“If you can’t explain it simply, you don’t understand it well enough.”
Albert Einstein
I have an impression that for Pre-sales Engineers it is harder than for others ;-). Especially when you need to explain the benefits of a complex solution in a simple but also short way.
Keep it Sesame Street Simple, they say.
I am practicing my SSS skills on vSAN…
Usually in traditional 3 -Tier architecture under every vCenter we have a long list of datastores backed by different LUNs created on storage arrays from different vendors having various settings: mirrored LUN, RAID-10/5/6, deduplication ON/OFF, synchronous and asynchronous replications. They are thin-provisioned and have various used/free ratios. Admin can identify a suitable datastore for a VM by a name or a tag but it is not always sufficient, especially when storage and compute resources are managed by different teams. VMs can have many VMDKs with different performance and resilency requirements. How to keep it all in order?
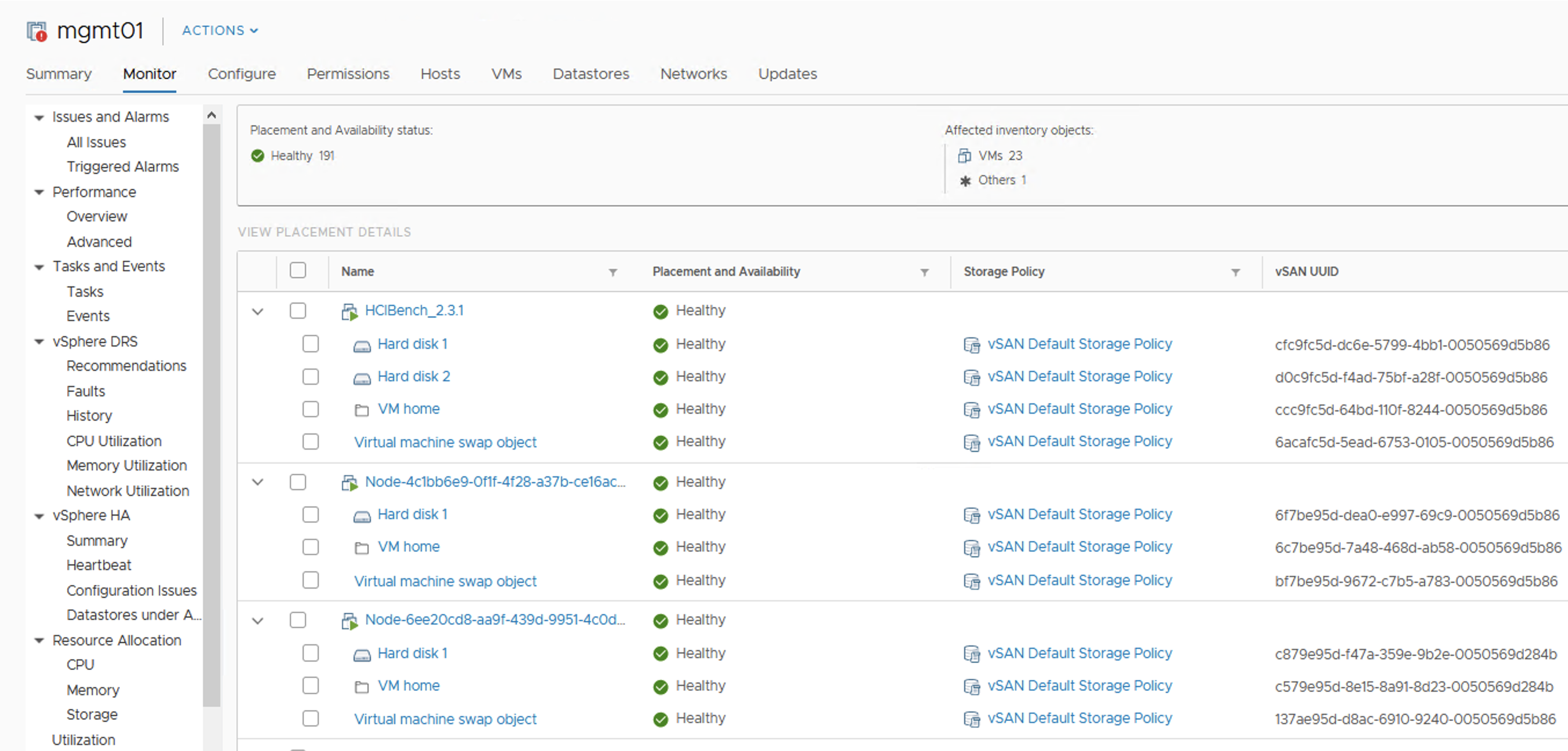
With vSAN there is always one datastore per cluster. It uses storage policies that can be assigned on per-VMDK basis. This allows to allocate storage resources granularly and with an application requirements in mind.
vSAN makes storage management way more easier. It also simplifies the troubleshooting process. You do not have to figure out which datastore is used by the particular VM and troubleshoot it individually. The storage path from a VMDK to a physical disk can be tracked and analyzed in details in a vCenter.
Number of disk stripes per object is a vSAN SPBM policy that I don’t see implemented often. It’s probably because vSAN performs great and doesn’t need additional tuning in most cases.
Just in case you are running vSAN on hybrid cluster (it improves destaging from cache to capacity) or have a case for a particular VMDK that would benefit from the access to the IOPS available through a disk group or disk groups, you might want to check this SPBM.
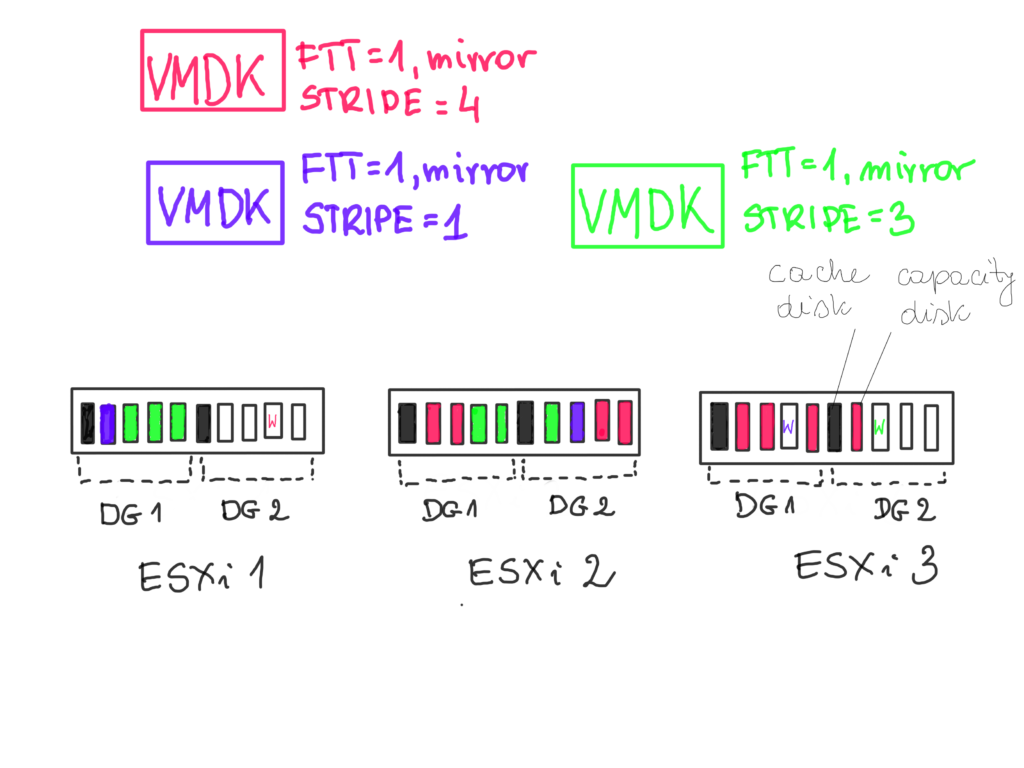
Let’s see some examples for a simple 3-node cluster.
VMDK with STRIPE=1 will have two copies on two hosts and a witness metadata on a third host. I am assuming the disk is less than 255GB, if it is more than 255GB, vSAN will stripe the object for us anyway.
[by the way the default stripe >255GB differs from stripe defined by SPBM, because the components could sometimes be placed on the same disks and when it is controlled by SPBM, there are always different disks]
VMDK with STRIPE=3 will also have two copies on two hosts and a witness metadata on a third host. BUT the copies will reside on 3 disks instead on 1 disk. On ESXi 2 one part of the stripe is on disk group DG1 and the second part is on DG2 – so there is an extra boost because two disk caches are used for this replica.
VMDK with STRIPE=4 will again have two copies on two hosts and a witness metadata on a third host. BUT the copies will reside on 4 disks instead on 1 disk. On ESXi 2 and ESXi 3 one part of the stripe is on disk group DG1 and the second on DG2 – so again there is an extra boost because two disk caches are used for this replica.
vSAN will place the components of the object automatically for us, we don’t have to configure it. The only we configure is the number of disks we want to use the stripe on. We also need to have enough disks available for stripe to happen.
Remember, objects can be striped across disks within a disk group but also across different disk groups in the same or even a different hosts.
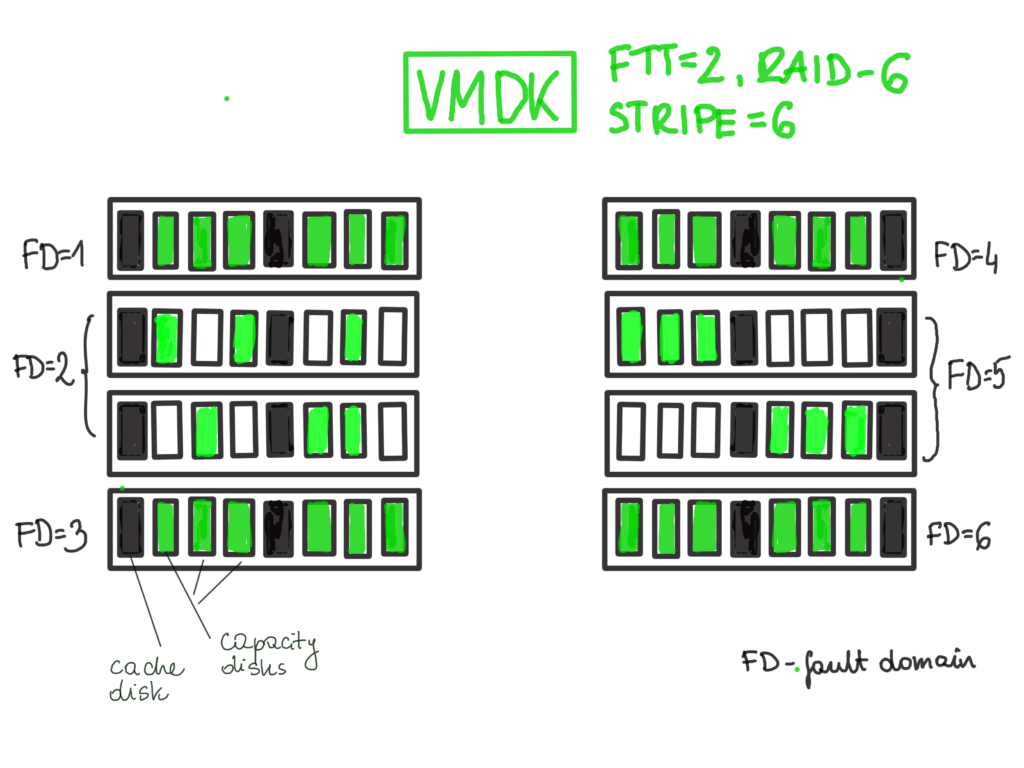
Now, let’s see a different example, this time we have more hosts and erasure coding. Stripe also works together for RAID-5 and RAID-6 polices.
In this example we have 8 hosts. VMDK uses RAID-6 policy (min. 6 hosts are required for this). Imagine we have just one VM with only one VMDK that uses this 8 hosts exclusively. With STRIPE=1 the components of VMDK would be placed on 6 hosts only and 2 hosts will be “empty”. STRIPE > 1 will increase the probability that components will also be placed on other hosts and more disks (cache and capacity) will be used for better disk utilization.
I marked hosts in the middle as FD=2 and FD=5 just to emphasize that they have components of the same object for this particular VMDK.
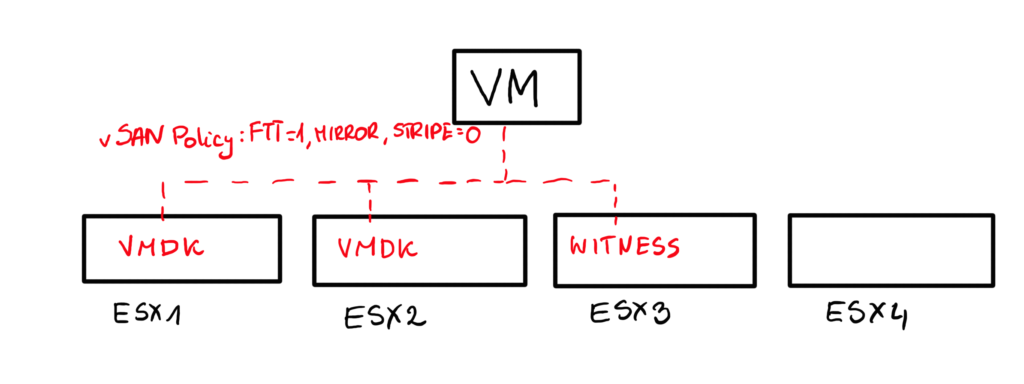
Usually when we use a basic SPBM FTT-1 mirror policy and there is no stripe involved, we end up with 2 copies of the data on 2 different hosts and additionally a component metadata on a third one per each object to avoid a split brain scenario.
Like in this example below – two VMDKs on ESX1 and ESX2 and witness metadata on ESX3. For other objects placement will be probably different.
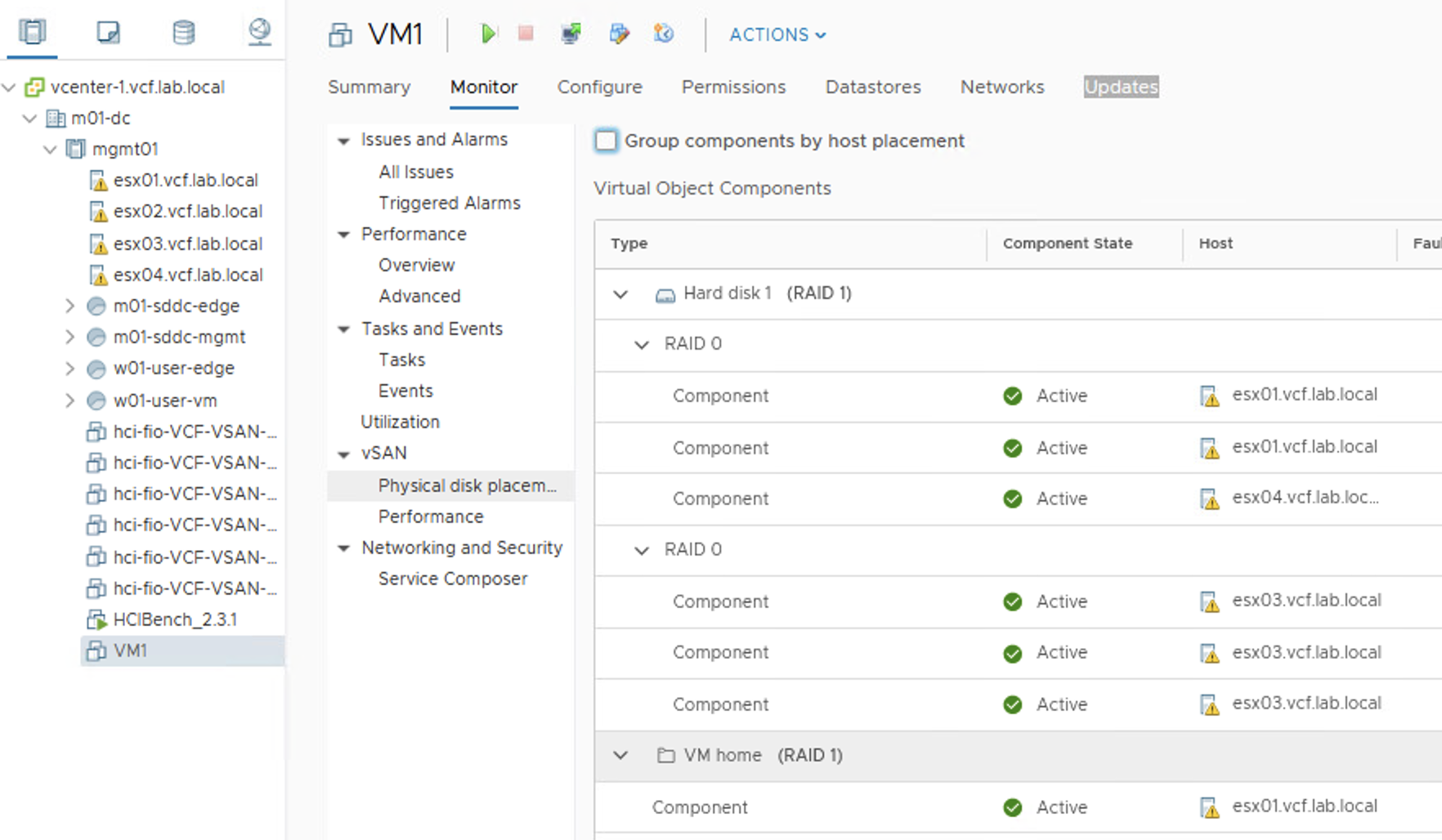
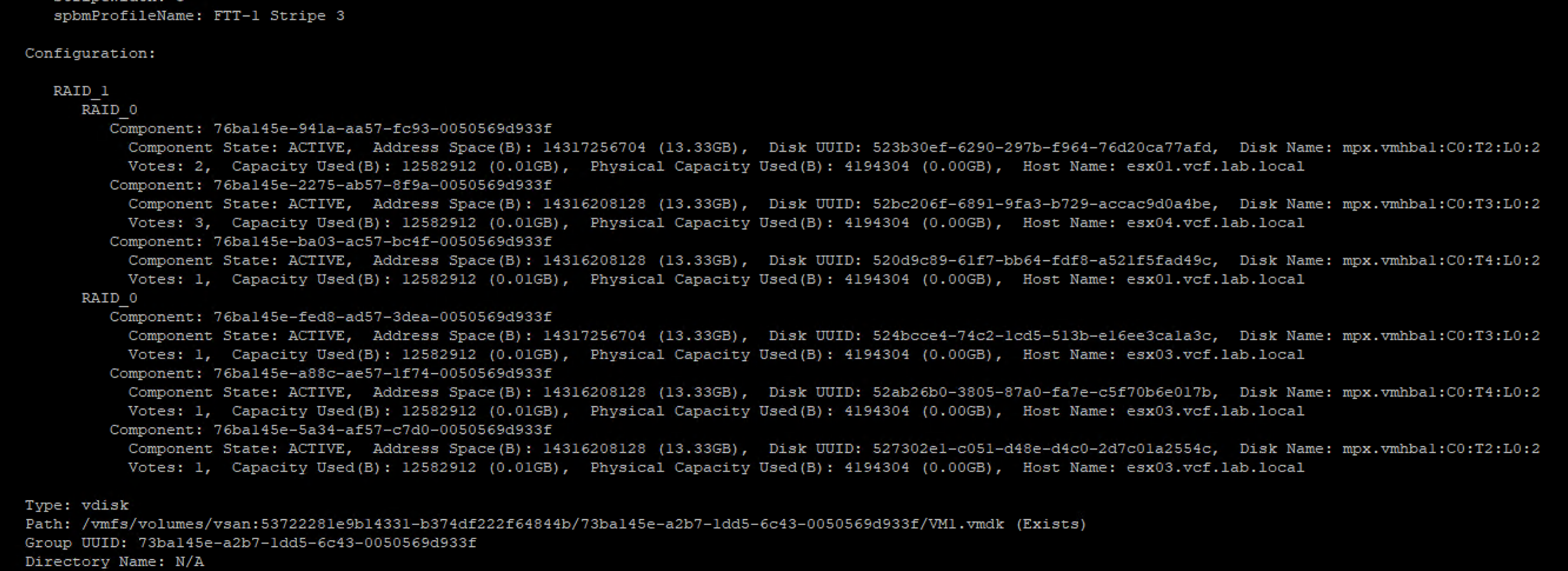
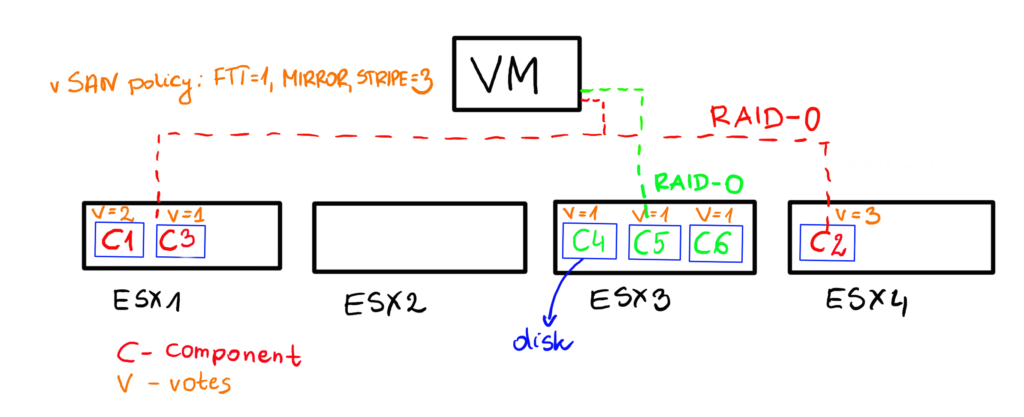
But this is not always the case. When objects are striped, witness metadata may not be needed. Here is an example of FTT-1, stripe=3 policy. One of VMDK objects is striped into RAID-0 on ESX1 and ESX4 (on 3 different disks ) and RAID-0 on ESX3 (on 3 different disks).
Here is how it looks like from the vote perspective: on ESX3 all three components have V=1, component on ESX4 has V=3 and components on ESX1 have V=1 and V=2.
In this case there is no witness metadata component required because this component distribution and votes prevent split brain scenario.
By the way, the component placement is done by vSAN automatically, we do not have to worry about votes and metadata components. But still, it is good to know how it works.
Reading Release Notes for vSAN 6.7 U3 you might overlook a very important improvement that was introduced with this release: Increased hardening during capacity-strained scenarios.
“This release includes new robust handling of capacity usage conditions for improved detection, prevention, and remediation of conditions where cluster capacity has exceeded recommended thresholds.“
The question: what happens when vSAN datastore gets full, is a very common one but rarely we have an option to test it. Every admin knows that monitoring free space on EVERY datastore is critical but it doesn’t mean we are not curious how the system reacts when datastore gets full.
Long story short – vSAN has always handled it very well but with 6.7 U3 we get lots of additional new guardrails. I always wanted to test it and now I have some time to do this.
How to fill a datastore with data? Usually I am using HCI Bench that creates lots of VMs with lots of thin provisioned VMDKs and let it run for a while.
First signals
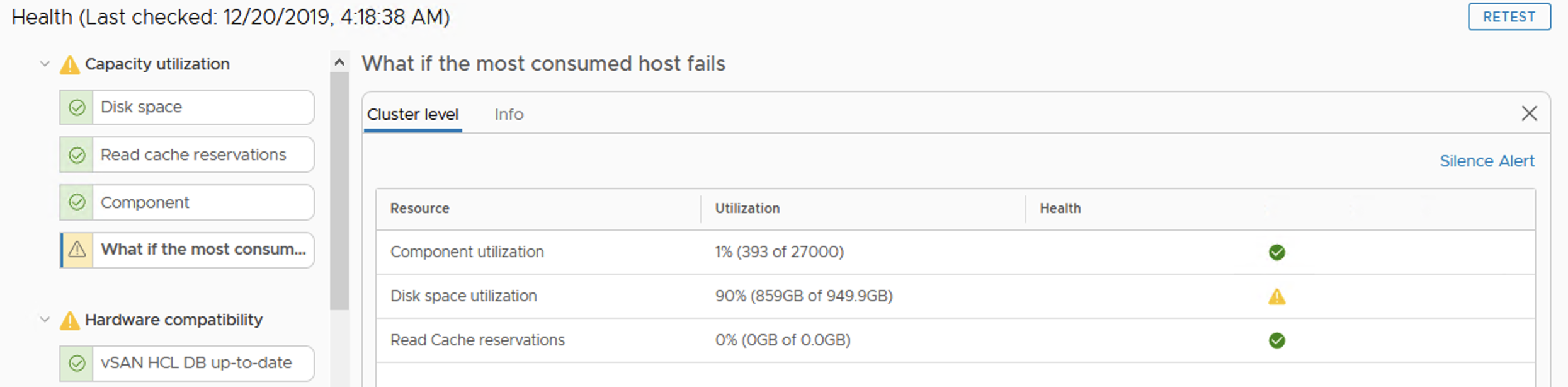
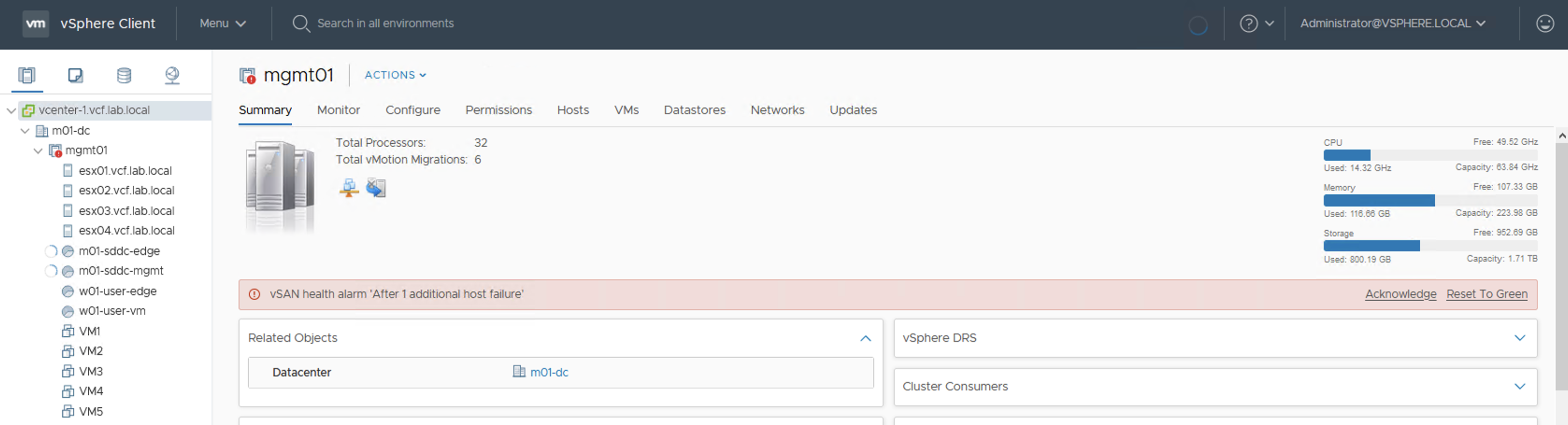
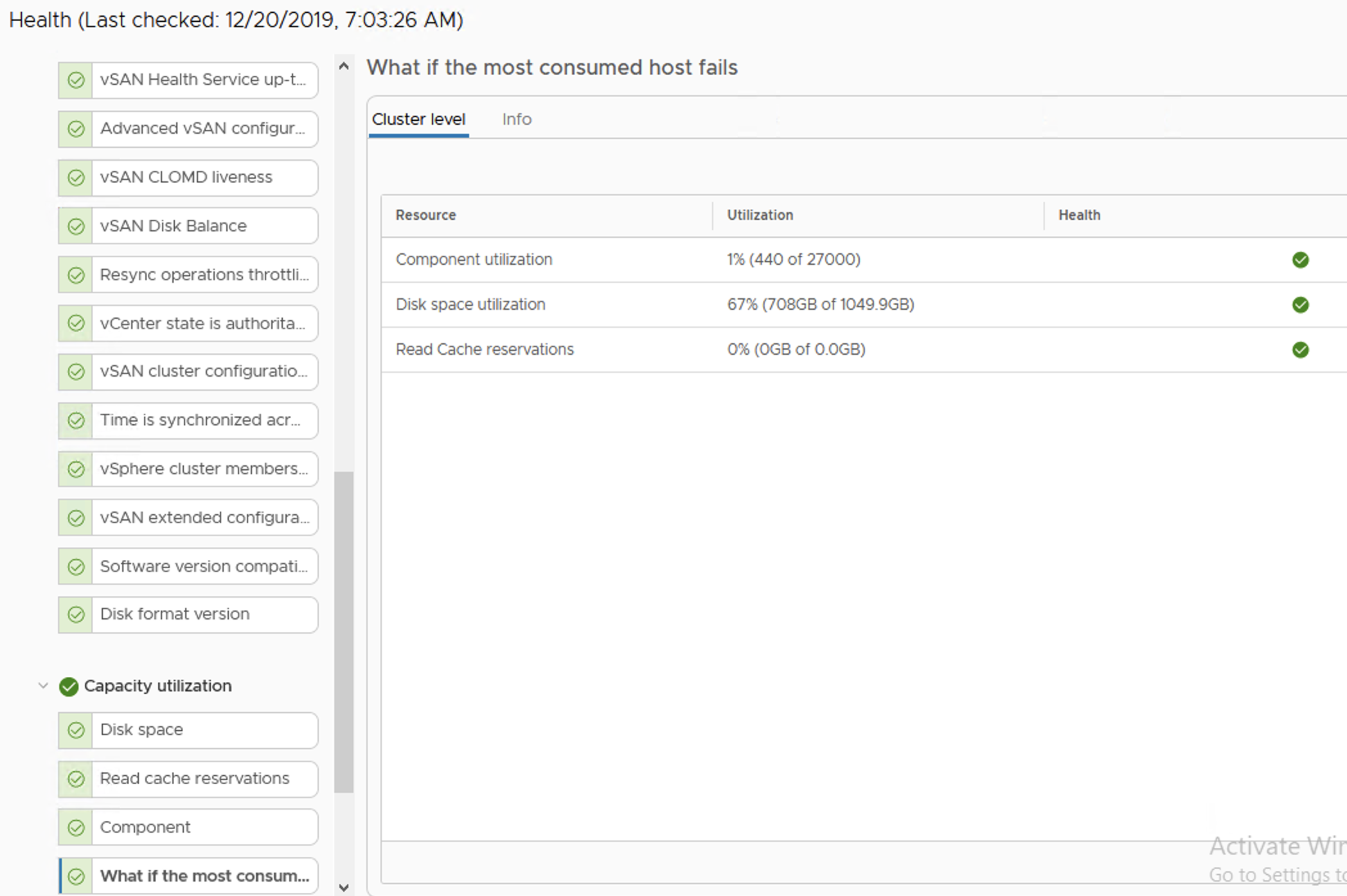
We are informed in a very early phase that something is going on with our datastore. vSAN Health shows a Warning that if we now loose one of the hosts in a cluster, disk space utilization will be high.
vSAN HealthvCenter view
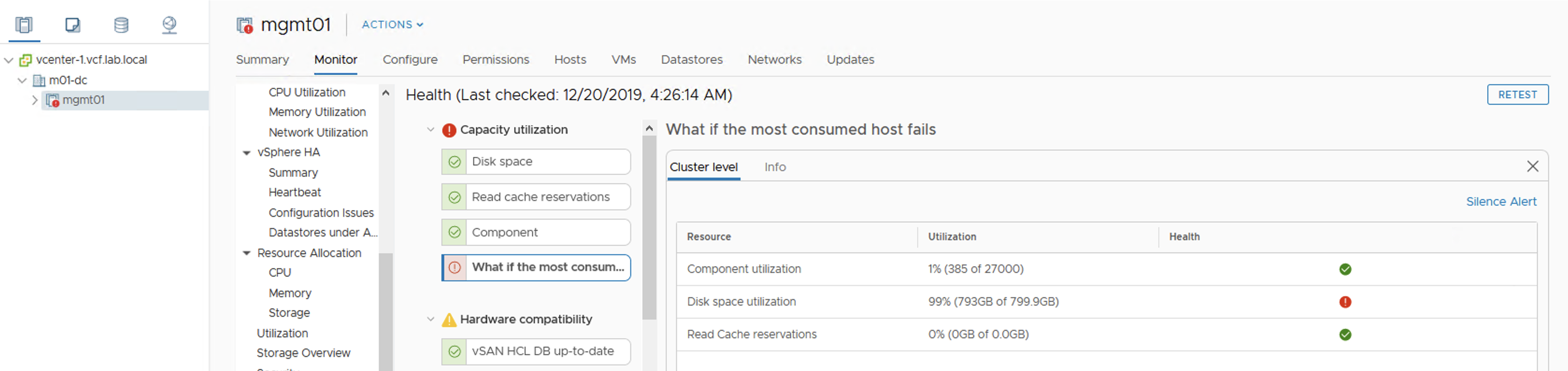
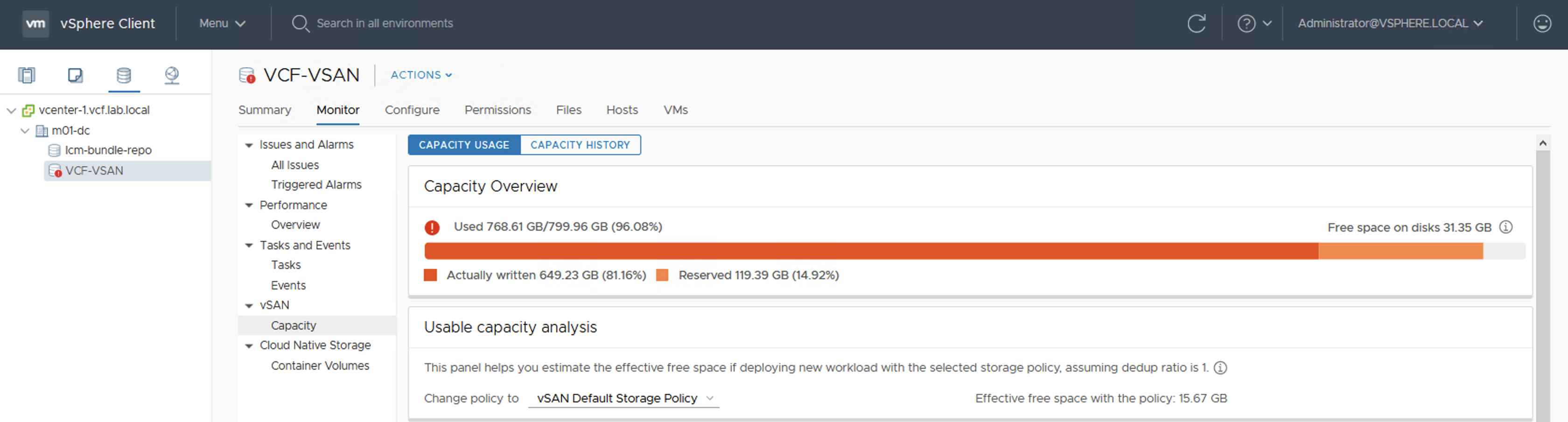
Because more data is filling up this datastore, a Warning turns into an Error. With one host offline there will be no free space on datastore to create VMs. Datastore size doesn’t seem to be full now but this is a summary of all of the datastores in the cluster, not only the vSAN datastore.
End now a very popular datastore alarm appears: “Datastore Usage on disk”. It is the same for VMFS and for vSAN.
Datastore viewvSAN Capacity Overview
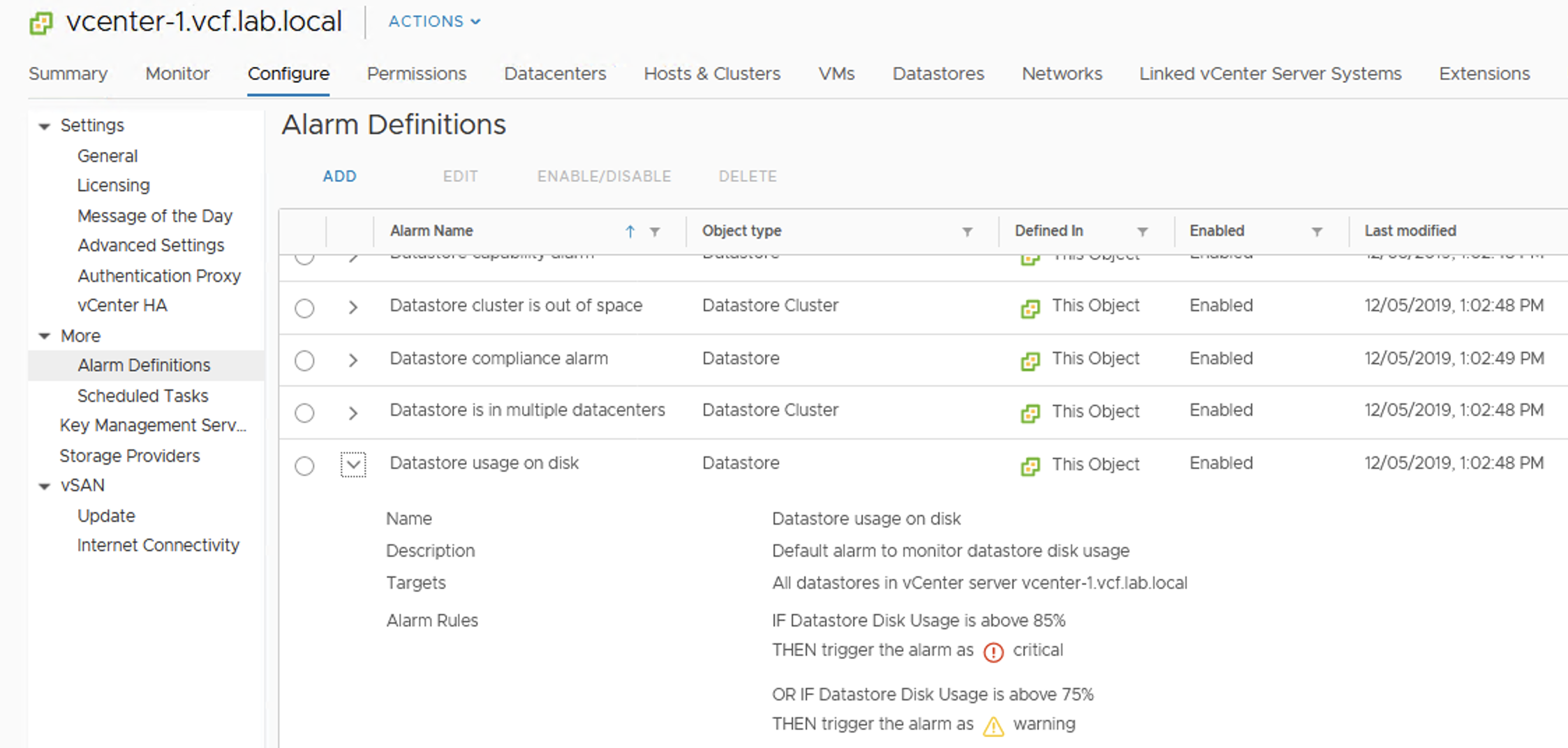
If we do not modify alarm settings, we will get a warning at 75% usage and Critical at 85%.
vCenter Alarm definitions
And here it is …
Datasore view and vSAN Capacity view turned red.
It is getting serious
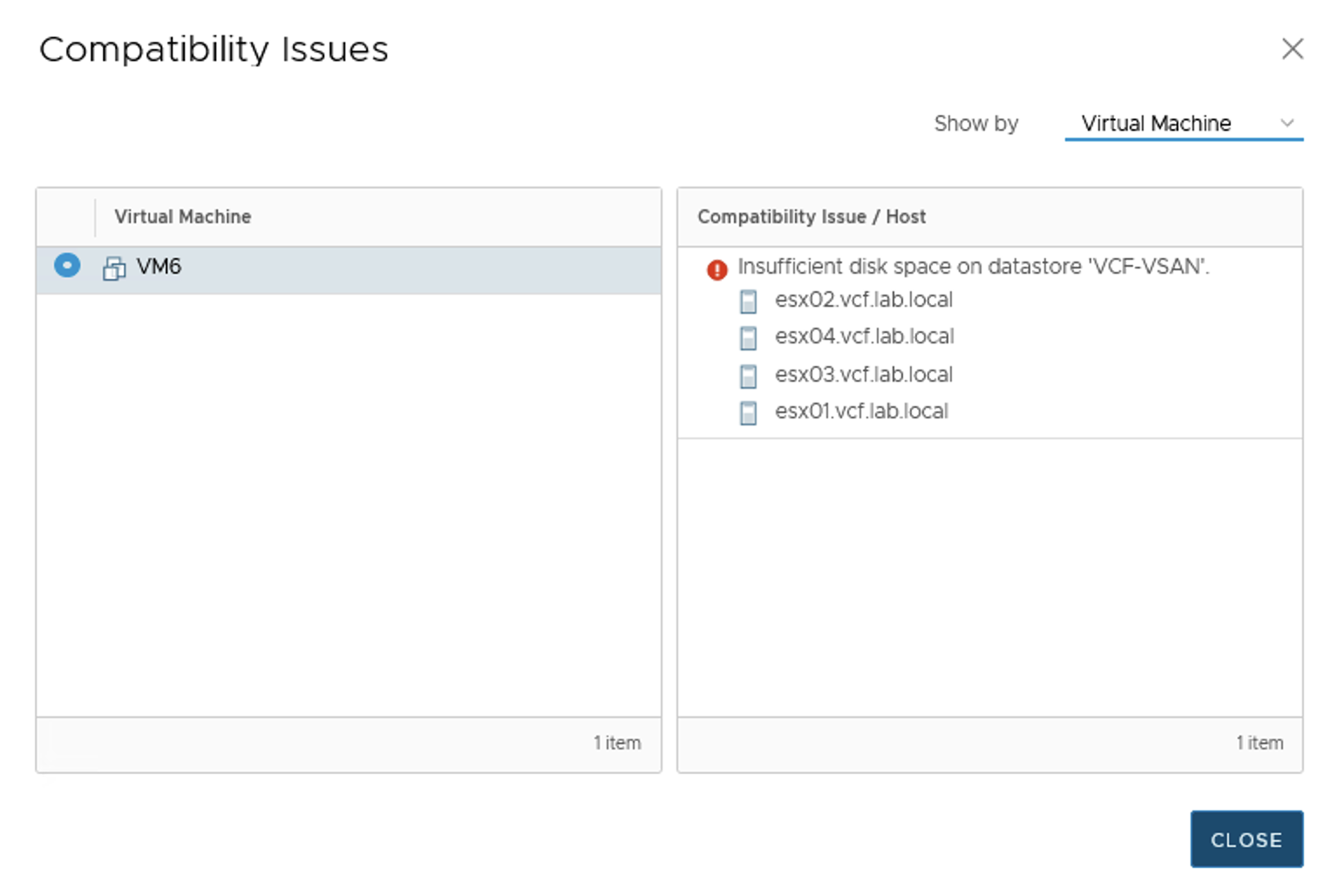
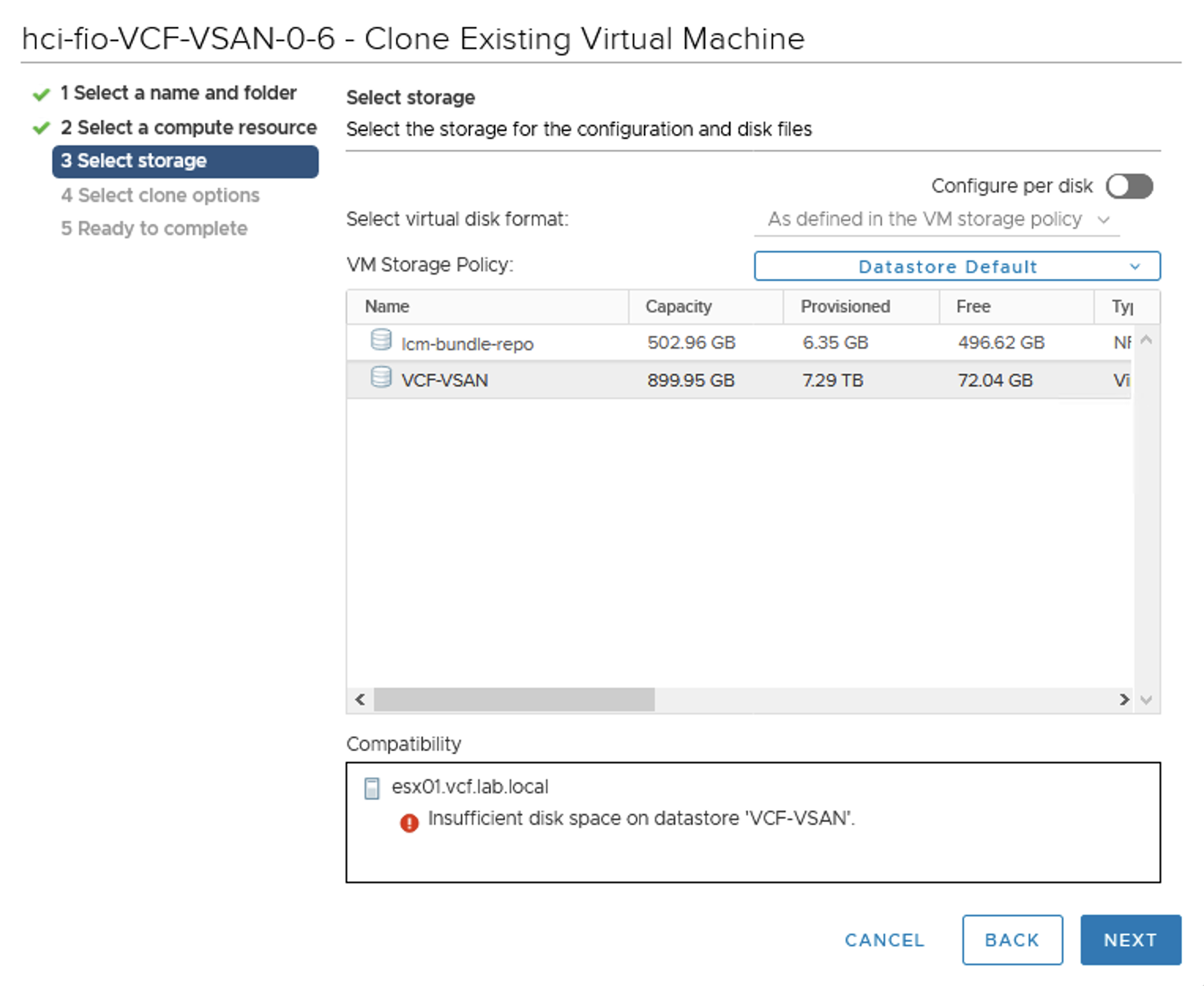
VMs are working fine (especially those that do not write to disks much) but at this point we will not be able to create new VMs (+ FTT-1 mirror policy requires 2 copies of data ).
Or clone a VM.
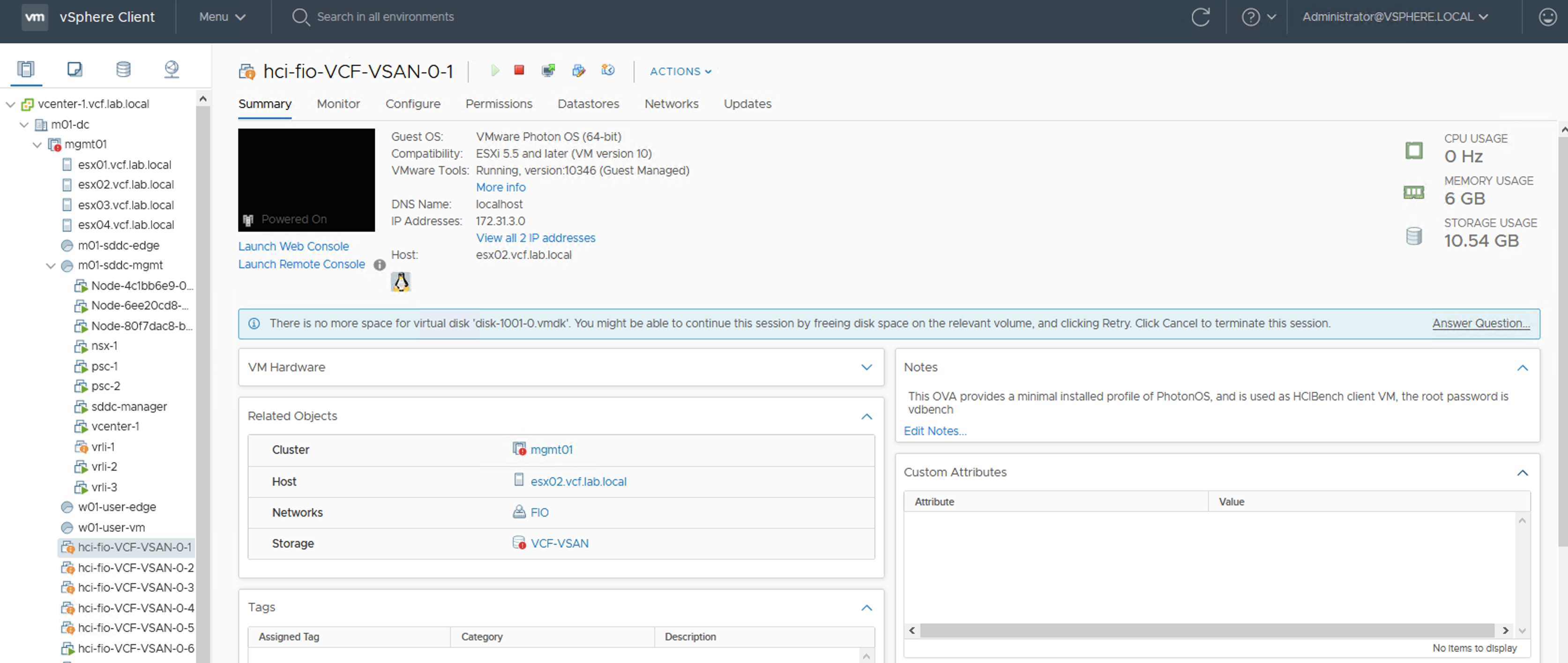
Now some of thin provisioned VMs are stunned. I deliberately run fio 100% sequential write test on them to invoke this process. It looks like datastore full test affected also my vRLI VM that was probably writing new datastore full logs on its VMDKs. Other VMs run fine.
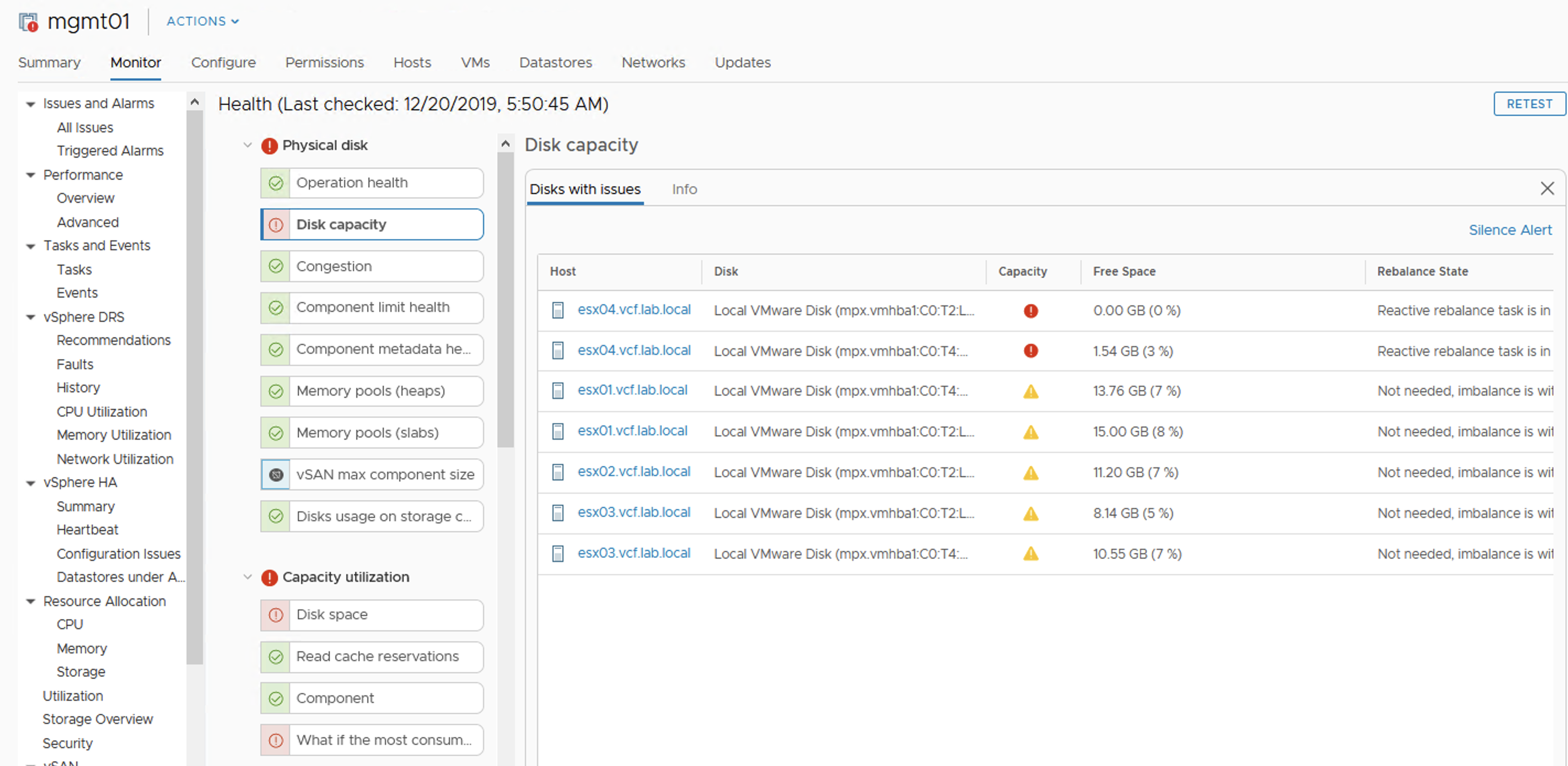
Quick check on vSAN Health:
At this point rebalancing is scheduled but not running, because datastore is getting full so there is no point in doing this. It looks like vSAN will not allow to get 100% full, it queues some activities. Hosts are fully responsive, vCenter as well. I am able to power off VMs, run some management activities. Well done vSAN!
Datastore is almost full, but objects are healthy
Ultimate test
Ok, let’s get one of the hosts offline. I was not able to evacuate all data from the host because of the lack of free space, so I used “Ensure Accessibility” option. Objects are still Healthy but some of them that had components on the esx04 have just lost one copy. I tried to force rebuild them, some of them actually did rebuild but then process paused. vSAN really guards the last free GBs for the sake of the health of the whole cluster.
How to get out of it?
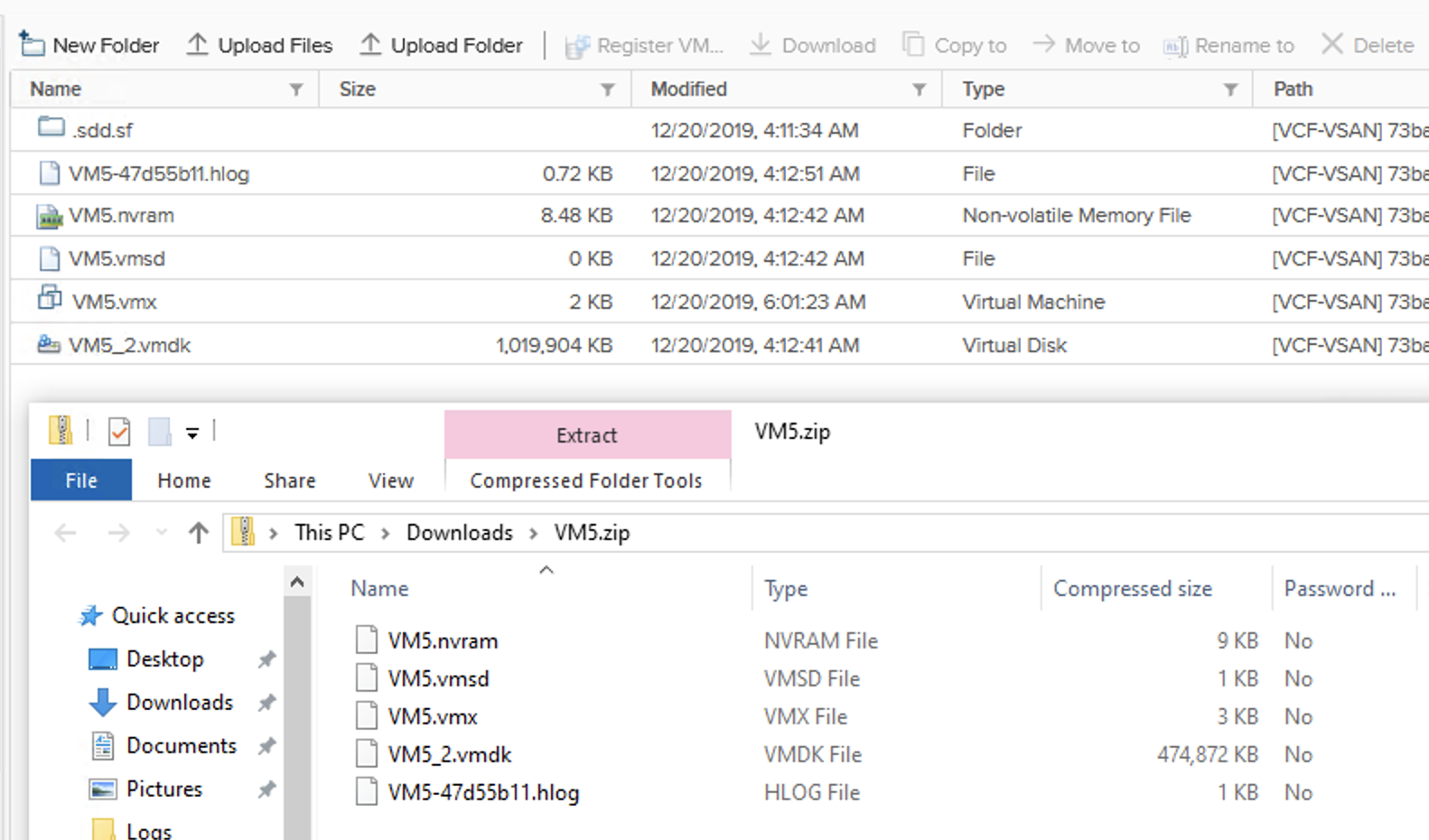
Exactly the same way like we do with VMFS. We can power off some VMs (free some swap, but it is thin provisioned so this may be not enough), we can delete VMs (bad idea in production) but we can also…download a VM from vSAN Datastore. In 6.7.U3 it finally works! 😉
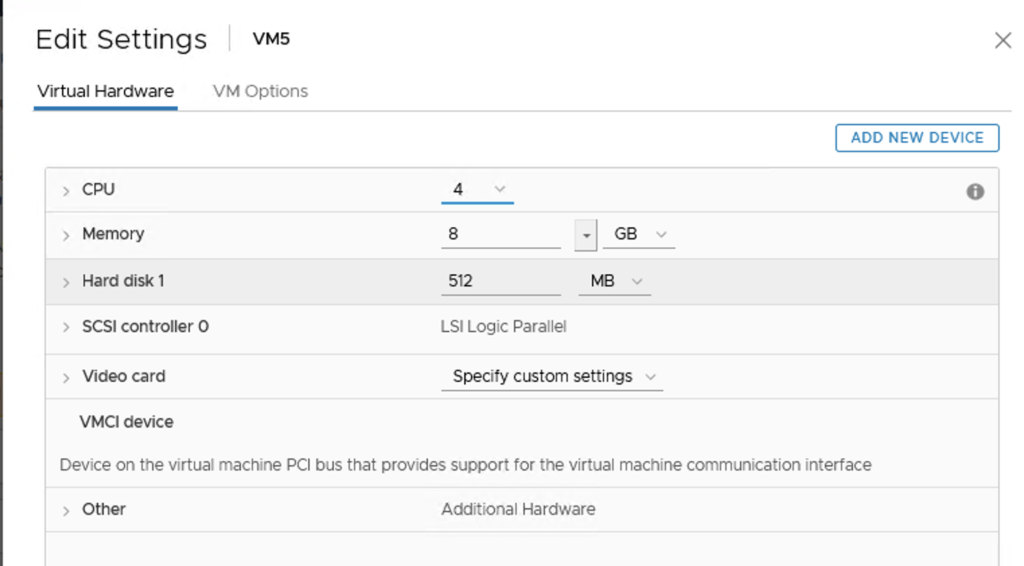
The VMDK on the datastore will be twice as big as downloaded one for VMs with mirror storage policy. My VMDK is around 500MB.
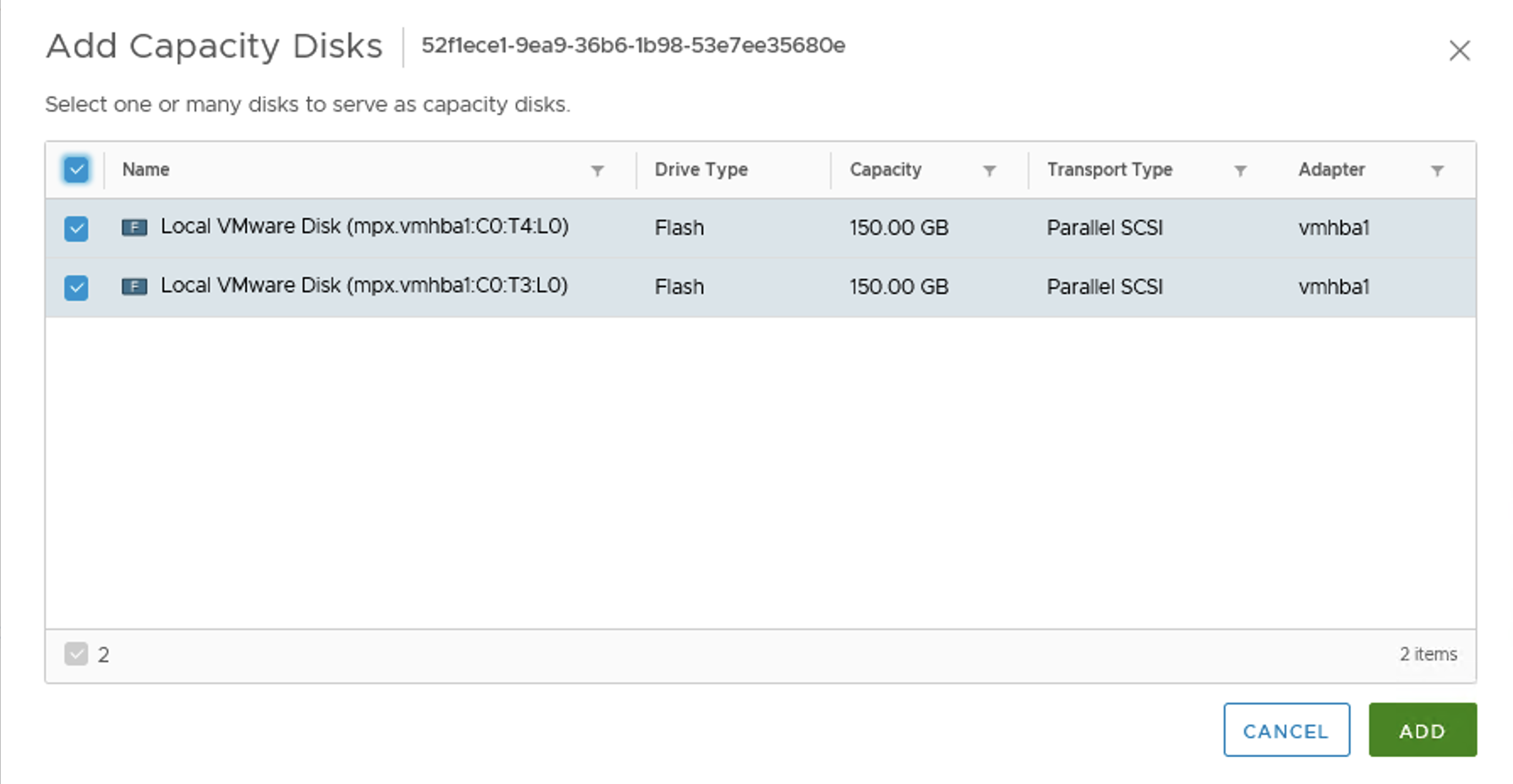
We can also add capacity disks to our vSAN disk groups to get more free space.
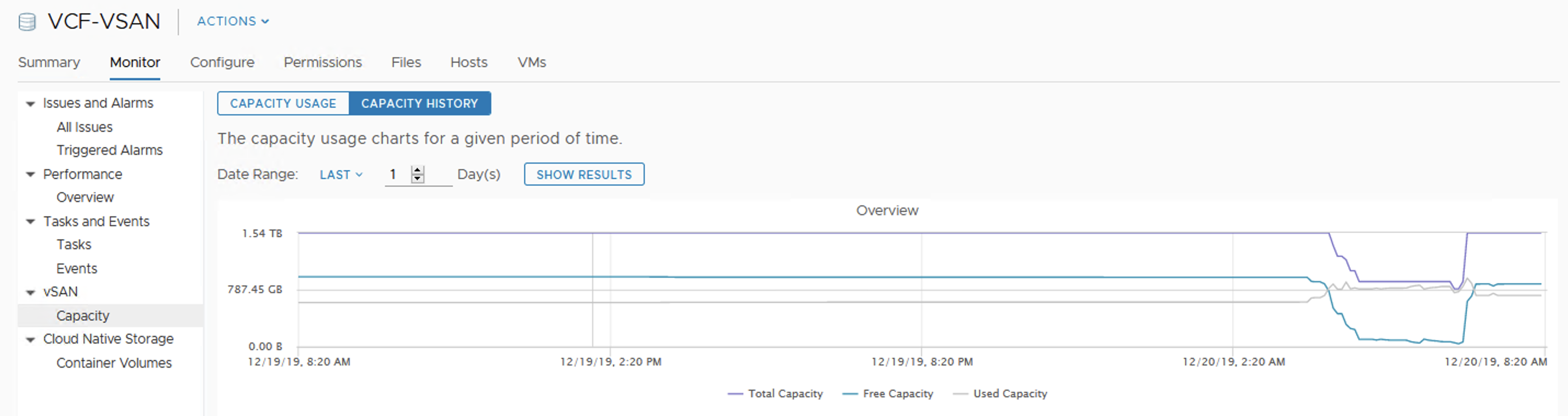
vSAN capacity history
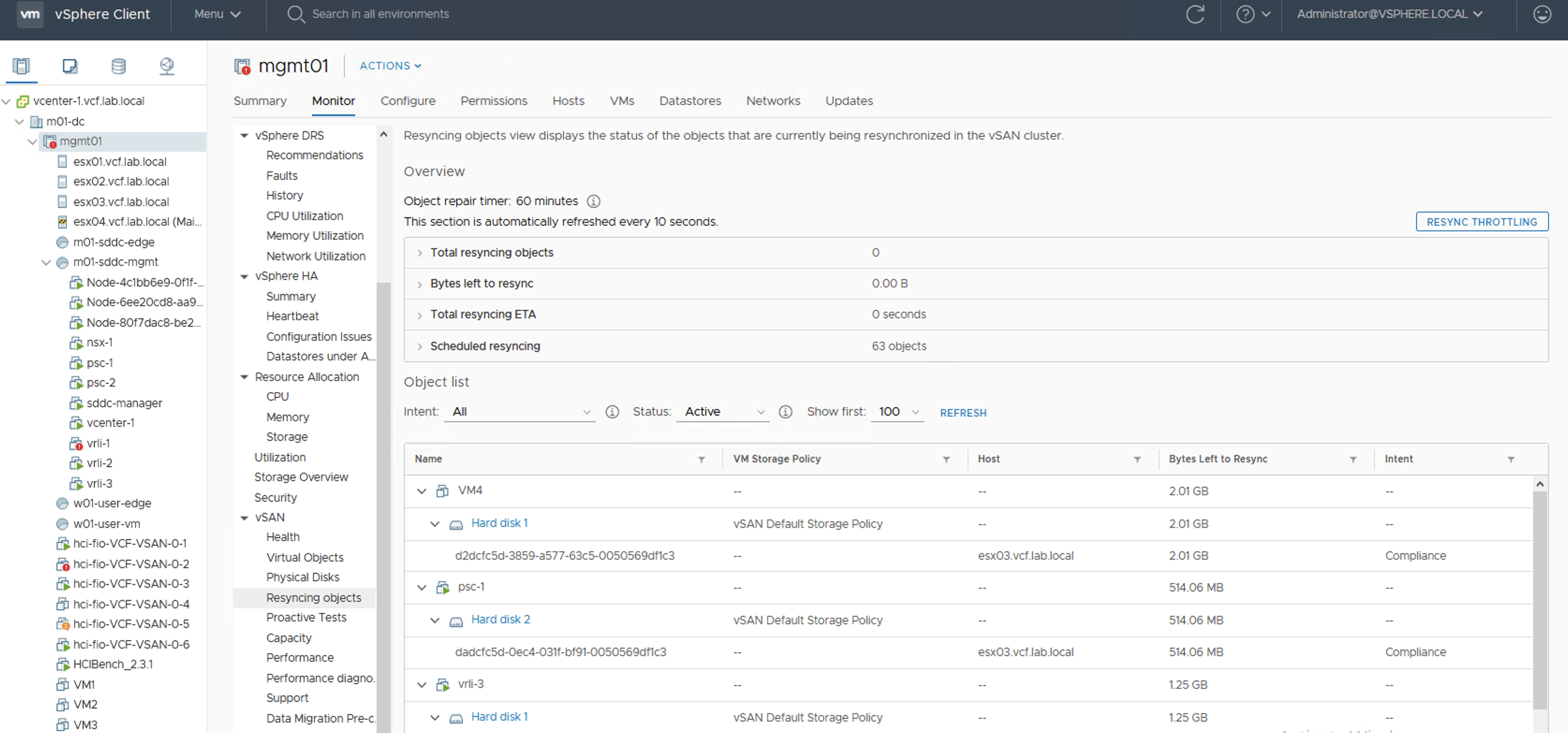
After we add disks the reaction of the cluster is immediate. We get more space, paused resync jobs start again, still in a controlled way, not all of them at once. Depending on our disk balance policy, rebalancing kicks in when certain threshold is exceeded.
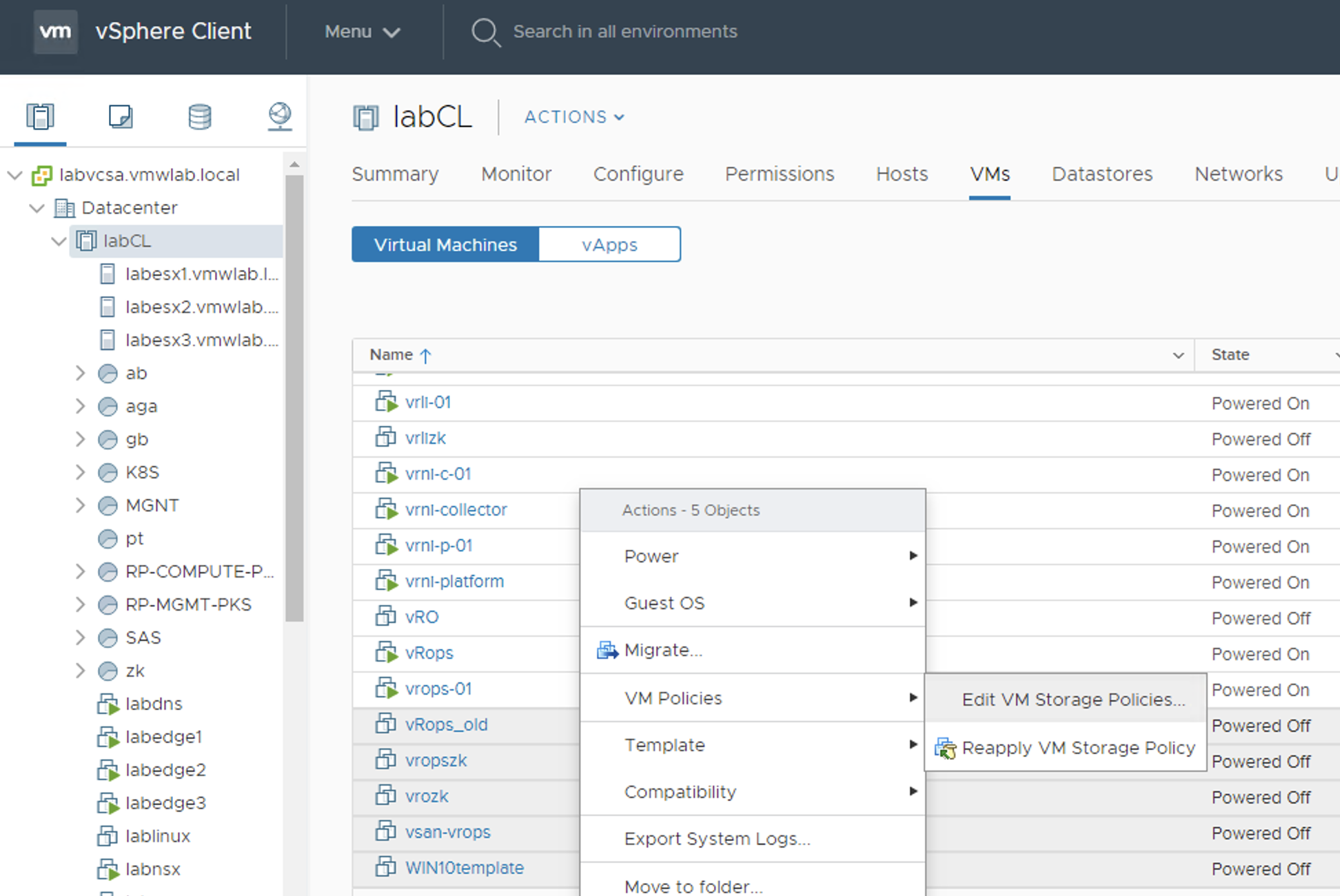
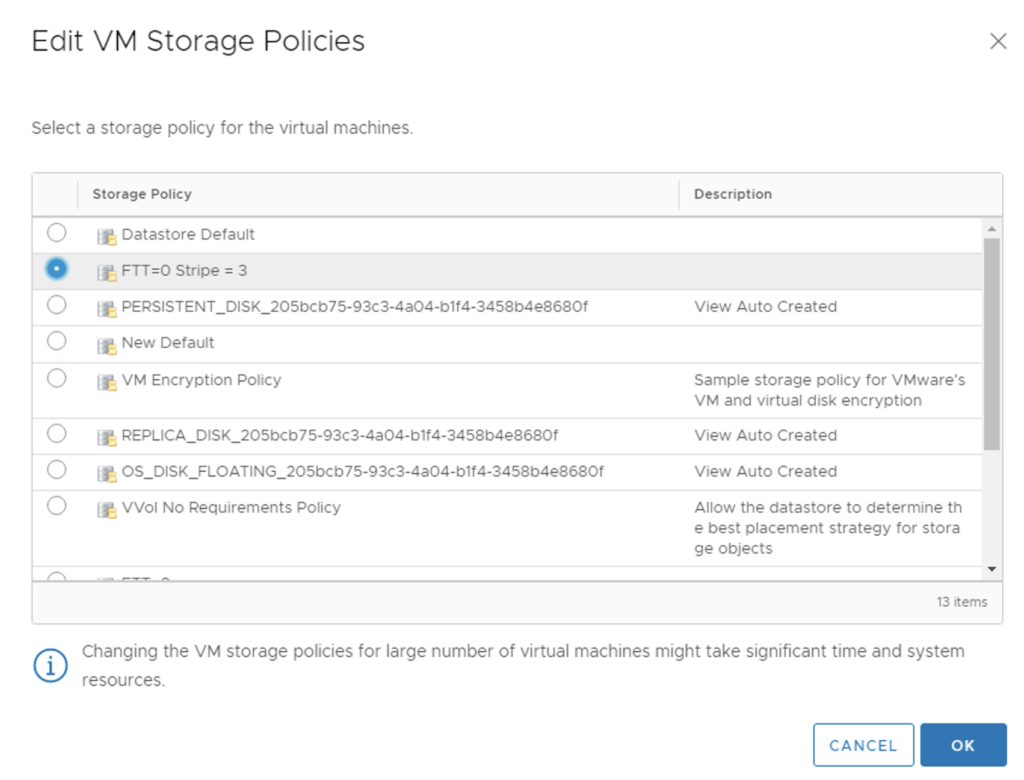
Imagine we have 100 VMs with VMDKs attached to a vSAN Default Storage Policy (RAID-1) and we want 20 VMs to move to a new FTT=0 Stripe-3 storage policy. We can create a new policy and apply it to VMs one by one. It may be a reasonable approach not to change it for all 20 of them at once…but if in vSAN 6.7U3 VMDKs are finally processed in batches, we could give it a try 😉
So the trick is simple. We go to the VM folder on the Cluster level and use Shift to select desirable number of VMs. Obvious, isn’t it?
There is one caveat though – we will not be able to select SPBMs on VMDK level, storage policy will be applied for all of the selected VMs for all of their VMDKs.
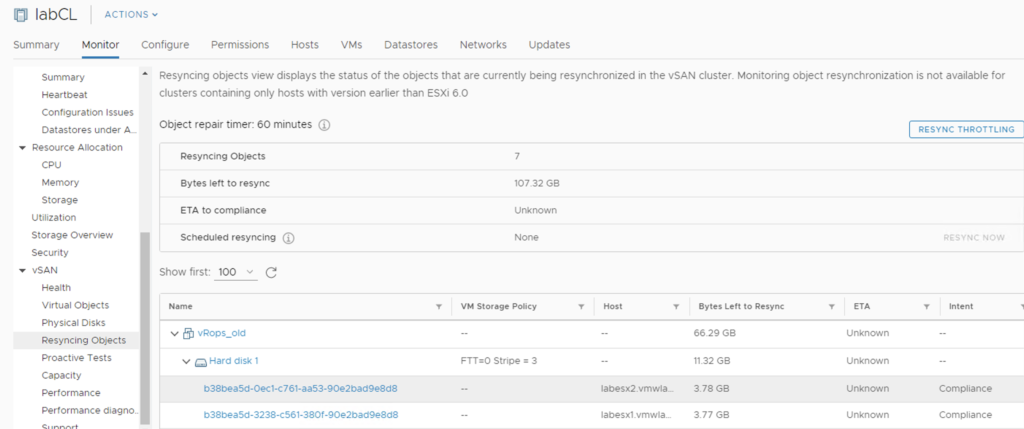
And than we can wait and observe our resync dashboard.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.