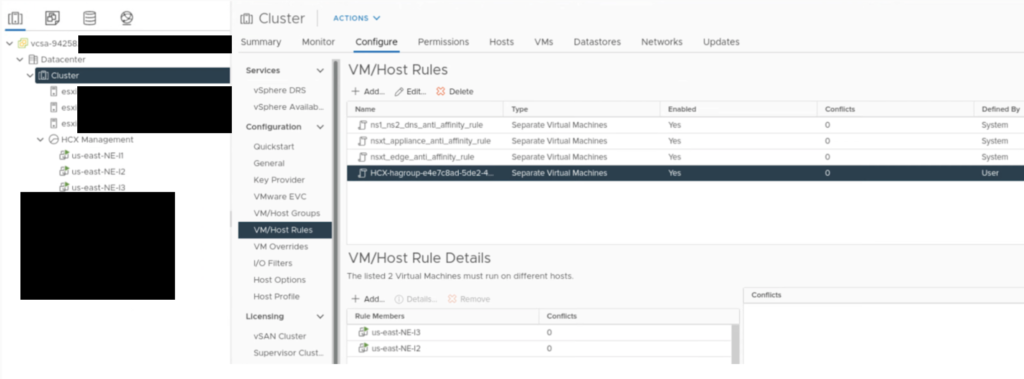
During a HA group creation, there is a VM/Host Rule created in a vCenter to make sure NE appliances in the same HA group won’t run on a same host.
After HA group is deployed, we can simulate a failure of one NE.
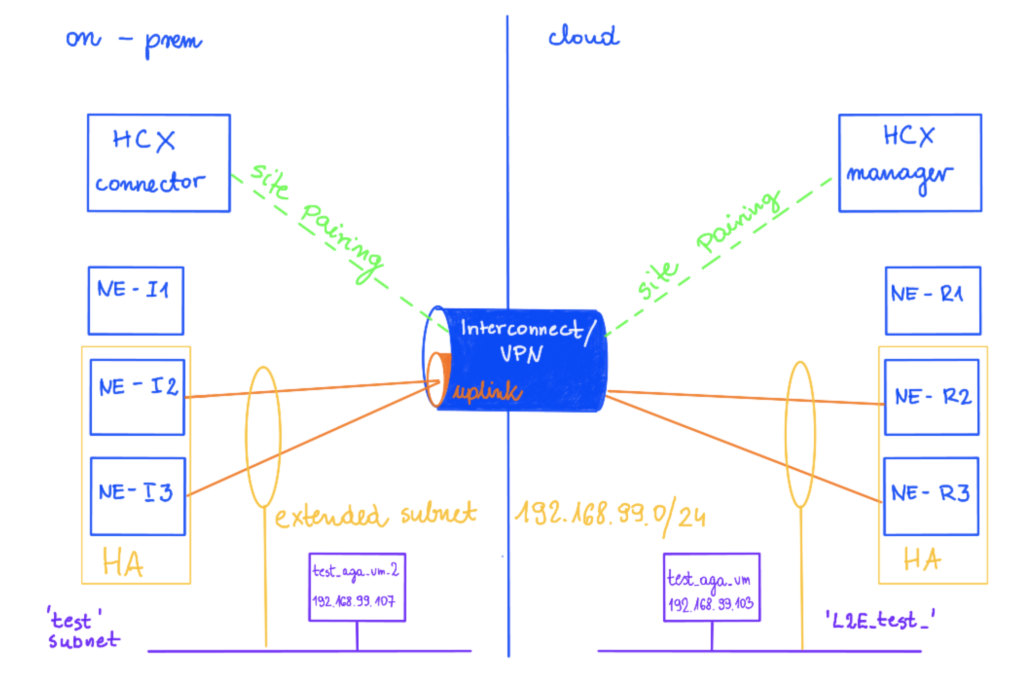
In this example I am using two sites, Sindey represents on-prem and Ashburn is my cloud side.

The network test 192.268.99.1/24 is extended on this new HA Group from on-prem (NE-I2 and NEI-3) to cloud (NE-R2 and NE-R3).
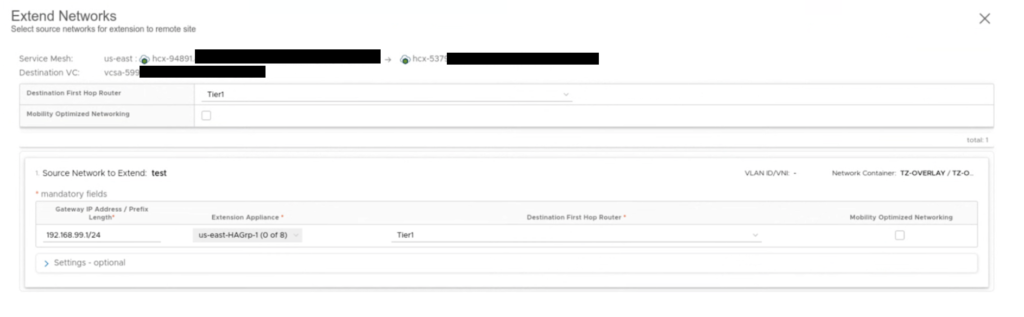
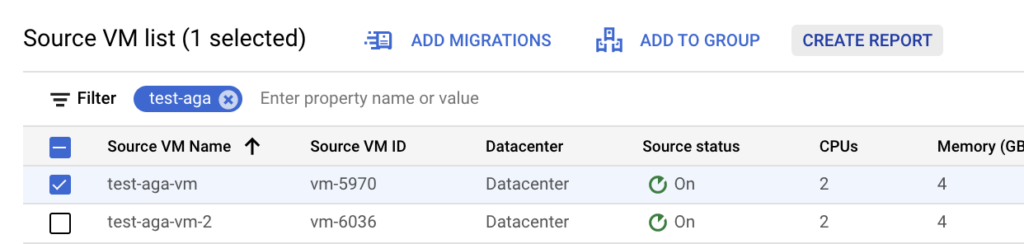
There is a vm test_aga_vm_2 (192.168.99.107) on-prem connected to the test subnet and on a cloud side, there is a vm test_aga_vm (192.168.99.103) on the extended network L2E_test. As VMs are at the opposite sides, we can have a ping running between them to test the connectivity during the NE failover.
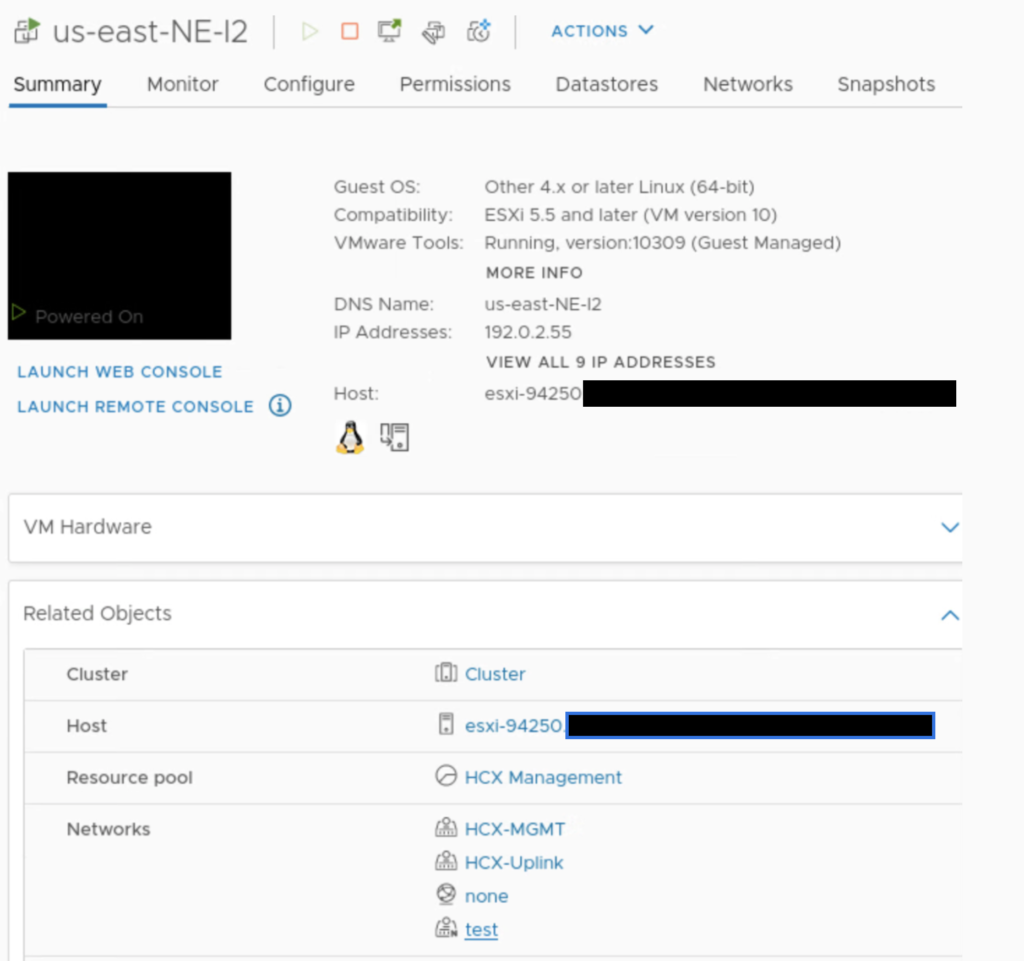
If you look closely at NE appliances, there is nothing specific to HA there, no specific HA subnet, only management, uplink and extended networks.
On the on-prem side, there is a test network attached to NE-I2, same for NE-I3.
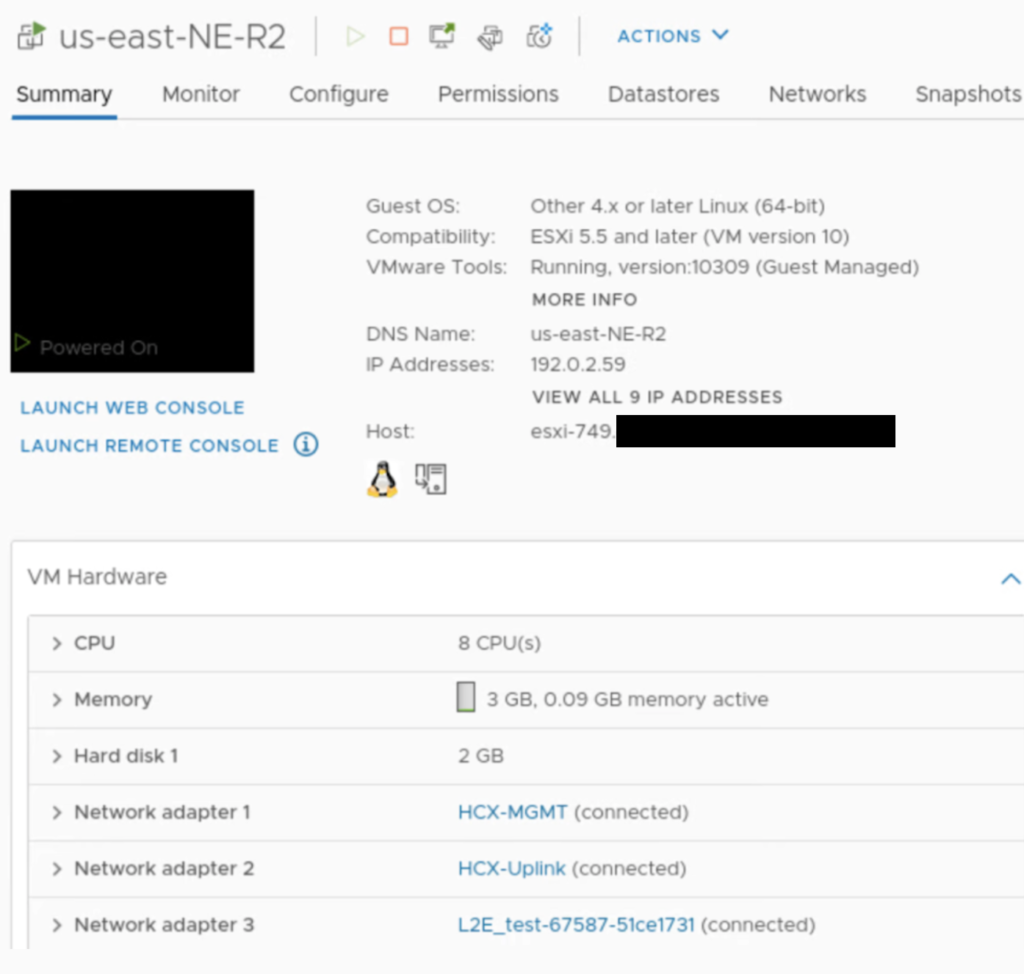
On the cloud side, there is a L2_test network attached to NE-R2, same for NE-R3.
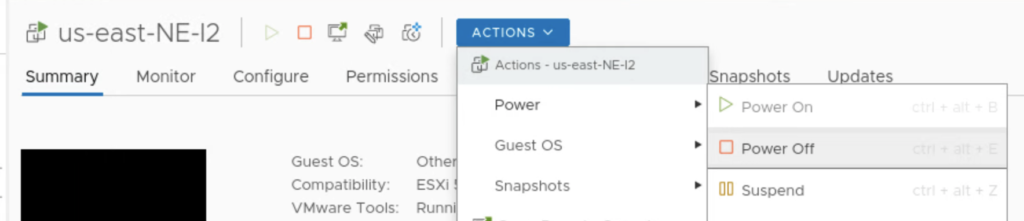
Now, to force a failover, I am shutting down an appliance on the on-prem: NE-I2.
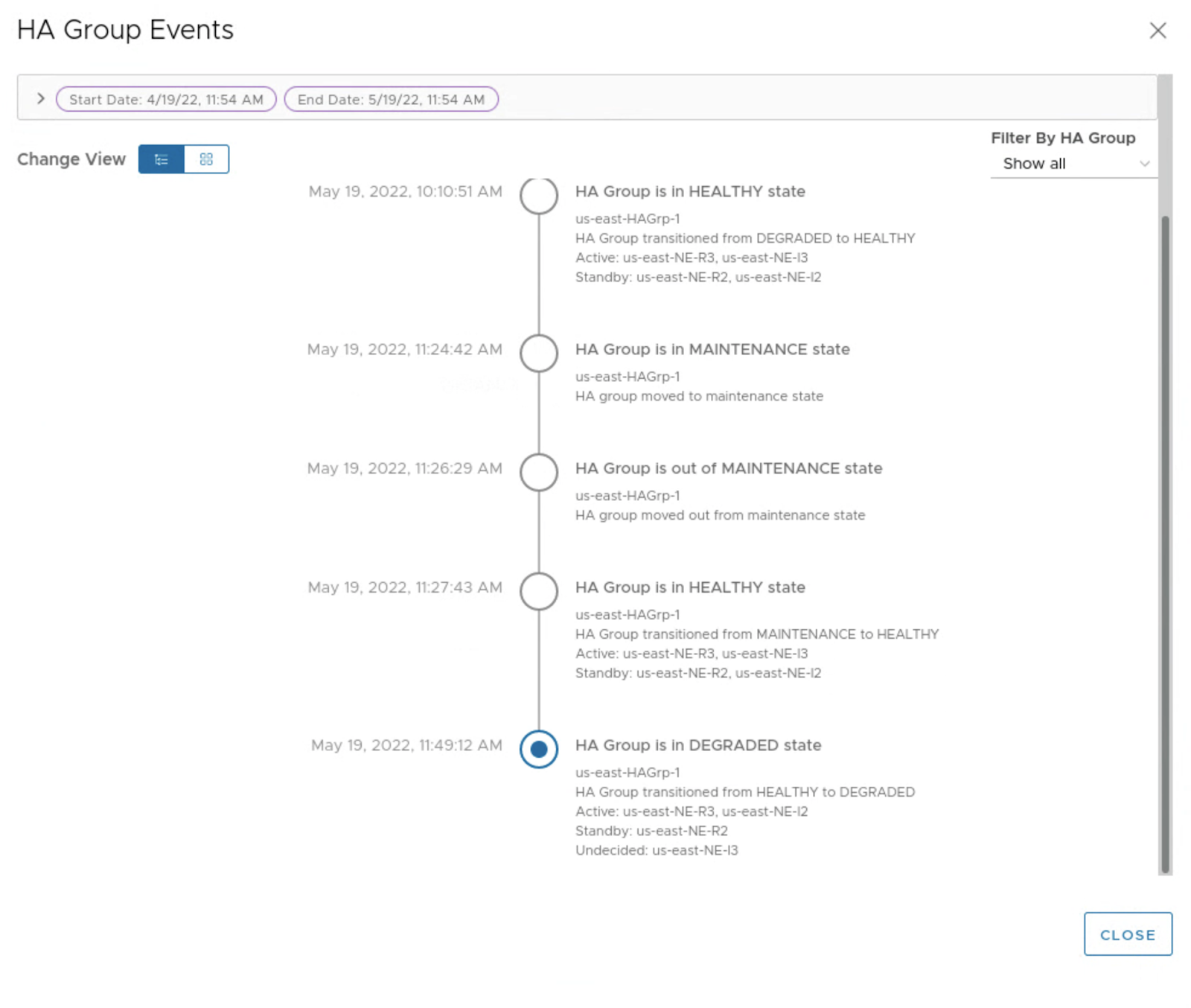
What happens next is there is a failover for the first pair of appliances: NE-I3 and NE-R3 become active. This is always a pair of appliances that changes the state, so in case NE-I2 is down, NE-R2 also fails over to NE-R3.
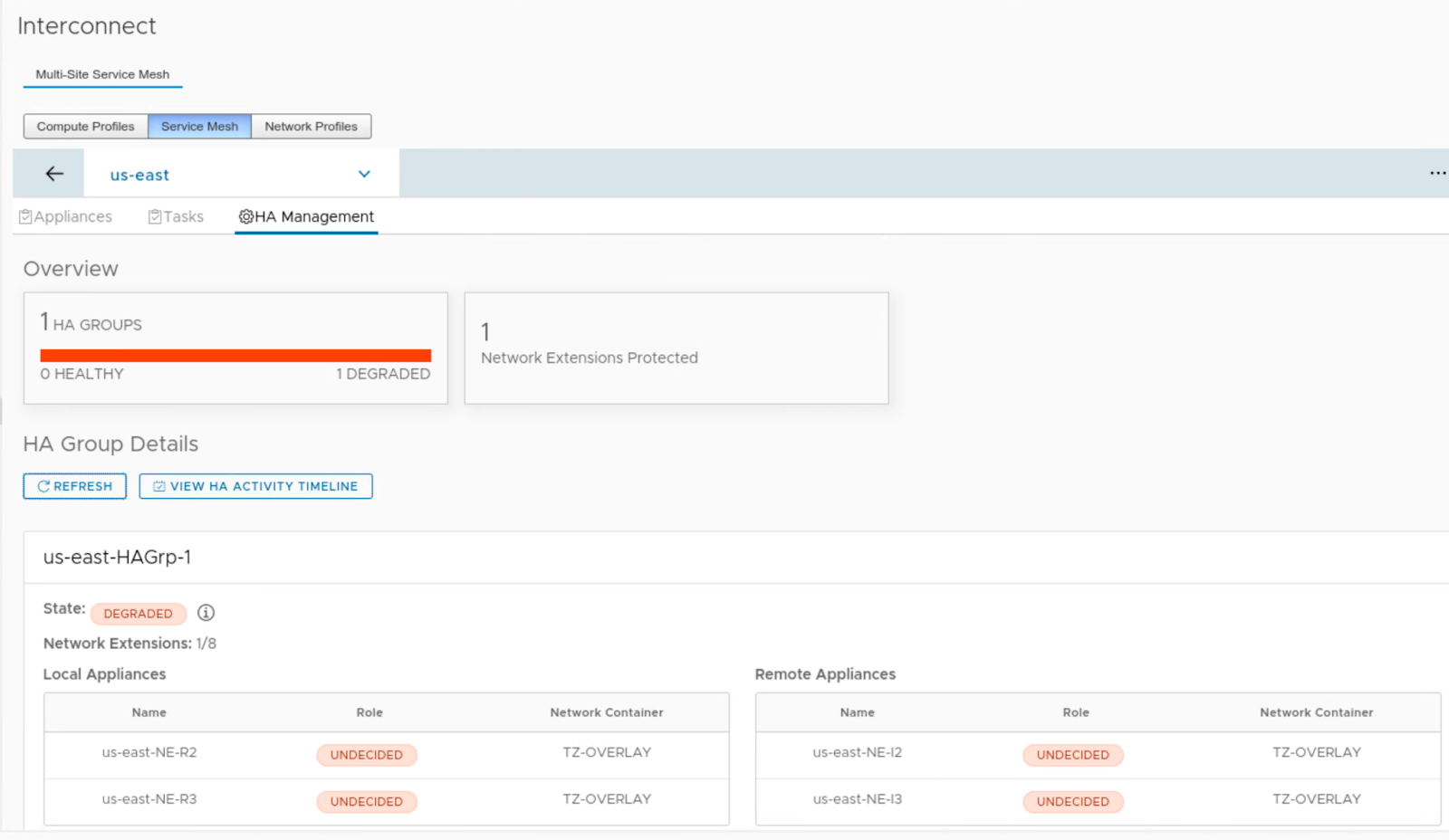
There is a small (as expected) packet loss observed and also it takes some time in the HA view in HCX UI to show the updated status of the appliances. The communication path between NE on-prem and NE on GCVE was restored and pings successful but the UI still showed a DEGREADED state for HA appliances for some time.
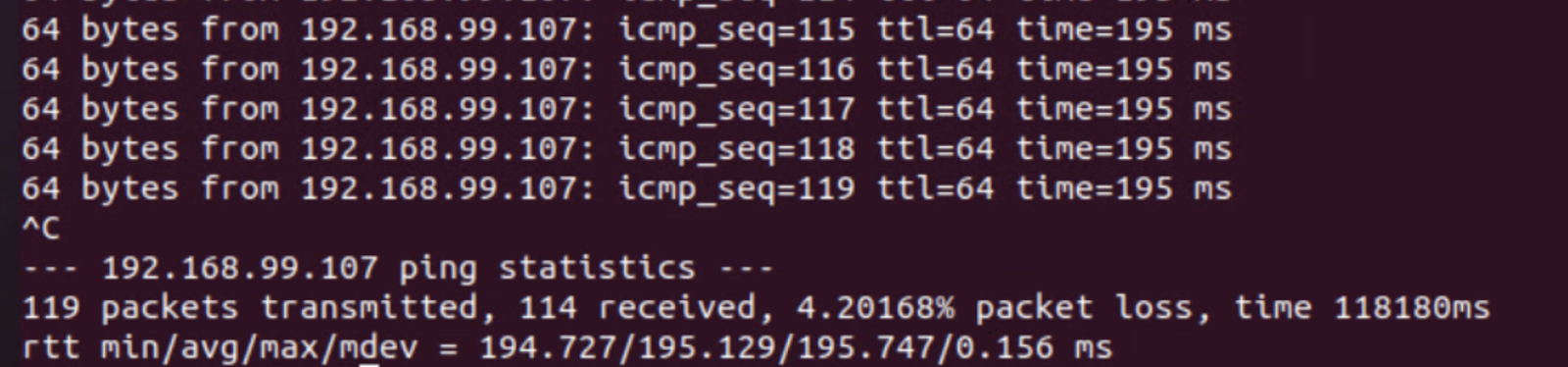
I lost 5 pings only during the failover, it was pretty quick.
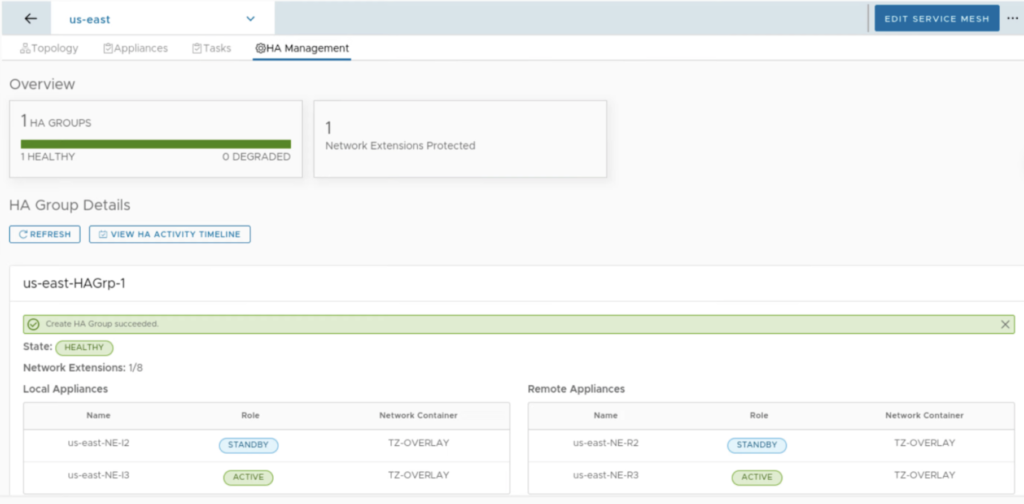
After few refreshes the UI shows a new state: HEALTHY with NE-I2 and NE-R2 being in the STANDBY and NE-I3 and NE-R3 in the ACTIVE state.
There is also an interesting option in the UI to view HA activity timeline. We can quickly check the HA history and states of the appliances.
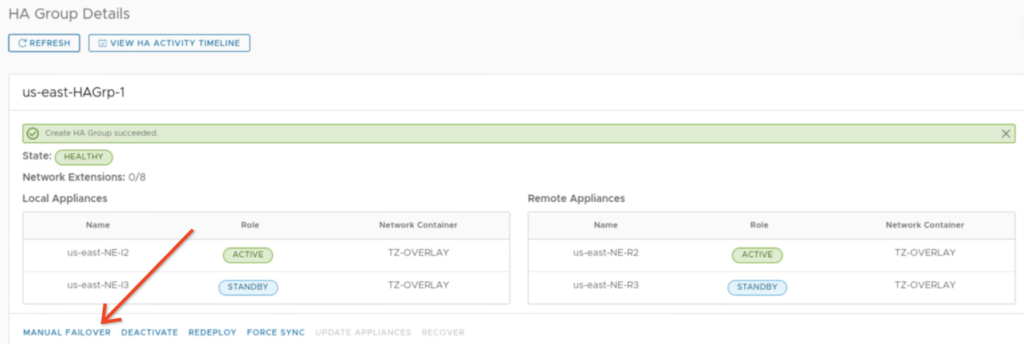
If we don’t want to power off the appliances, we can use “manual failover” option to test HA.
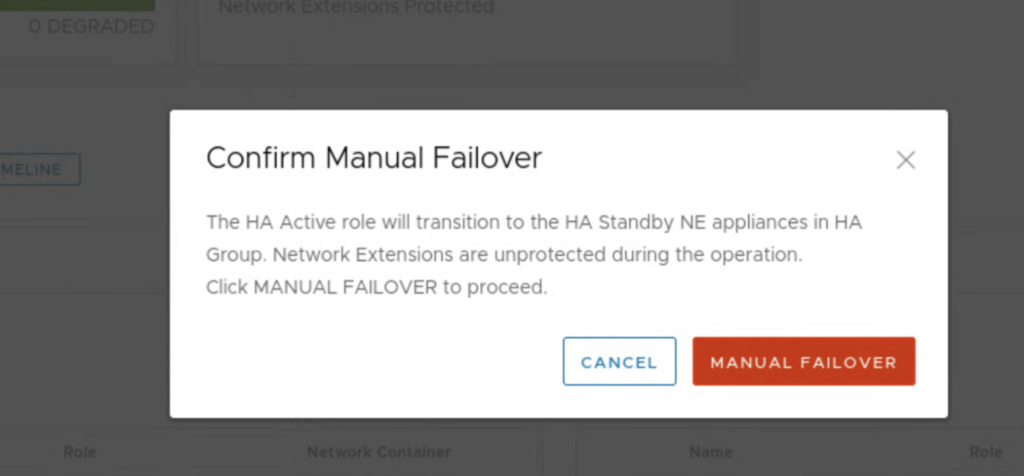
This one seems to be more graceful as I lost only 1 ping during this test.