For Zerto users, maintenance work on ESXis has always been a challenge. Zerto’s Virtual Replication Appliances (VRAs) are pinned to their dedicated hosts, so when we put a host in Maintenance Mode , VRAs can’t be auto-evacuated. VRAs even shouldn’t be evacuated as they can only work on their dedicated hosts. If the vSphere cluster is on-prem, we have many options to address this issue. We can power off VSAs, delete them, force migrate etc. We can stop and resume replications to make sure our data is consistent.
But in a public cloud with a shared responsibility model, a cloud provider is responsible for all maintenance work on ESXis but they don’t have access to your Zerto application. Imagine a situation when a cloud provider needs to replace or upgrade an ESXi node that is still operational and they want to evacuate this host. With VRA being pinned to the host, this evacuation won’t work for them. Cloud provider probably also will not want to power off a VRA appliance because they know it will break your replications. This situation can seriously delay every maintenance work on an ESXi in a public cloud.
What can you do as a Zerto admin if you are using a public cloud as your replication target?
It turns out Zerto offers a very nice feature called Workload Automation. You can enable it in the Site Settings of Zerto Virtual Manager (ZVM).

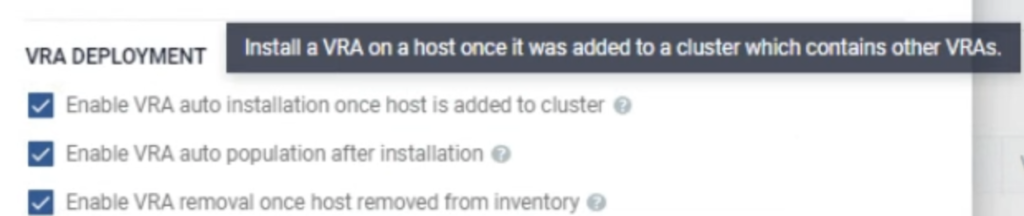
Workload Automation can detect when a host is entering MM and can “evacuate” (=power off) a VRA in such situations. It can also detect when a host exits MM and bring back a VRA into an operational state. Thanks to this feature, a cloud provider can perform any maintenance work on your hosts and it won’t break your Zerto’s setup.


There are also other very useful options. When a new node is added to a cluster (due to auto scaling policy or a node replacement), Zerto will detect this and install its VRA there. When a node is removed from a cluster, Zerto will remove it from its inventory.
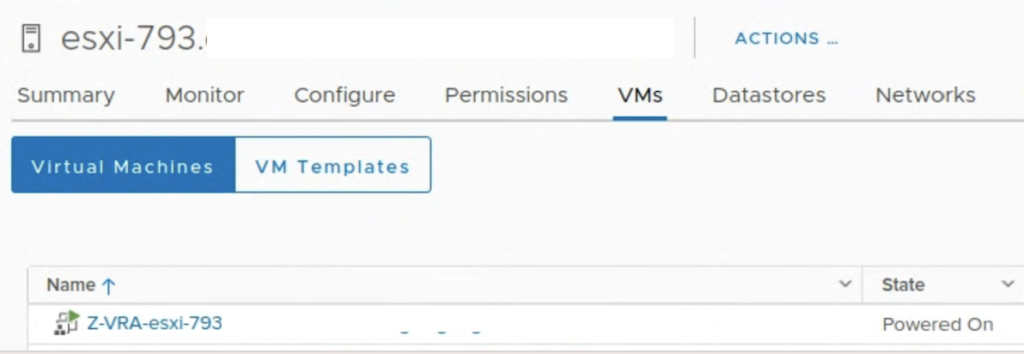
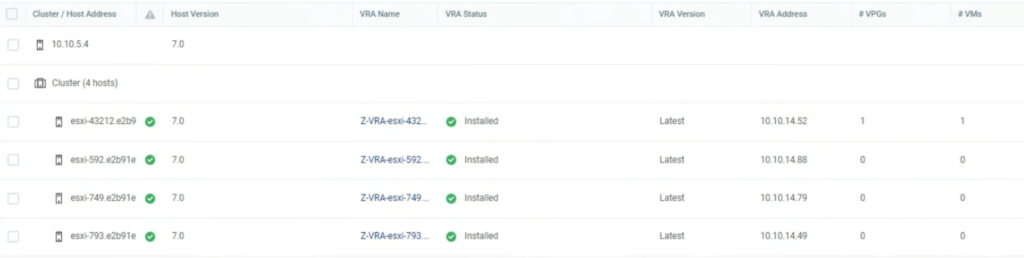
I run a simple test to check how it works. I used a 4 node vSAN cluster. When I put one of he hosts esxi-793 in MM, I noticed Zerto shut its VRA appliance down on this host.
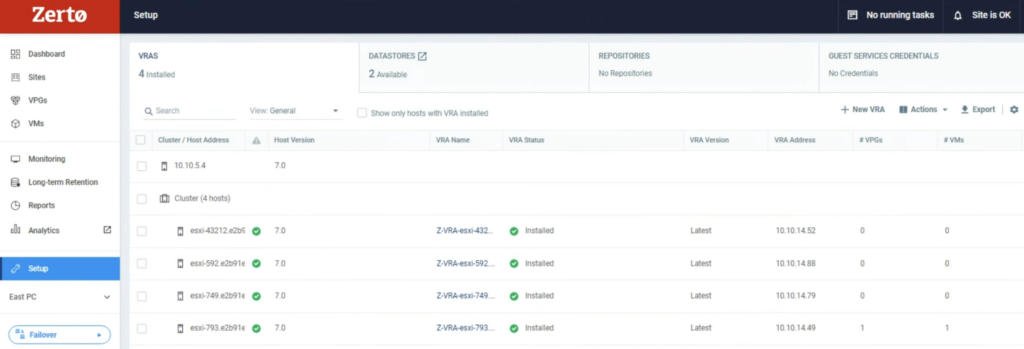

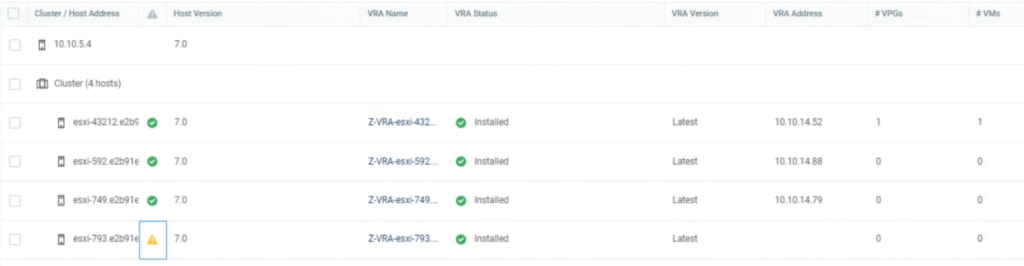
A new alert was raised in the ZVM UI console that one of its VRA appliances had been powered off.

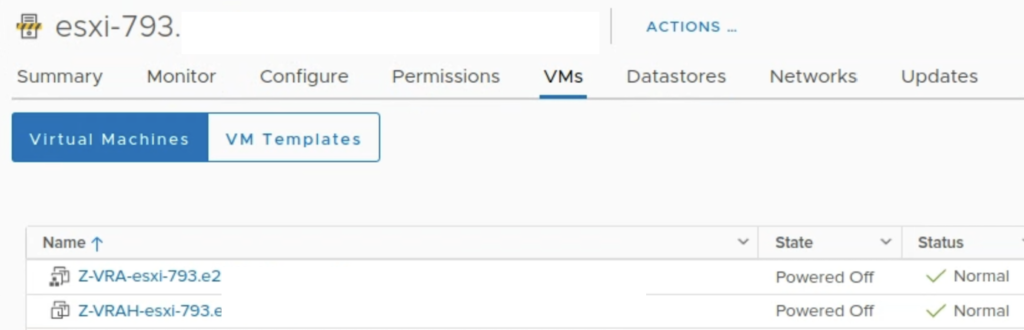
I also noticed Zerto powered off not only VRA but also a helper appliance: VRAH.
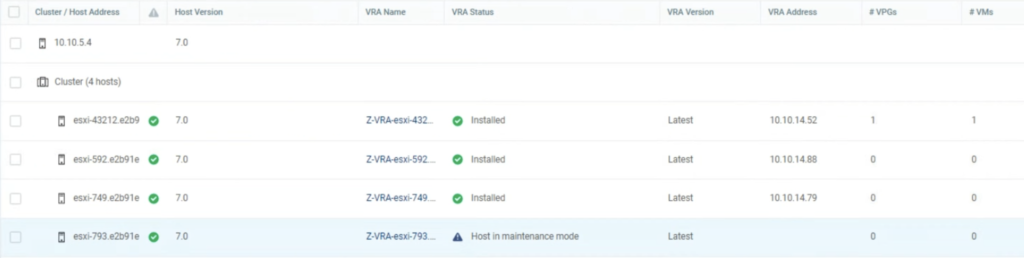
When I exited ESXi esxi-793 from MM, Zerto detected it correctly and powered on the appliances.
It seems Zerto Workload Automation is a must have option to be ON when you are running your Zerto in a public cloud and you don’t want to delay maintenance work of your hosts.