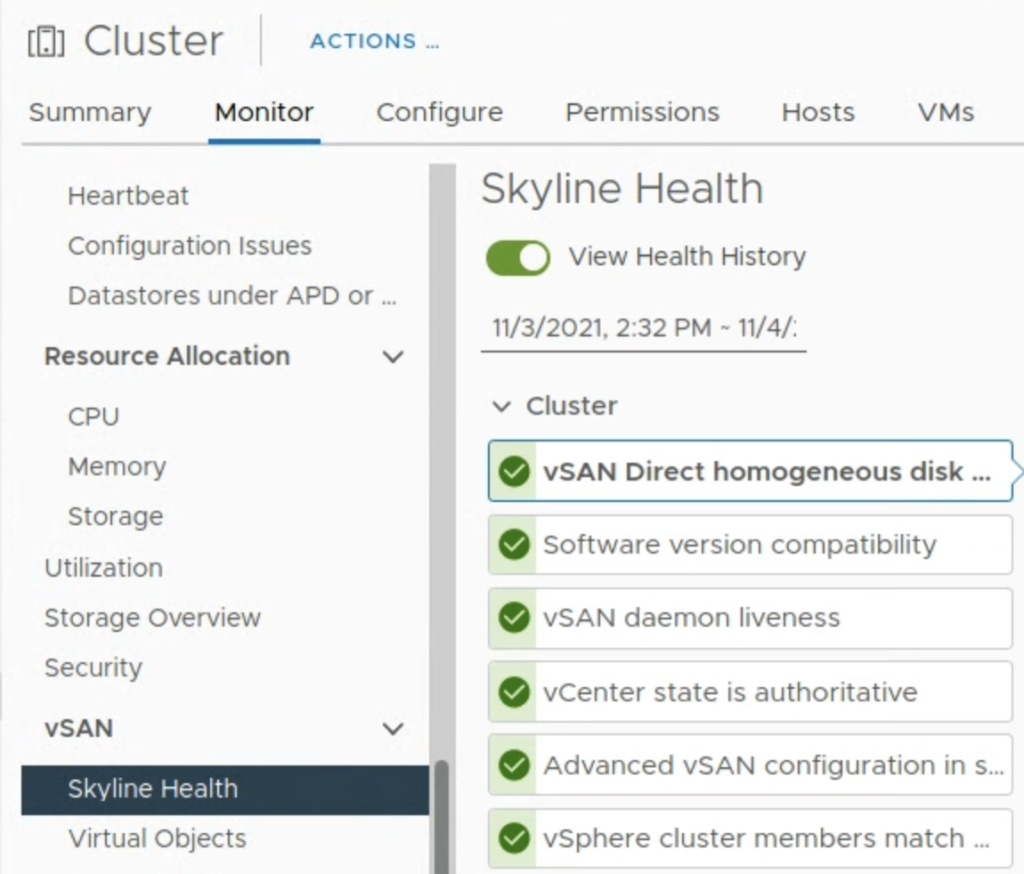
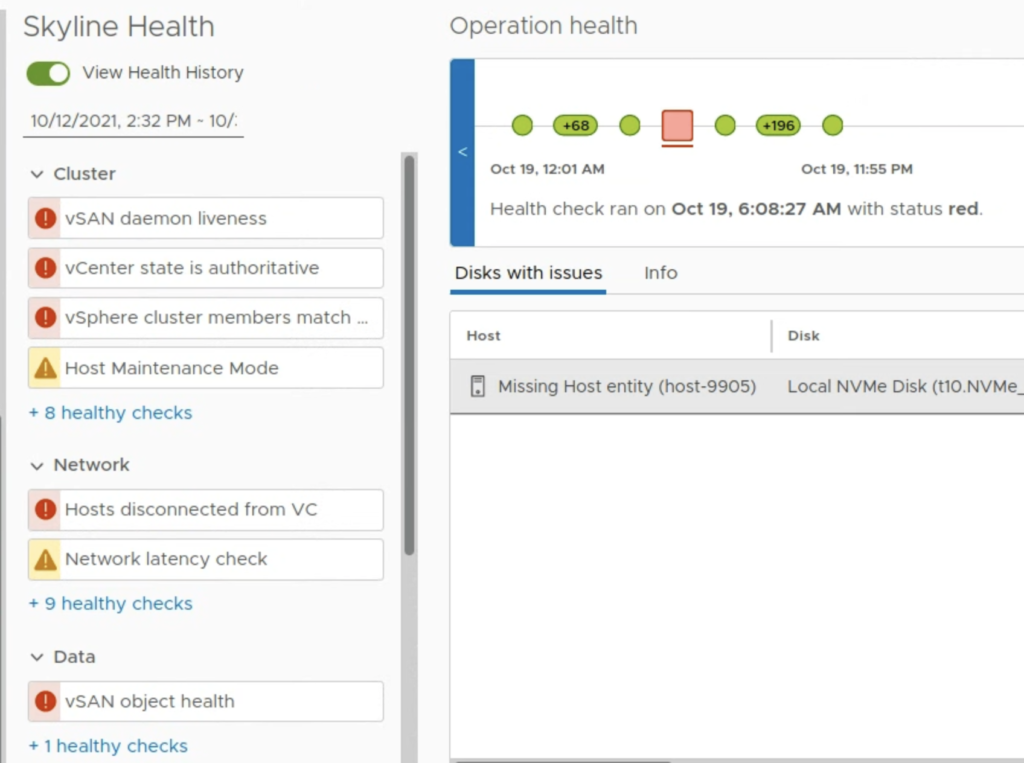
This is a small but also a very useful feature that comes with SAN 7.0 U2. In the former vSAN releases, when you troubleshooted vSAN issues (especially intermittent issues), vSAN Health showed the current status only. But if the issue occured from time to time you had to check the logs. Now you can enable the Health History in vCenter UI.
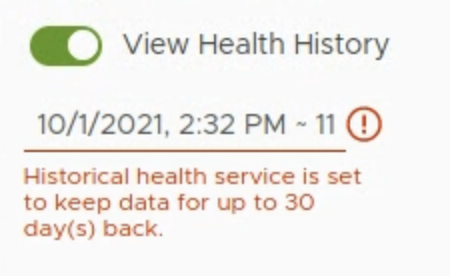
The historical health data is by default set to be kept up for 30 days back but this is sufficient in most of the cases.
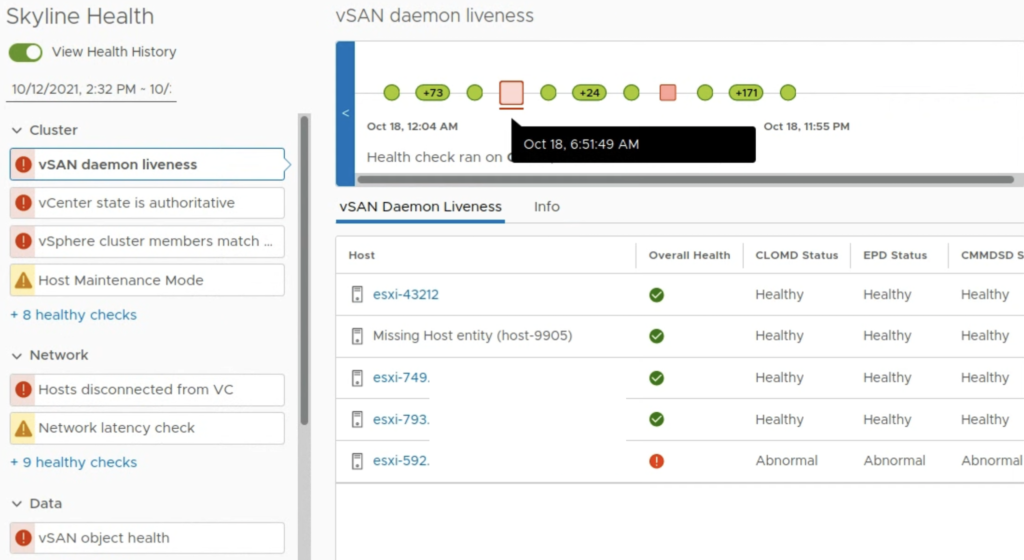
After selecting the timeframe, you will see which checks failed and when did it happen.
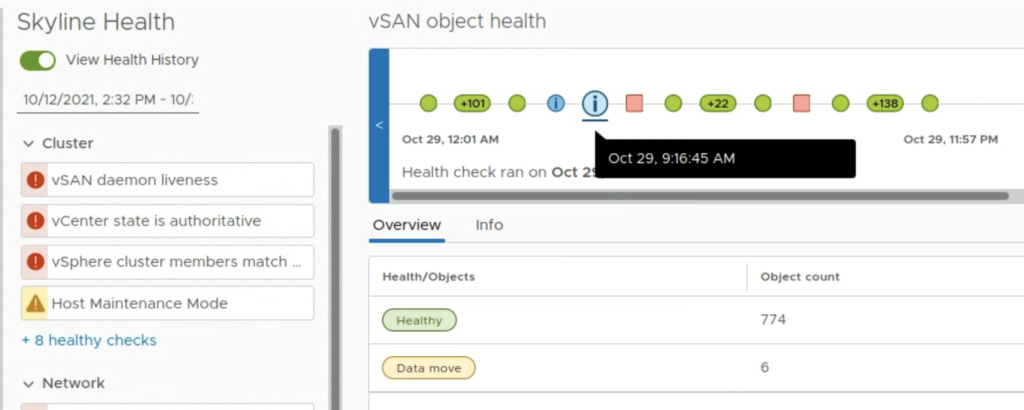
I noticed that for backplane maintenance operations like data move, we get an Info icon, not a warning.
So now we can retrieve a historical snapshot of what happened with our vSAN cluster in the certain timeframe.
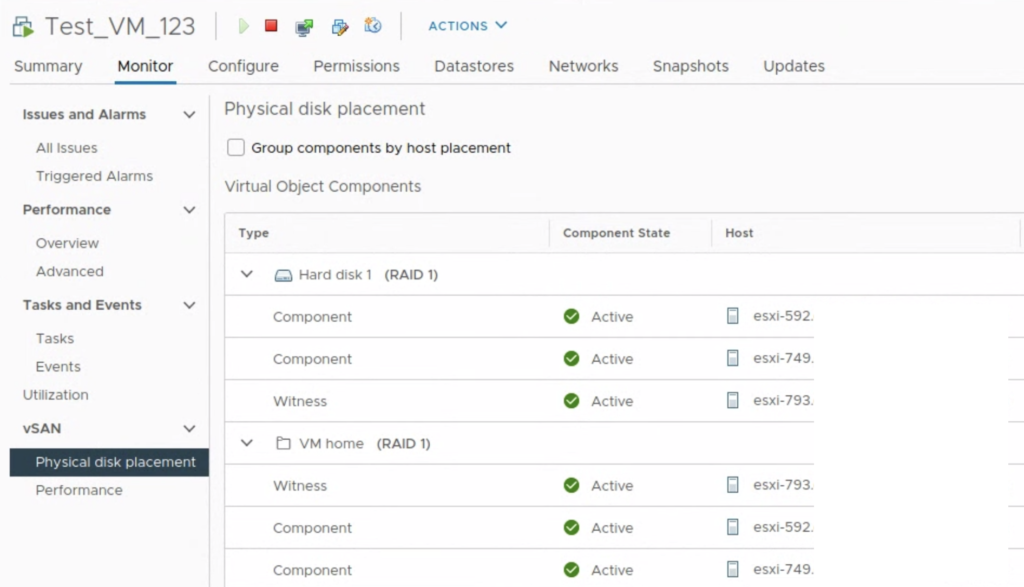
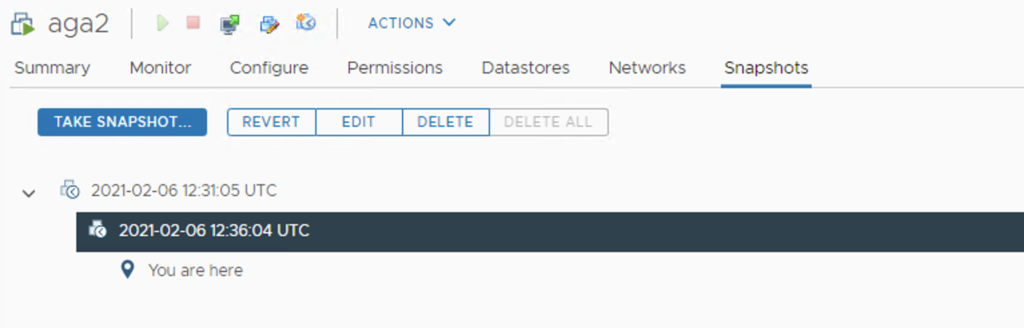
When we create a snapshot of a VM on a vSAN datastore, delta disks (where all new writes go) inherit the storage policy from the base disk.
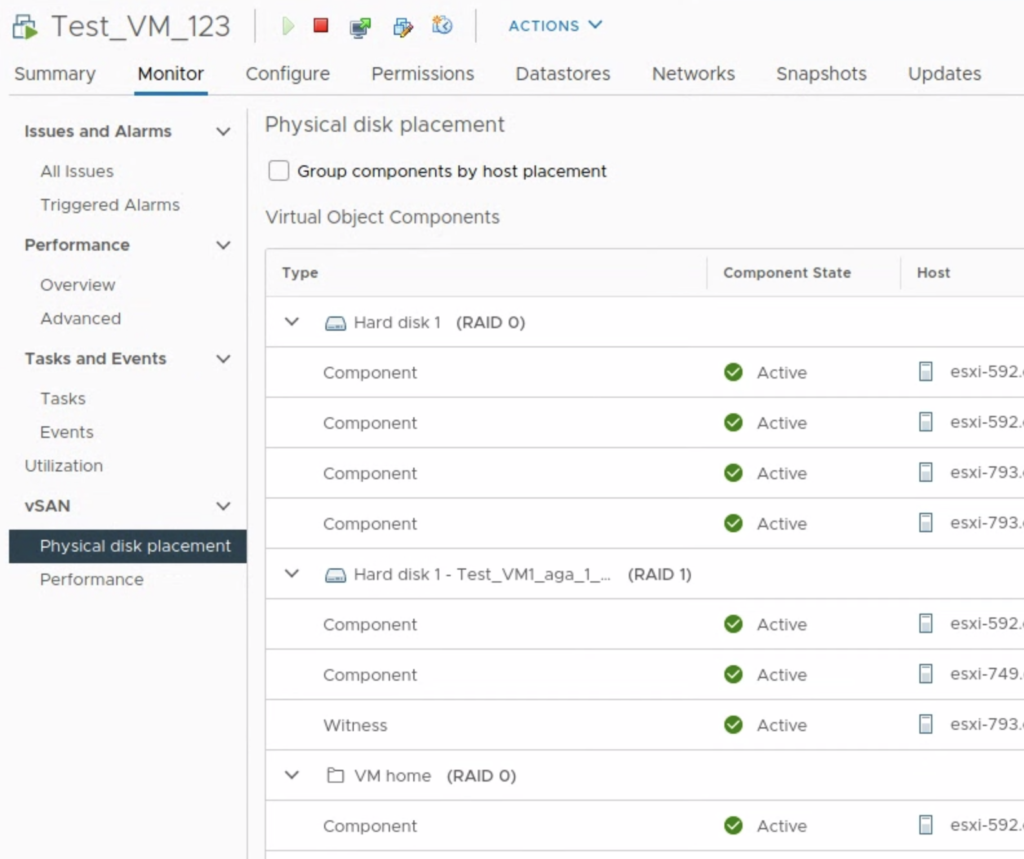
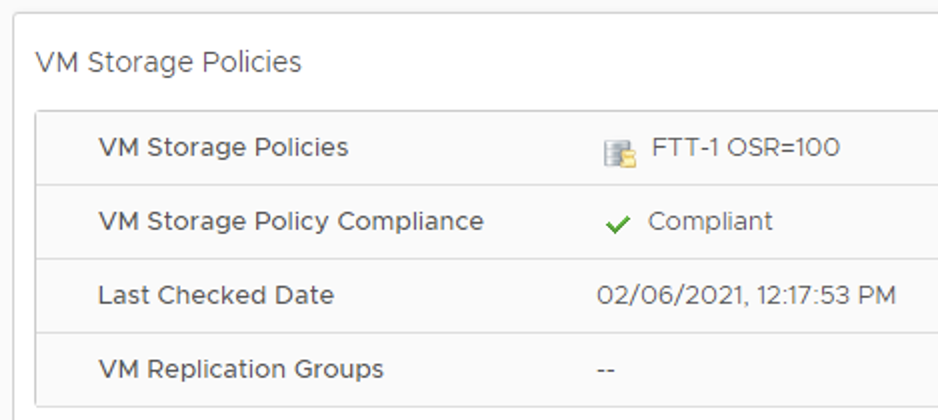
Our VM Test_VM_123 uses vSAN policy RAID – 1 mirror, which means there are at least two copies of the VMDK and a witness. After snapshot is taken, we see the same policy applied to delta disk.
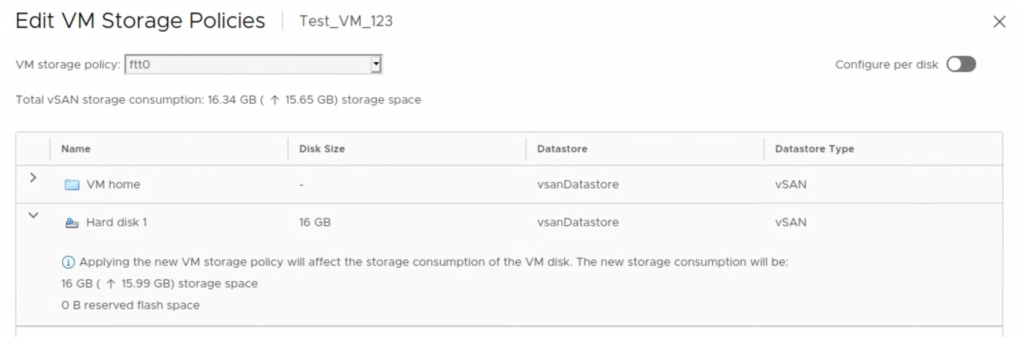
But if we want to change a storage policy for Test_VM_123, we can change it for a VM Home object and base disk only. There is no option to change the policy for a “snapshot”/delta disk.
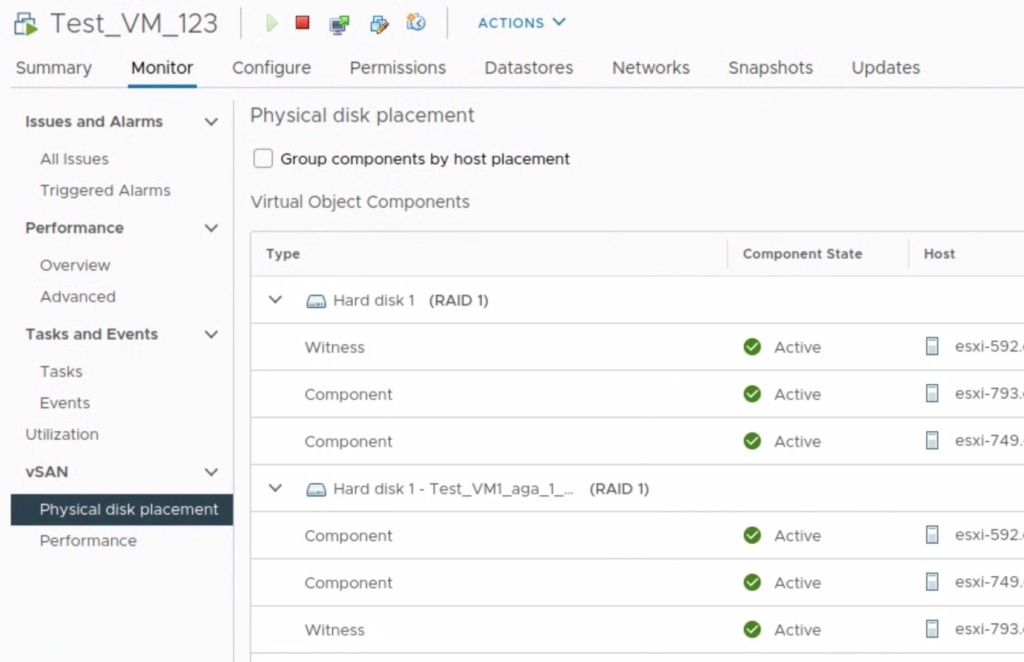
After the policy was changed for a base disk to FTT-0/ RAID-0 Stripe 4, we see the delta disk retained its FTT-1 policy.
This behaviour is described in VMware KB 70797 “Modifying storage policy rules on Virtual Machine running on snapshot in vSAN Data-store”. In order to keep all storage policies consistent across VM disks, it is recommended to consolidate all the snapshots before making a SPBM policy changes to a VM.
Uploading files directly to vSAN is not the best option. There are many ways to move data to vSAN clusters. For .iso files you can use native vSAN NFS service. For moving VMs we have Storage vMotion, HCX can be used or Cross vCenter Workload Migration Utility fling (that is also included in vSphere 7.0 Update 1c release). The move-VM PowerCLI command is also possible between vCenters that don’t share SSO. vSphere Replication could also be an option or restore from a backup. Those methods are well documented and use supported APIs.
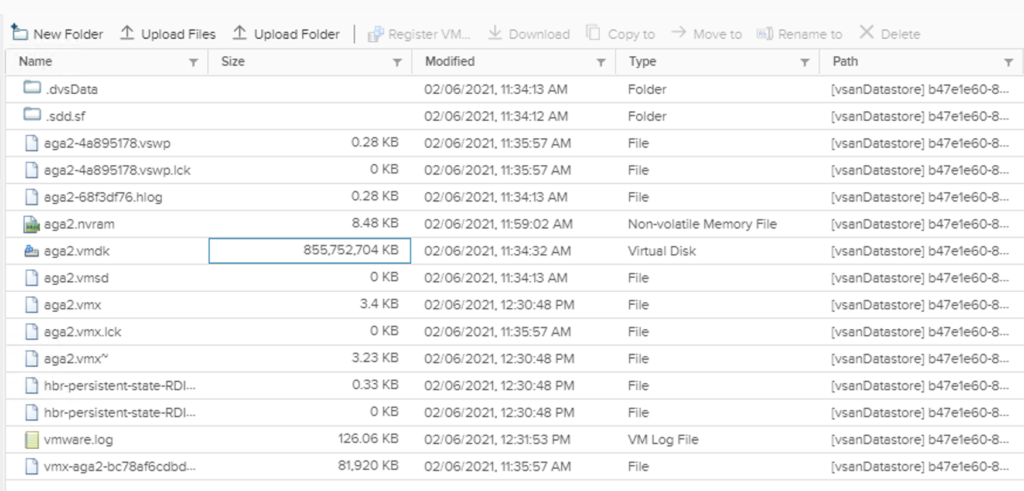
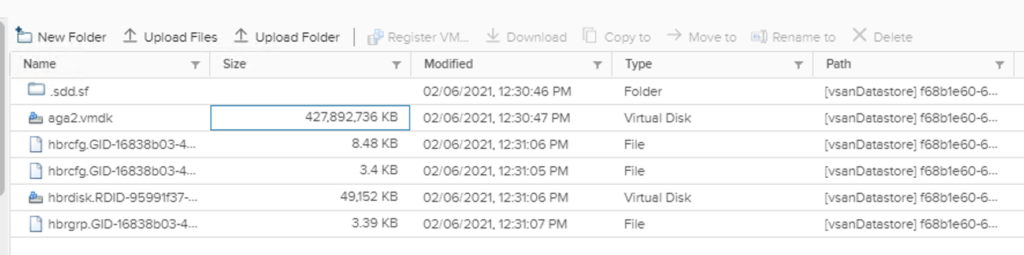
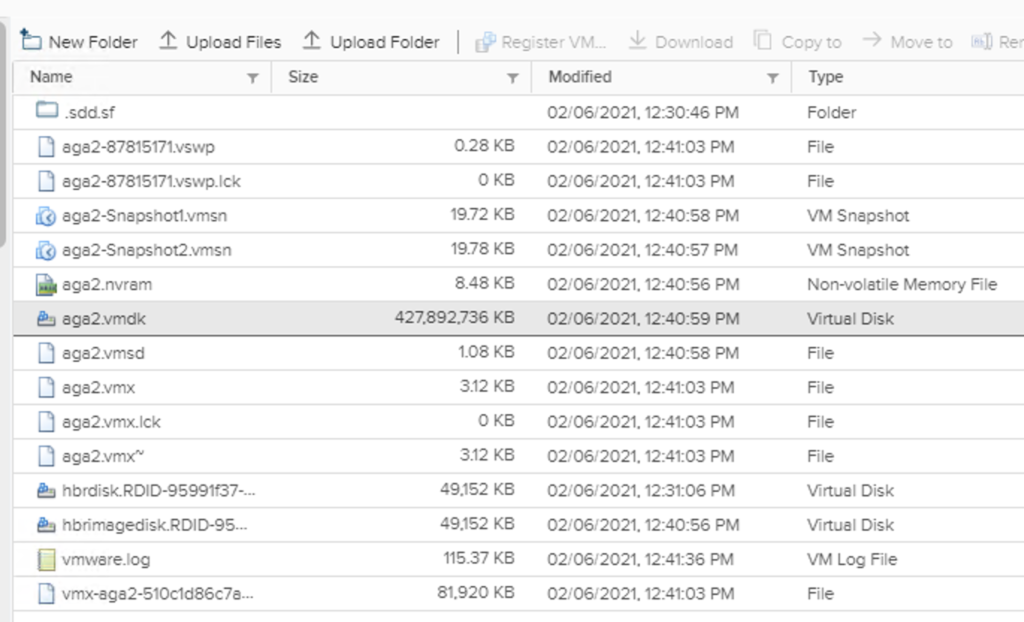
But if there is a corner case and a file needs to be put on vsanDatastore, this is also possible but not for all file sizes. System will not allow us to upload to the root path directly, we will have to create a folder on the datastore.
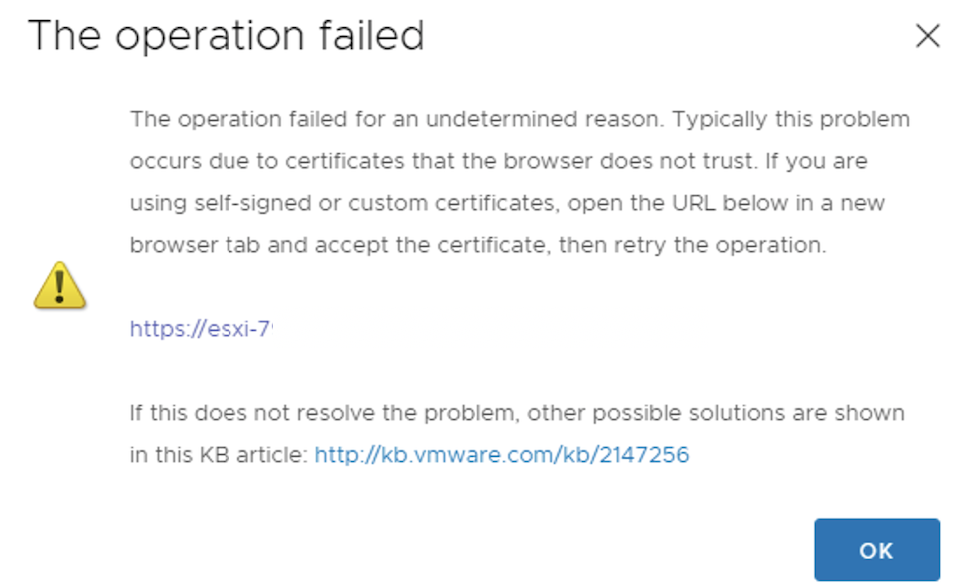
The first issue you will probably see after trying to upload a first file is the following:
Opening the recommended url and login into ESXi directly should be sufficient authorise us to upload files on vsanDatastore directly.
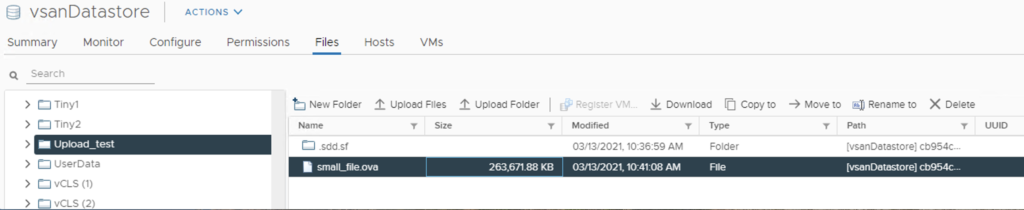
I tested it with some smaller files and up to 255 GB on vSAN 7.0 U1 cluster and the upload was successful:
but adding another file in this folder failed:
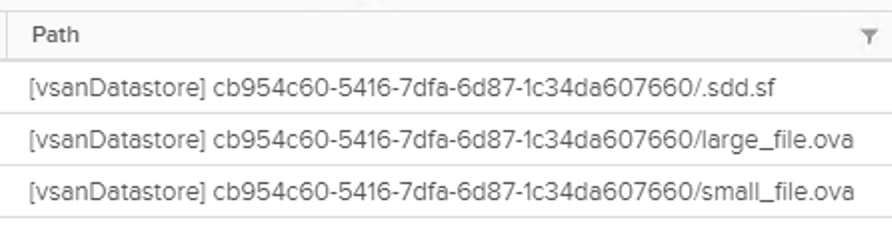
Also uploading a >255GB file in a new folder on the vsanDatastore failed. What I could find in ESXi vmkernel.log was the following:
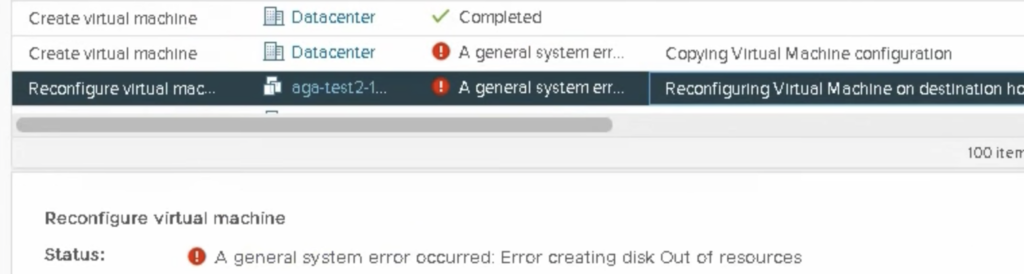
write to large_file.ova (...) 1048576 bytes failed: No space left on device
'cb954c60-5416-7dfa-6d87-1c34da607660': [rt 1] No Space - did not find enough resources after second pass! (needed: 1, found: 0)
It looks like uploading files do vsanDatastore directly bypasses the logic that stripes objects larger than 255GB into smaller components. Why is that?
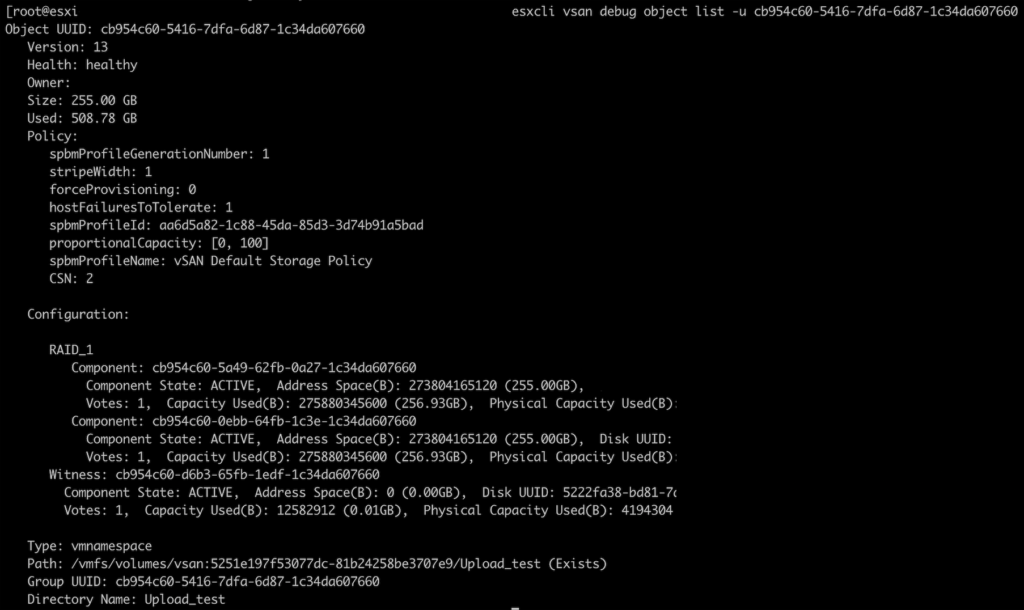
Looking into the file path, you can determine its object UUID which in my case was: cb954c60-5416-7dfa-6d87-1c34da607660
You can use the following command to query this object in esxi directly:
esxcli vsan debug object list -u cb954c60-5416-7dfa-6d87-1c34da607660
Now we have the answer. Object type our our direct upload is vmnamespace and it’s like a container with fixed size of 255.00 GB. And this is the max number of GB that we can place there. By default it uses vSAN Default Storage Policy (FTT=1, mirror in this cluster).
VMware vSphere Replicaton Appliances VRA installed on Protected and Recovery sites enable replication of VMs between those locations. VRA is very popular and well documented. The question is how its latest edition integrates with vSAN 7.0 U1?
The best way to check is to install and test both solutions. The configuration proces is simple, we domwnload ova, deploy it on both sites, make sure an appliance is reachable by local vCenter (DNS and NTP are required) and a service account we use for registering VRA in vCenter has sufficient privileges. During installation, we get a Site Recovery plugin in a local vCenter and VR Agent on each local ESXi.
Configuring VRA in https://fqdn_vra:5480 VAMI portal
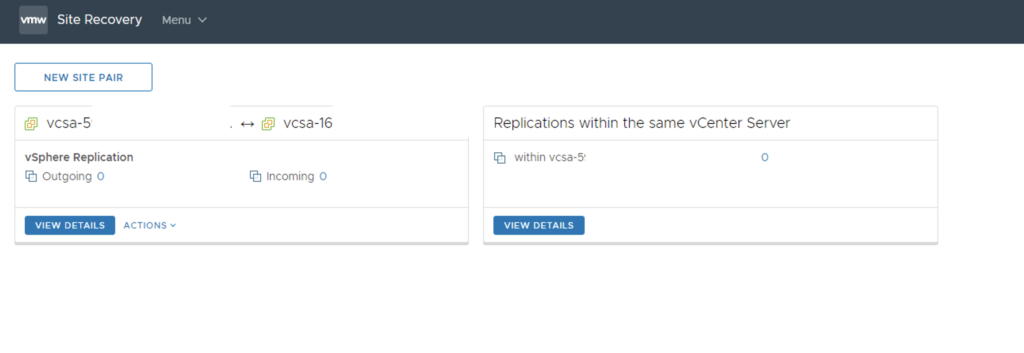
VRA can work as standalone solution providing replication service between clusters under the same vCenter. Paired with remote VRA offers a protection from a site failure. It integrates with vCenter we can setup a VM protection directly from vCenter UI.
vcsa-5 and vcsa-16 pairing
After site pairing is done, we can start replication tasks. In this example both sites are vSAN 7.0 U1 clusters. To check how vSAN SPBM integrates with VRA, I will create a task to change vSAN SPBM when replicating on the destination site.
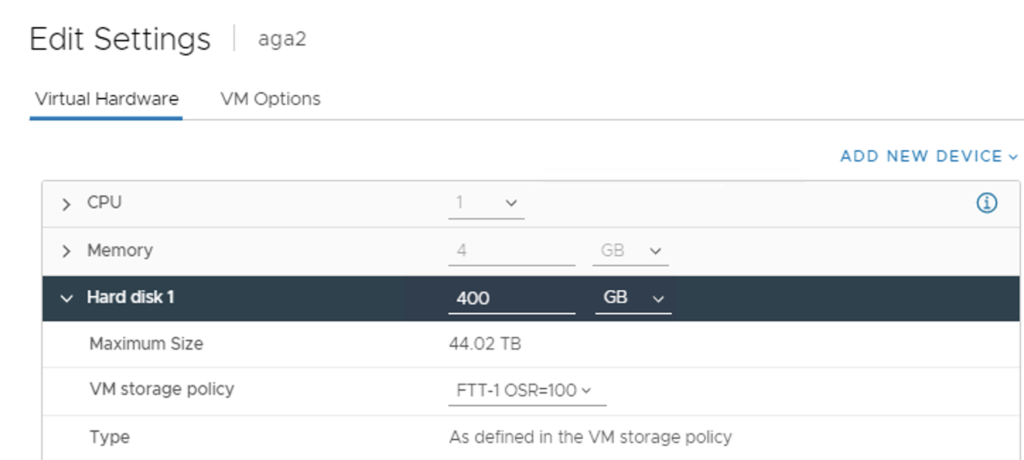
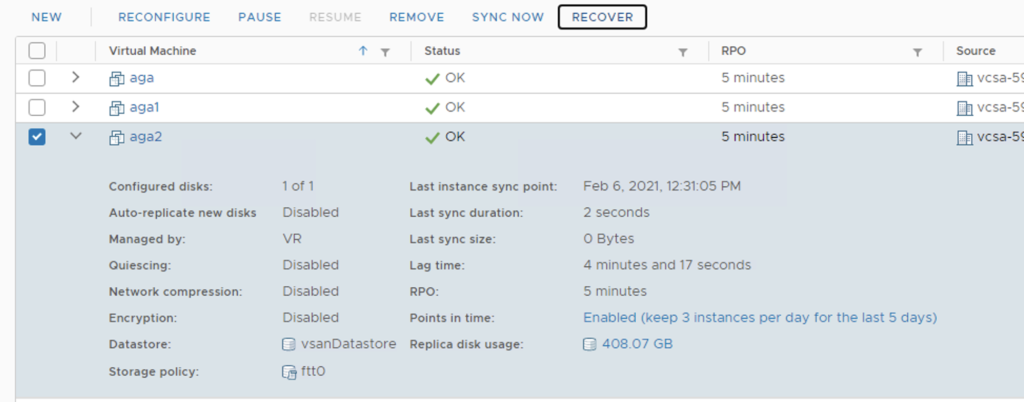
VM aga_2 has a 400 GB VMDK disk on the source side. It has FTT-1 mirror SPBM policy with Object Space Reservation 100%. This means I get 2 copies of VMDK on the vSAN datastore and it occupies around 800 GB of space.
From the source vCenter I can now configure replication for this VM,
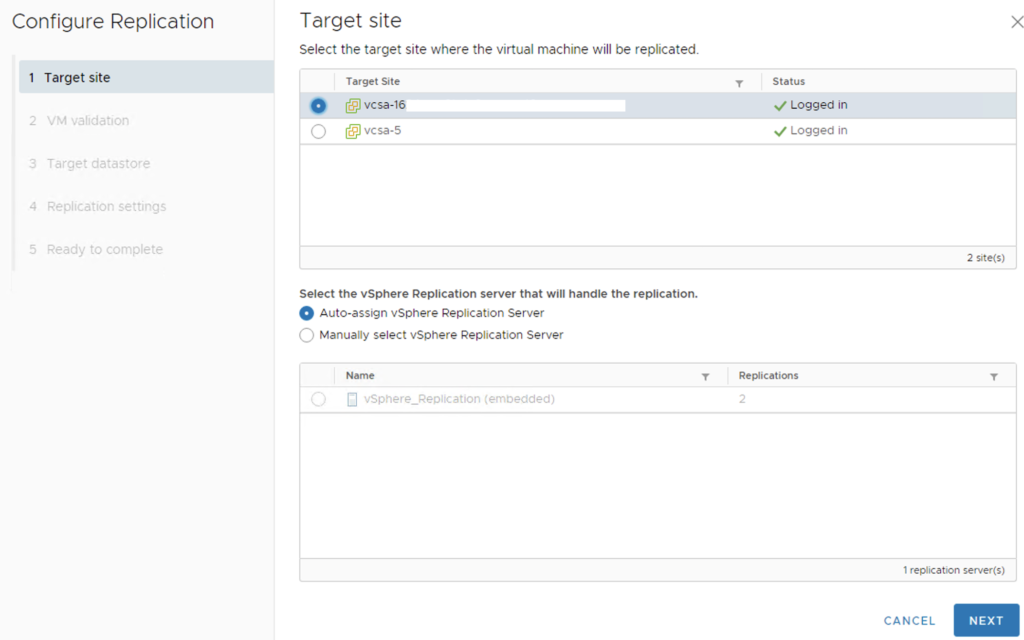
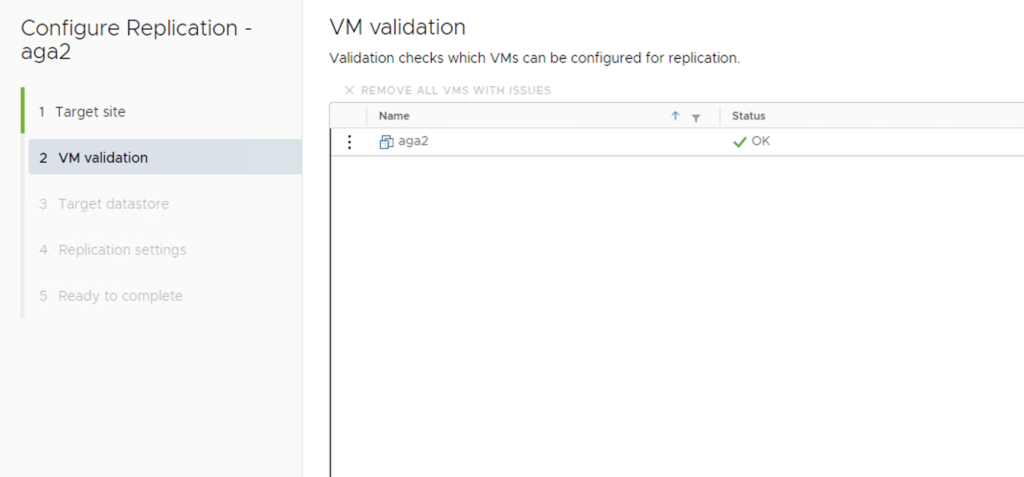
The steps are simple, we have to select a Target site (vCenter-16).
VRA checks if this VM can be configured for replication.
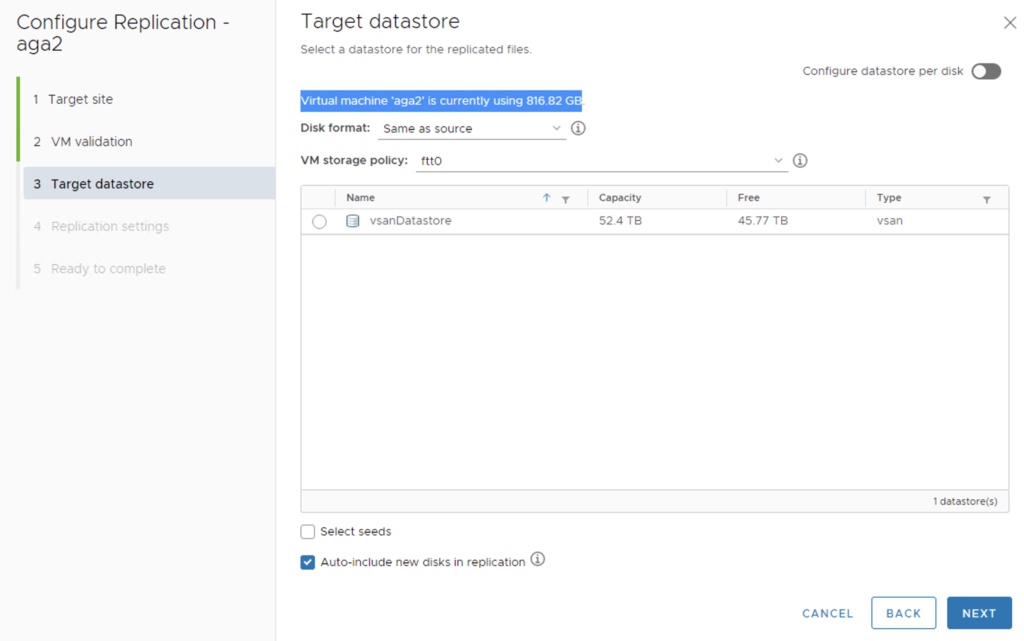
For a vSAN datastore at a Target site we can select (even per disk) a different vSAN storage policy than the one at a Source site. In this scenario I select FTT-0 SPBM, which means I will have just one copy od the VMDK (not recommended in production!). Sometimes it happens a budget for a remote site is limited and a storage space there may not be sufficient to store more copies of the data. I want to check if it is possible to replicate from FTT-1 to FTT-0. If yes, in real-life scenarios we could save some space and have for example RAID-1 mirror on a Source side and a RAID-5 on Destination.
vSAN SPBM at Destination site
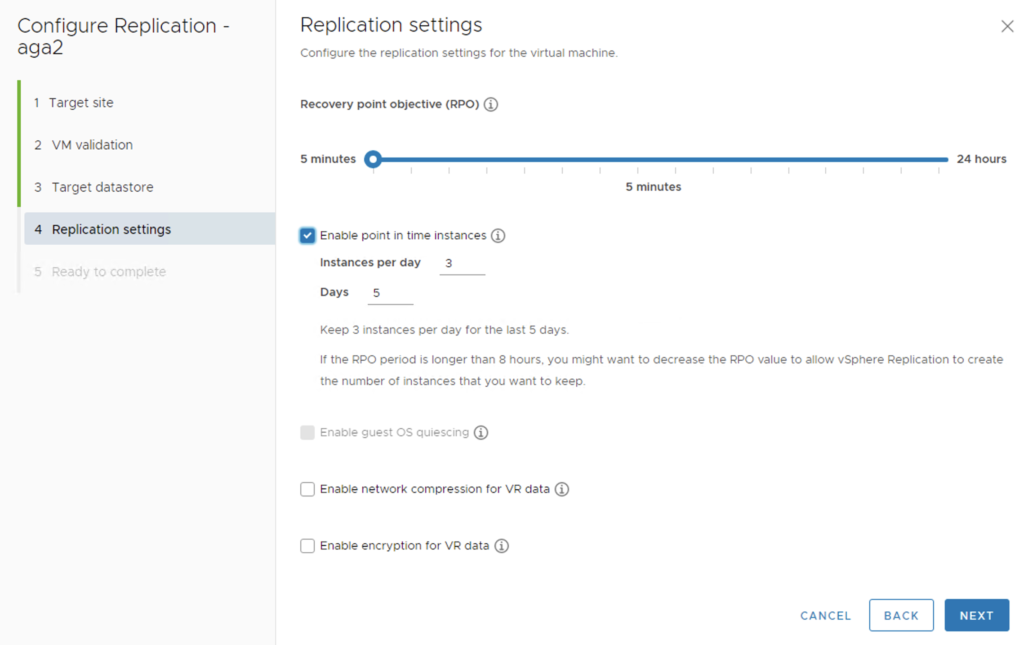
The most important part of the replication setup is setting Recovery Point Objective and the number of points in time (snapshots) we can revert to in case of a failure at the Source site.
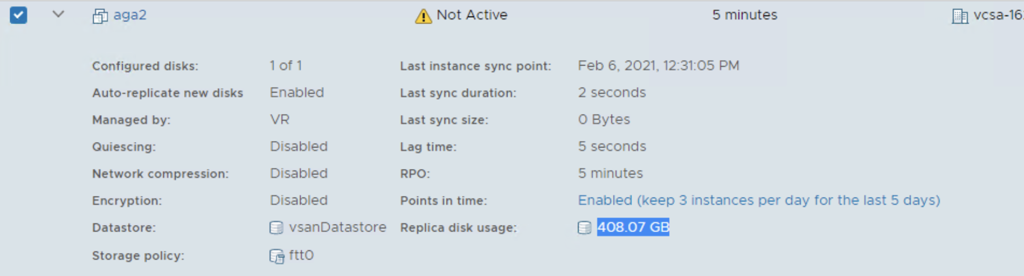
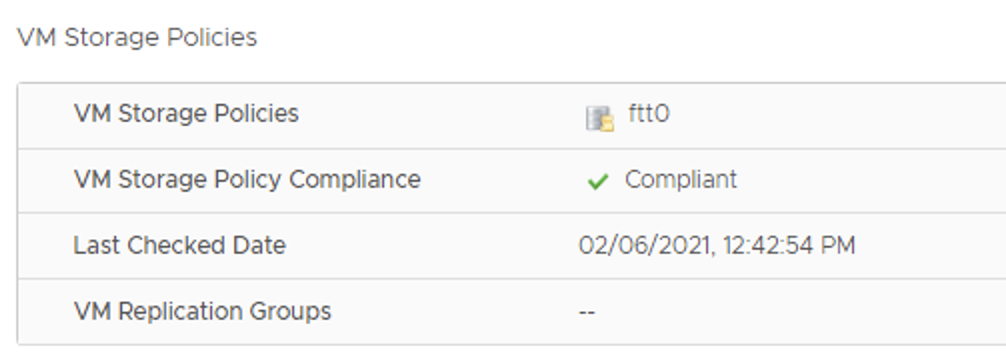
Configuring replication of aga2 to use vSAN storage policy ftt-0.After first replication sync, on Target vCenter: vcsa-16, replica of aga2.vmdk has around 400GB, which means only one copy of the object is stored on the vSAN datastore.
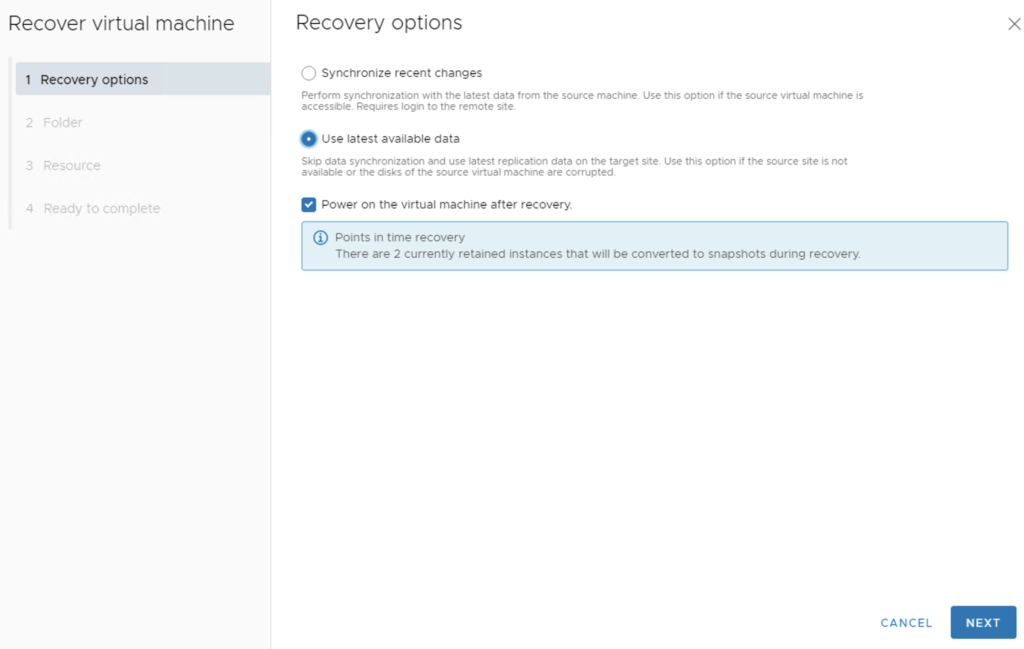
After a successful syncing between Source and Target sites, we can RECOVER aga2 VM. This means it will be registered on Target site. It can also be powered on right away.
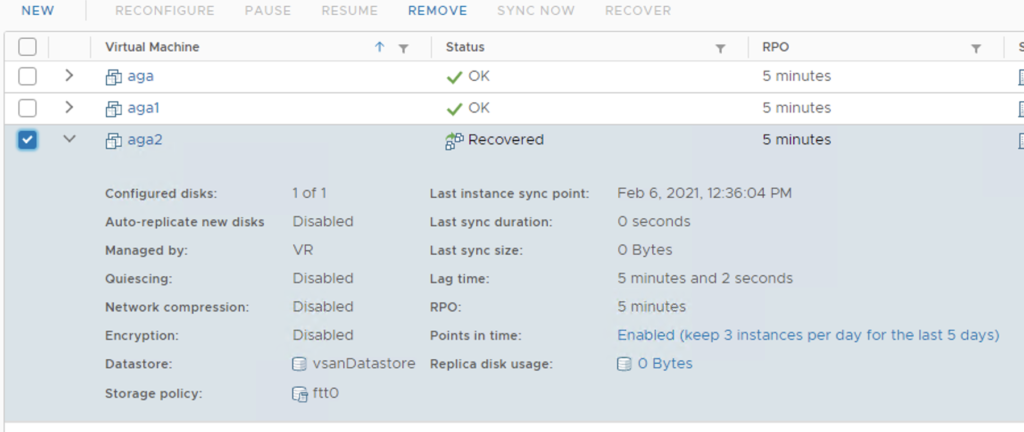
The VM was replicated with points of time/snapshosts available. Now we can revert to the selected snapshot from the Target site.The VM is powered on at the Target site, change to FTT-0 vSAN policy was successful.
vSAN storage policies integrate with VRA. This is not a new feature introduced in 7.0 but I still remember some time ago replicated VMs had always Default vSAN Policy (2 copies) and manual SPBM refresh was required after recovering a VM. There was no way to save space on the Target site with the SPBM policy change as it had to be re-applied later.
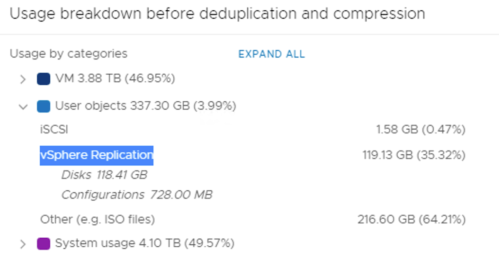
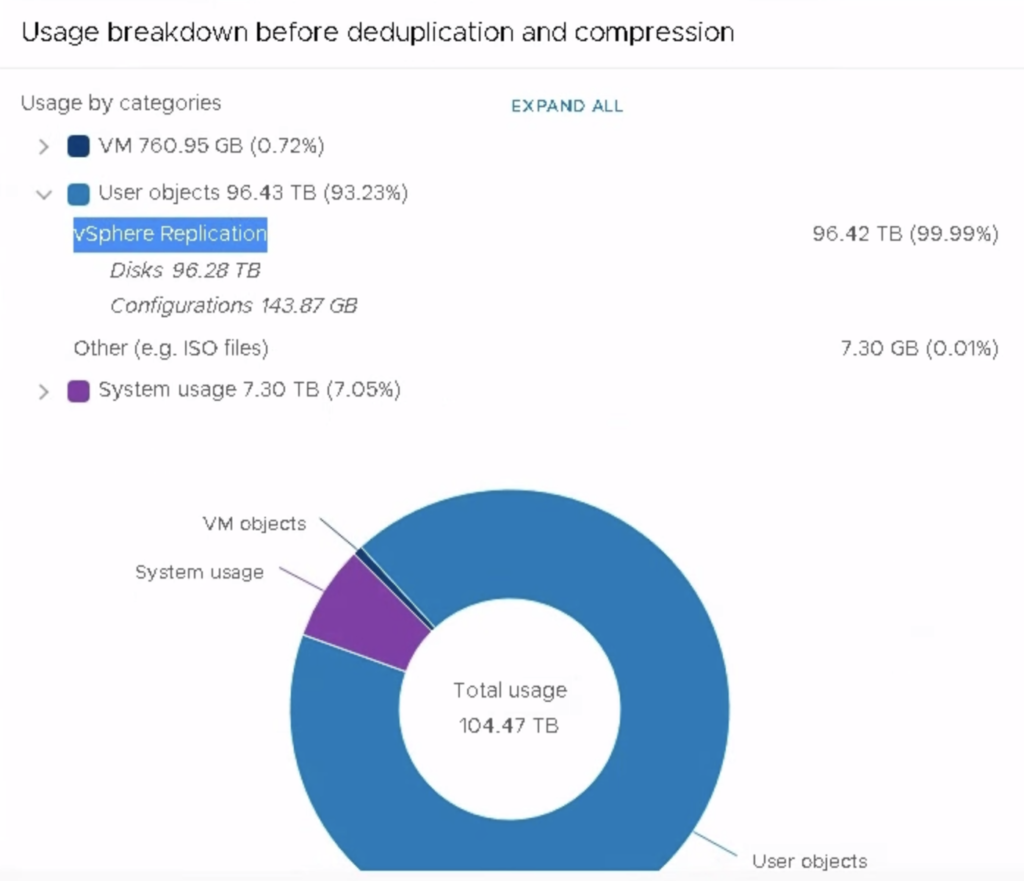
What is new in 7.0 is the fact that vSAN Capacity Report in vCenter UI shows how much data is used by vSphere Replicaton. In previous versions we were not able to detect how much of a vSAN capacity was used by disk replicas.
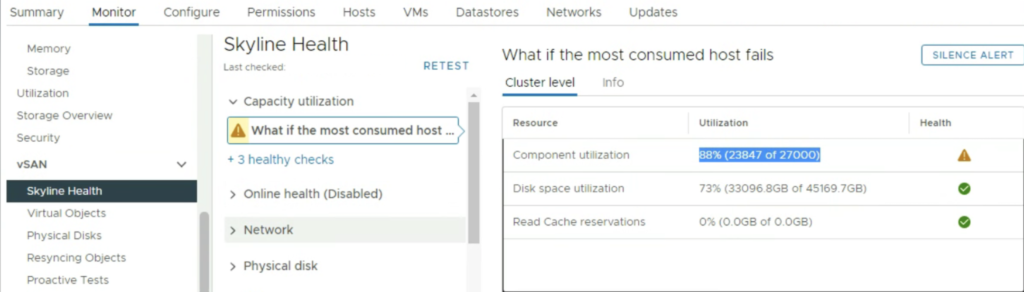
A small advice at the end. VM replicas are not registered in a Target vCenter, so it is easy to miss the actual size they use. We will not see so many VMs under vCenter but the replicas will be there. Check usage breakdown regularly. If you keep many point in time copies of the VM, the number of the vSAN components will also grow (with FTT- policy each object will have 3+ components ). It is good to check Capacity utilisation in vSAN Skyline Health: “What if the most consumed host fails”. Component utilisation in vSAN environments that are target for vSphere Replication is usually high.
While browsing the familiar vCenter UI right after an upgrade from 6.7U3 to 7.0U1 I noticed some small but nice changes I wanted to share.
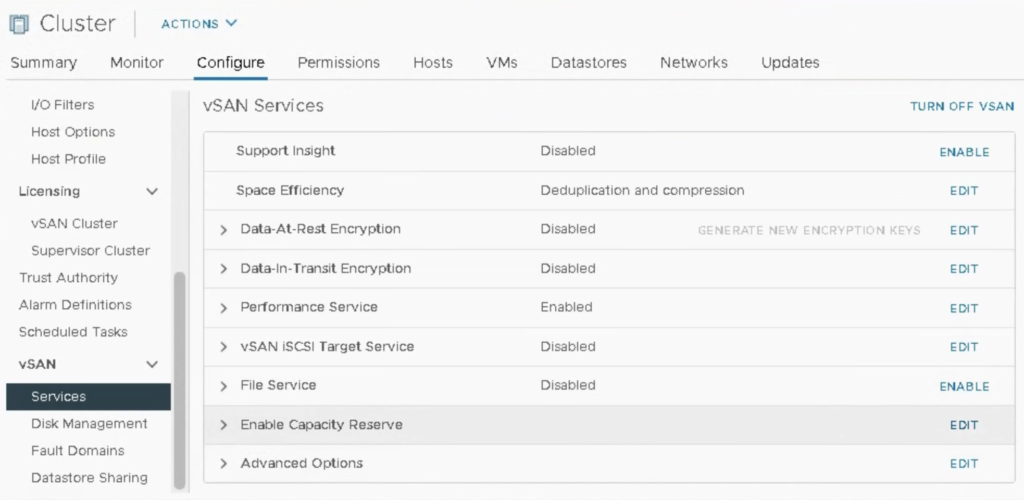
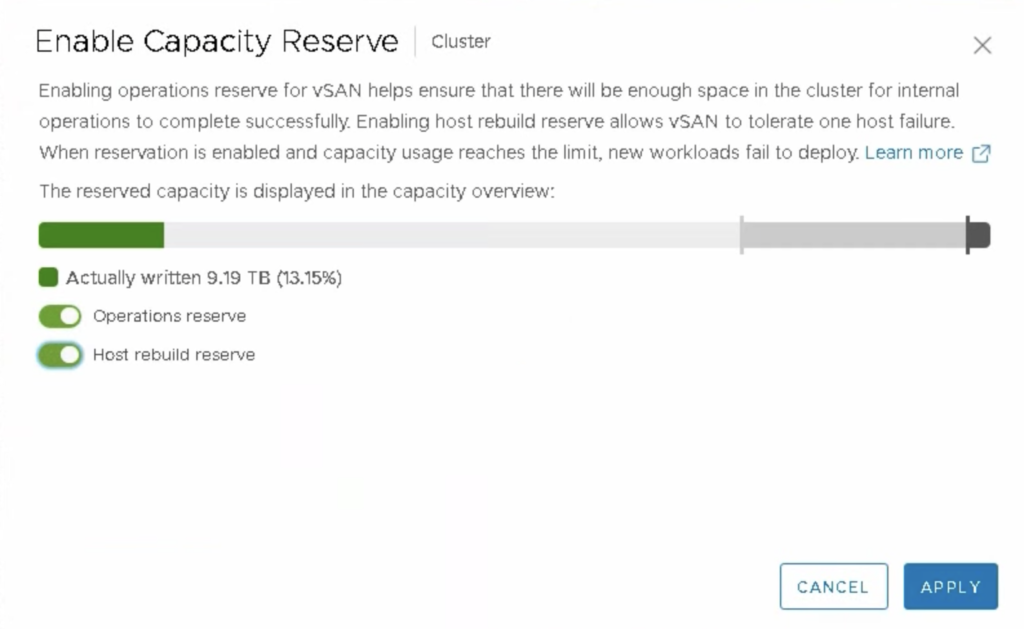
Enable Capacity Reserve for vSAN datastore
Cluster -> Configure-> vSAN Services: this part just got a new option: Enable Capacity Reserve. To be able to see the benefits of this improvement, lets see how it was in pre-7.0 era.
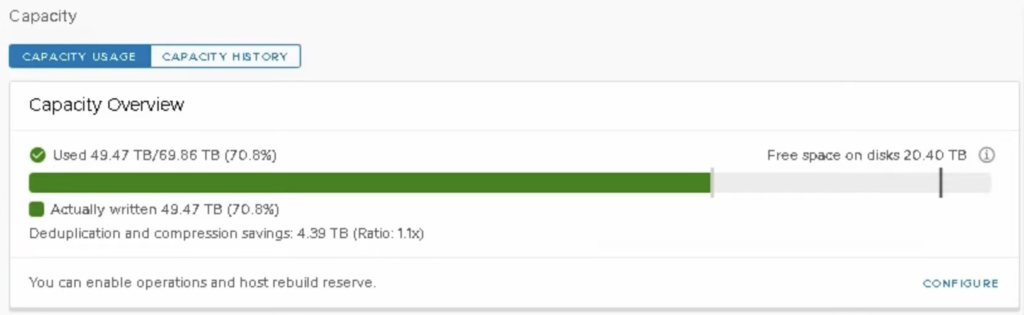
In my 4-node vSAN cluster where hosts have around 17,49 TB capacity each, the datastore capacity is 69,86 TB. When actually written capacity (used by VM) reached 49,47 TB which was more than 70% of the cluster space, it was still ‘all green’ for the cluster in CAPACITY USAGE view. Don’t look at dedupe savings, this is just a test environment.
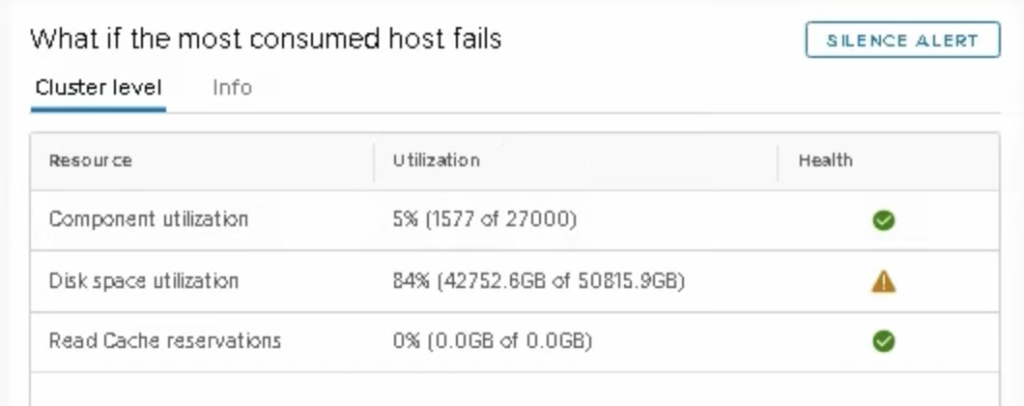
The only indication that the datastore was getting full and that we could potentially run into rebuild issues if a host failed was vSAN Skyline Health check “What if the most consumed host fails”.
In this situation having datastore which was 70% full already and 47 TB of VM data, loosing 17,49 TB would mean datastore size around 52 TB. 47/52 means datastore full in 90%. But I was still able to create new VMs, this limit was soft.
For vSAN 6.7 to stay on the safe side we had to use fixed 25-30% of slack (free) space regardless of the cluster size. 25-30% guaranteed there would be enough space for rebuilds and cluster operations in case of a node failure but in many cases it was too much and not everyone was an expert in monitoring the cluster size. On the other hand, not everyone could afford to constantly monitor the space making sure no one creates an automation task to provision hundreds of VMs over the weekend that could make vSAN datastore full.
Capacity Reserve is a feature that helps to control the vSAN capacity and is specific to your cluster size. It will also protect the cluster from provisioning new VMs, so datastore will not get full.
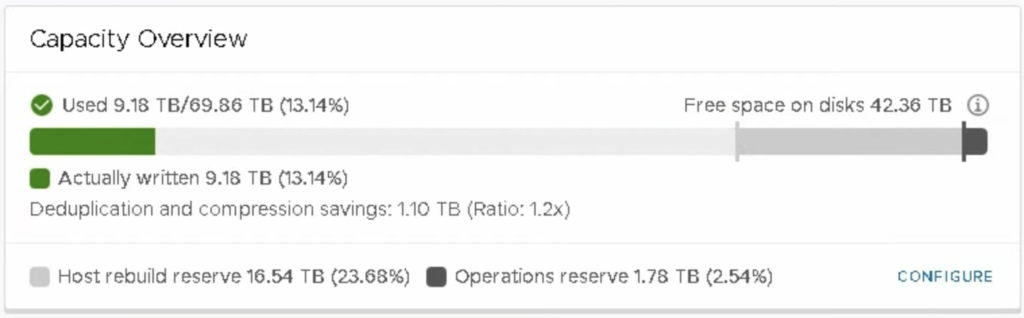
In my case, I still have 4-node vSAN Cluster with capacity 69,86 TB. When I enable Capacity Reserve feature, my VMs use only 9,19 TB of vSAN datastore. I don’t get to set the capacity reservations, the exact values are calculated and set for me. When I select Operations reserve, it is up to me to select also Host rebuild reserve (the first one has to be selected to be able to select the second).
Looking at capacity Overview of the vSAN datastore, I see that the system has reserved 16,54 TB for the host rebuild (23.68 %) and 1.78 TB for operations (2.54%).
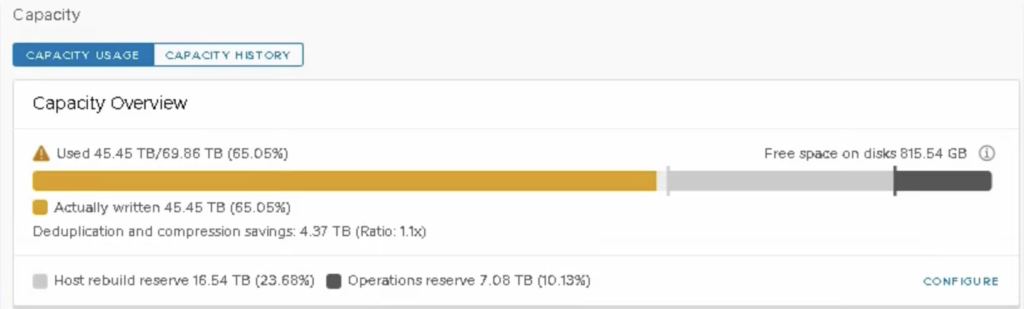
When I create more VMs and vSAN tasks, my capacity utilisation reaches 45.45 TB (the utilisation is now almost the same as in the first scenario). I can also see the Operations reserve increased to 7.08 TB (10%). It is because I created more VMs and more tasks so more cluster resources would be needed for operations.
You can see Capacity Overview changed colour to yellow, showing I am reaching my space limit. Actually “free” space on disks is now 815 GB. The remaining capacity is secured in case of a host failure or rebuilds.
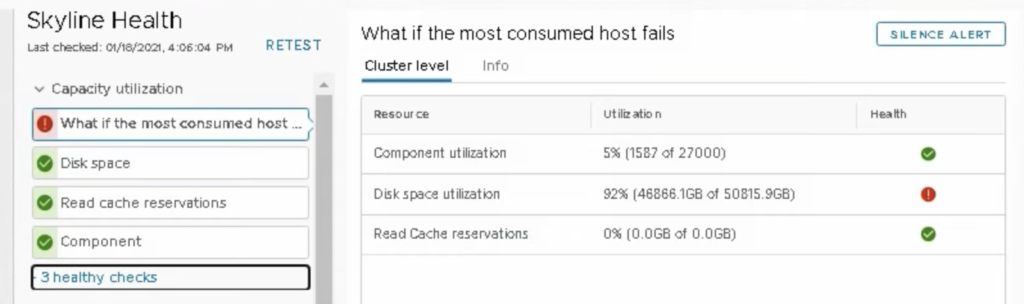
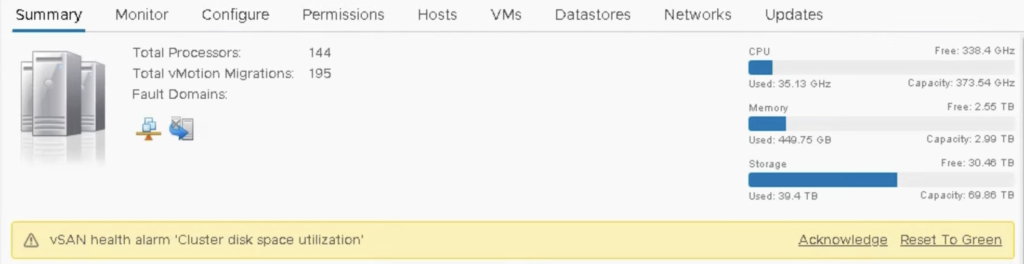
You can also see an alert in vCenter: vSAN Health alarm “Cluster disk space utilization” triggered although cluster still has free capacity. Isn’t it little bit like HA Admission Control for a storage?
Even though there was still some space on vSAN datastore, it prevented me from creating new VMs.
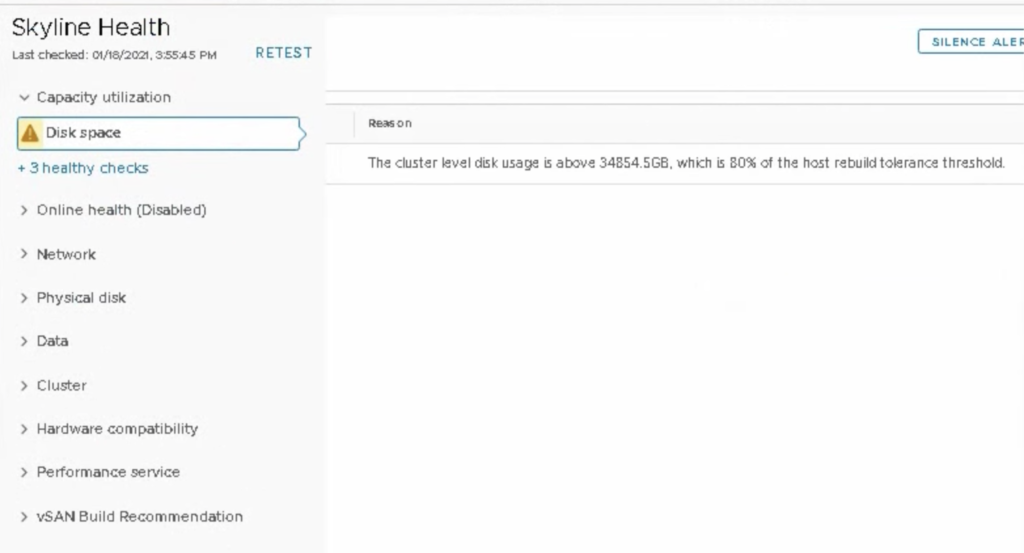
We also get Disk space vSAN Health alert “This cluster level disk usage is above 34 854 GB, which is 80% of the host rebuild tolerance threshold”.
And in addition to that, also ‘What if the most consumed host fails’ is triggered independently of the other alerts.
It seems the feature is very effective and finally we can put a hard stop and prevent vSAN from getting full.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.