So usually with FTT-1 mirror policy we have two components of the object and a witness component. What do you think happens with a witness component when instead of FTT-1, FTT-2 SPBM policy is assigned to an object ? FTT-2 means our object can survive a failure of its two components. For a VMDK object it means there will be three copies of this VMDK and two can be inaccessible without affecting VM’s I/O traffic.
For FTT-2 there will be more than just one witness component…
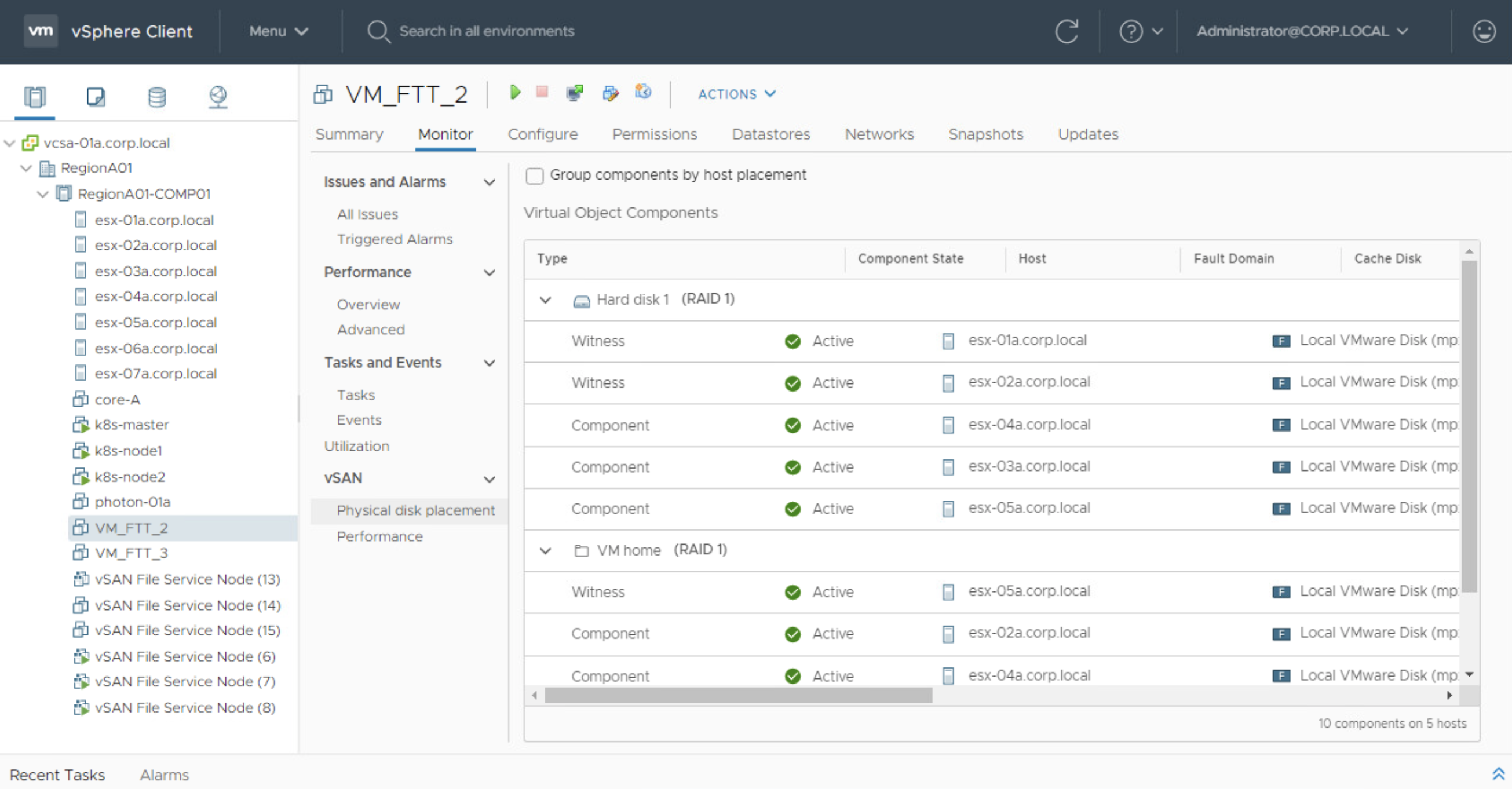
A VMDK will have three copies + 2 witness components. That is why FTT-2 policy requires minimum of 2n+1 = 5 nodes / ESXi hosts. And any two out of 5 can be inaccessible without affecting the service.
VMDK object with SPBM: FTT-2 mirror
How about FTT-3? FTT-3 means our object can survive a failure of its three components. For a VMDK object it means there will be four copies of this VMDK and three can be inaccessible without affecting VM’s I/O traffic.
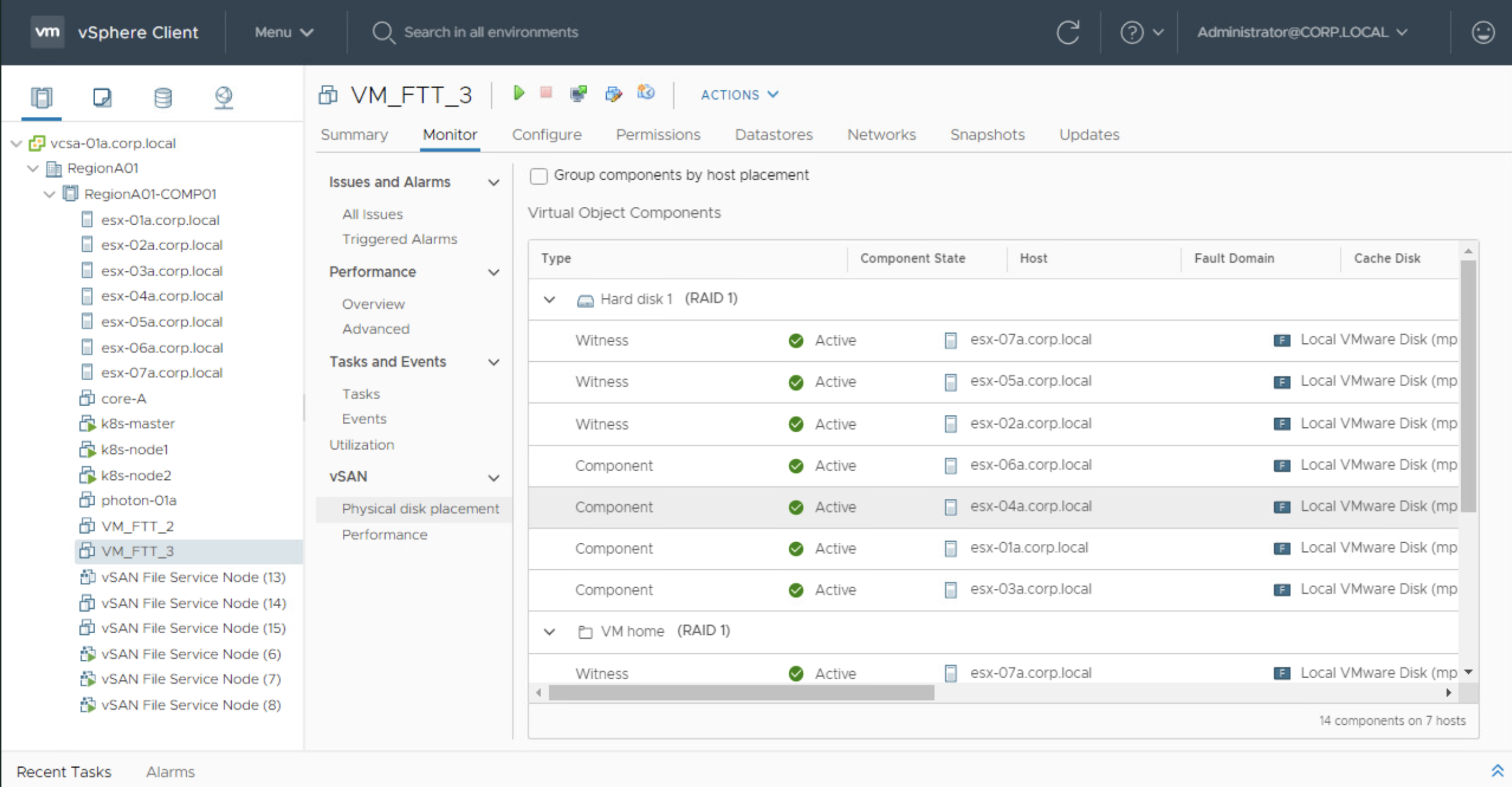
A VMDK will have four copies + 3 witness components. That is why FTT-3 policy requires minimum of 2n+1 = 7 nodes / ESXi hosts. And any three out of 7 can be inaccessible without affecting the service.
VMDK object with SPBM: FTT-3 mirror
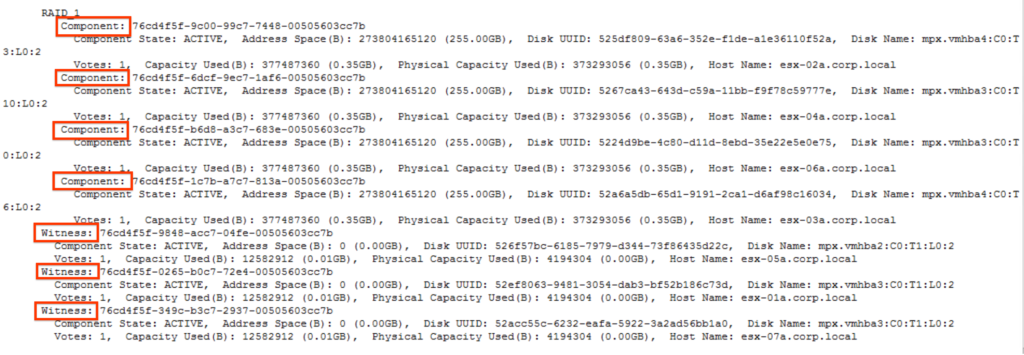
esxcli vsan debug object list is a command that can be used to list the components of the object , here is how it looks for a VMDK with FTT-3 SPBM policy:
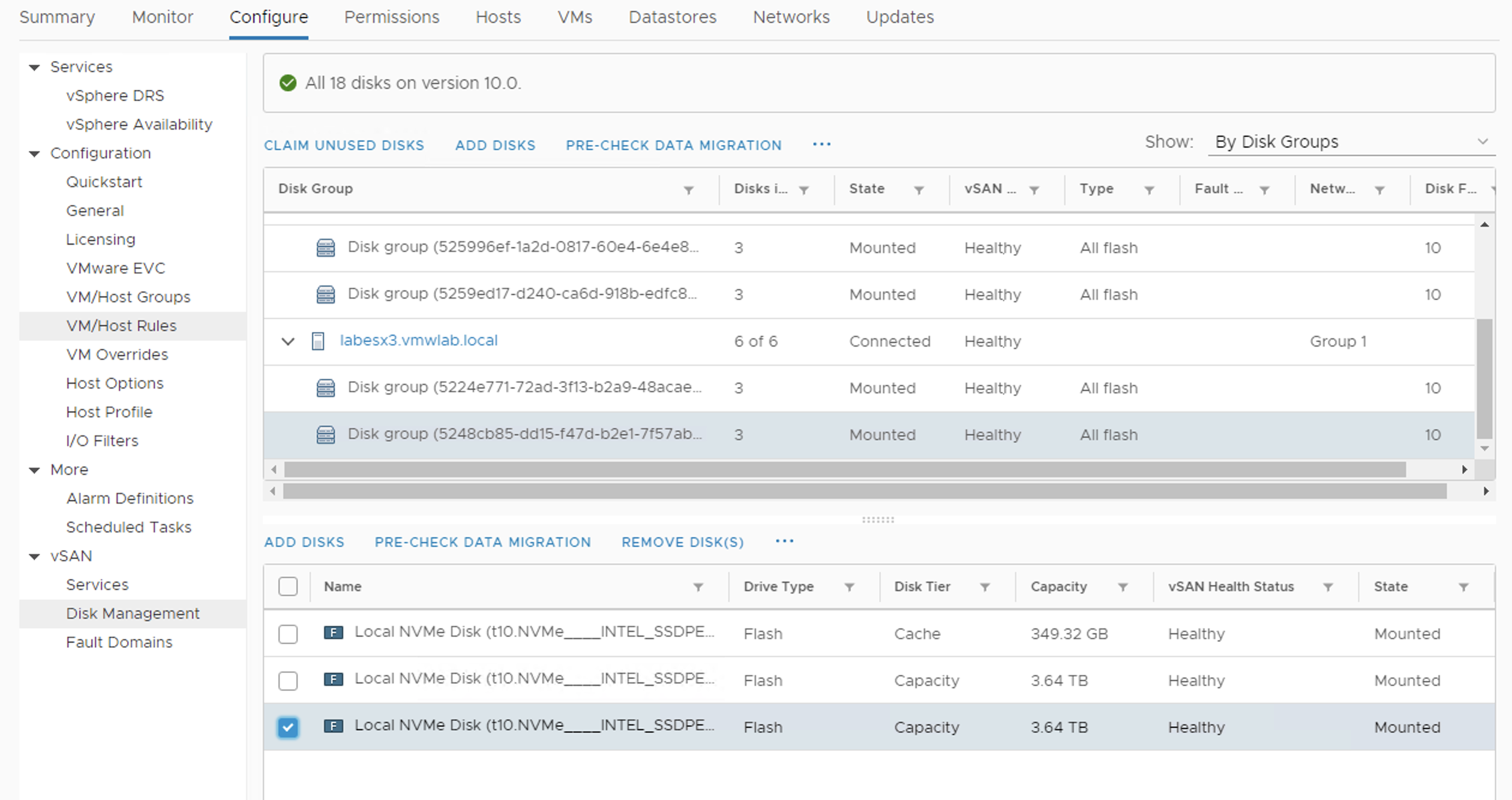
How quickly can vSAN evacuate data from my disk? Great question and of course the answer is “it depends”. On disks performance, network performance but also on the current I/O load of the cluster.
It seems there are a lot of dependencies, but vSAN has it covered. Resync dashboards, resync throttling (use with care), fairnes scheduler, performance dashboards, pre-checks and esxtop – all of those are there to make the data evacuation easier, regardless of the reason of the evacuation. It can be a migration to a larger disk, disk group rebuild or moving from hybrid to all-flash cluster.
Let’s check those tools.
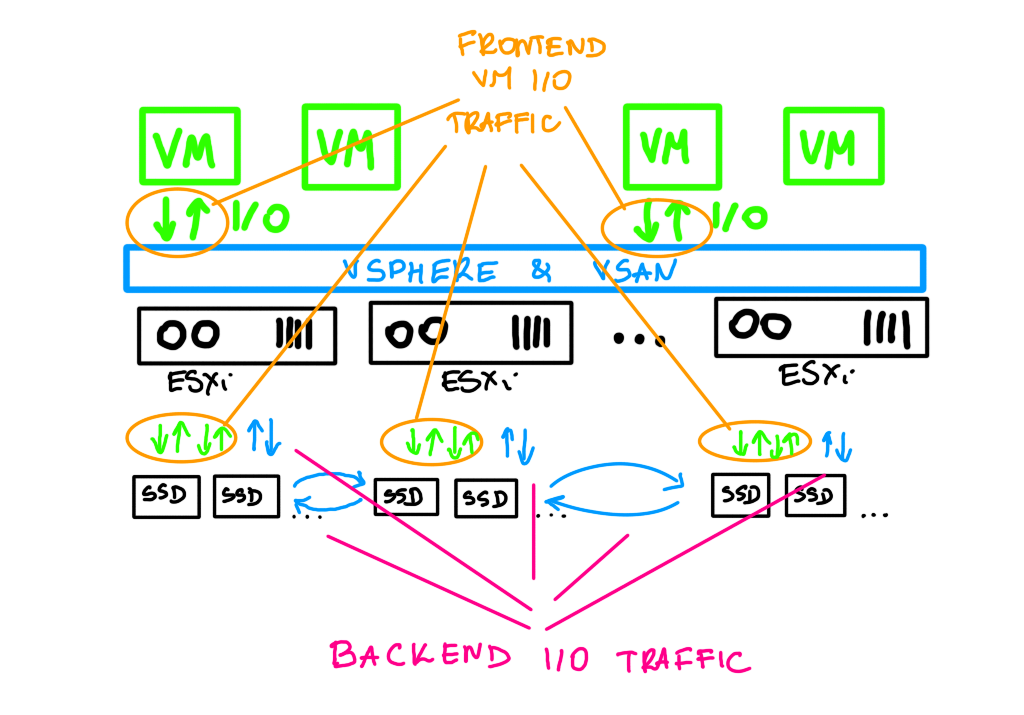
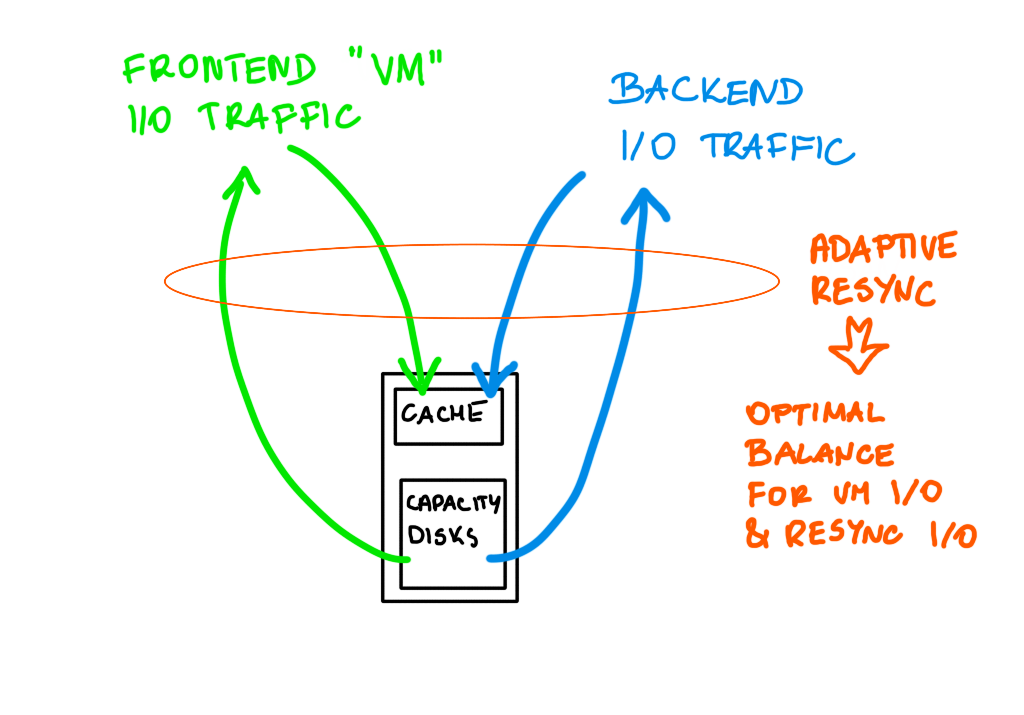
Fairness scheduler is a mechanizm that keeps a healthy balance between frontend I/O (VM I/O) and backend I/O (policy changes, evacuations, rebalancing, repairs). It is very important because the disk group throughput has to be shared between many types of I/O traffic and on one hand we want the resync to complete as fast as possible, on the other, it cannot affect VM I/O.
vSAN can distinguish traffic types, prioritize the traffic and adapt to the current condition of the cluster.
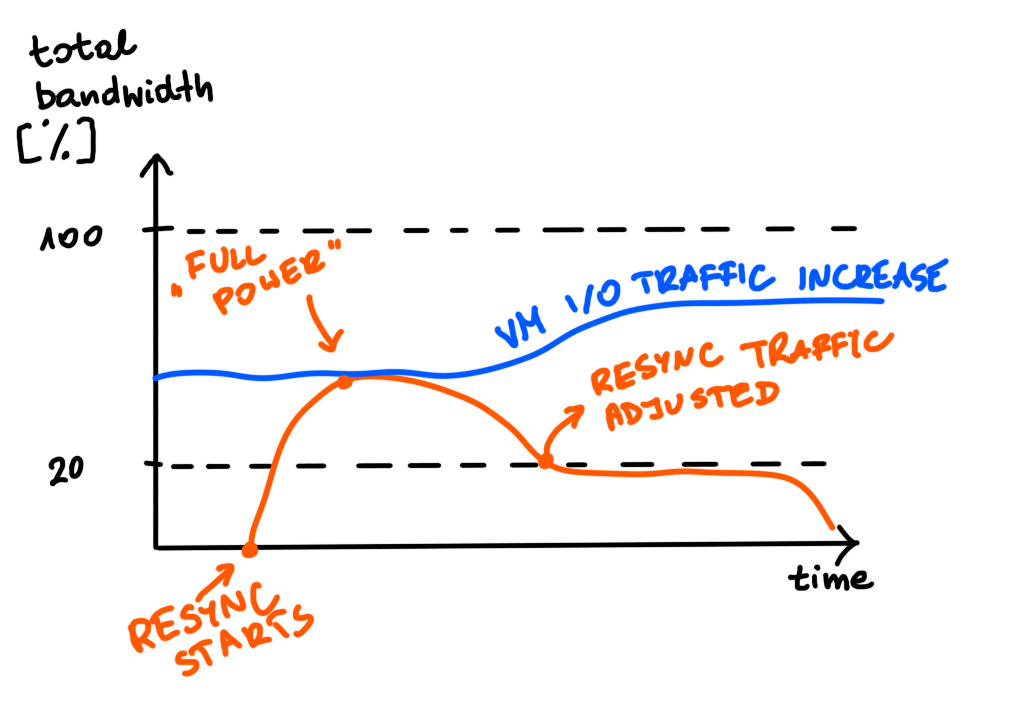
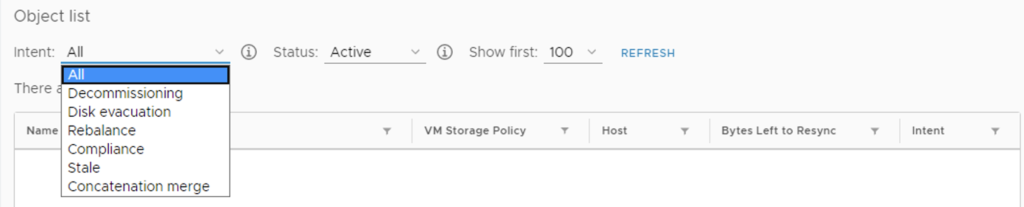
It is like in the picture below. If there is no contention, resync or VM I/O use “full speed”. If VMs need more of the disk throughput, resync I/O is throttled for this period of time to max 20% of the disk throughput.
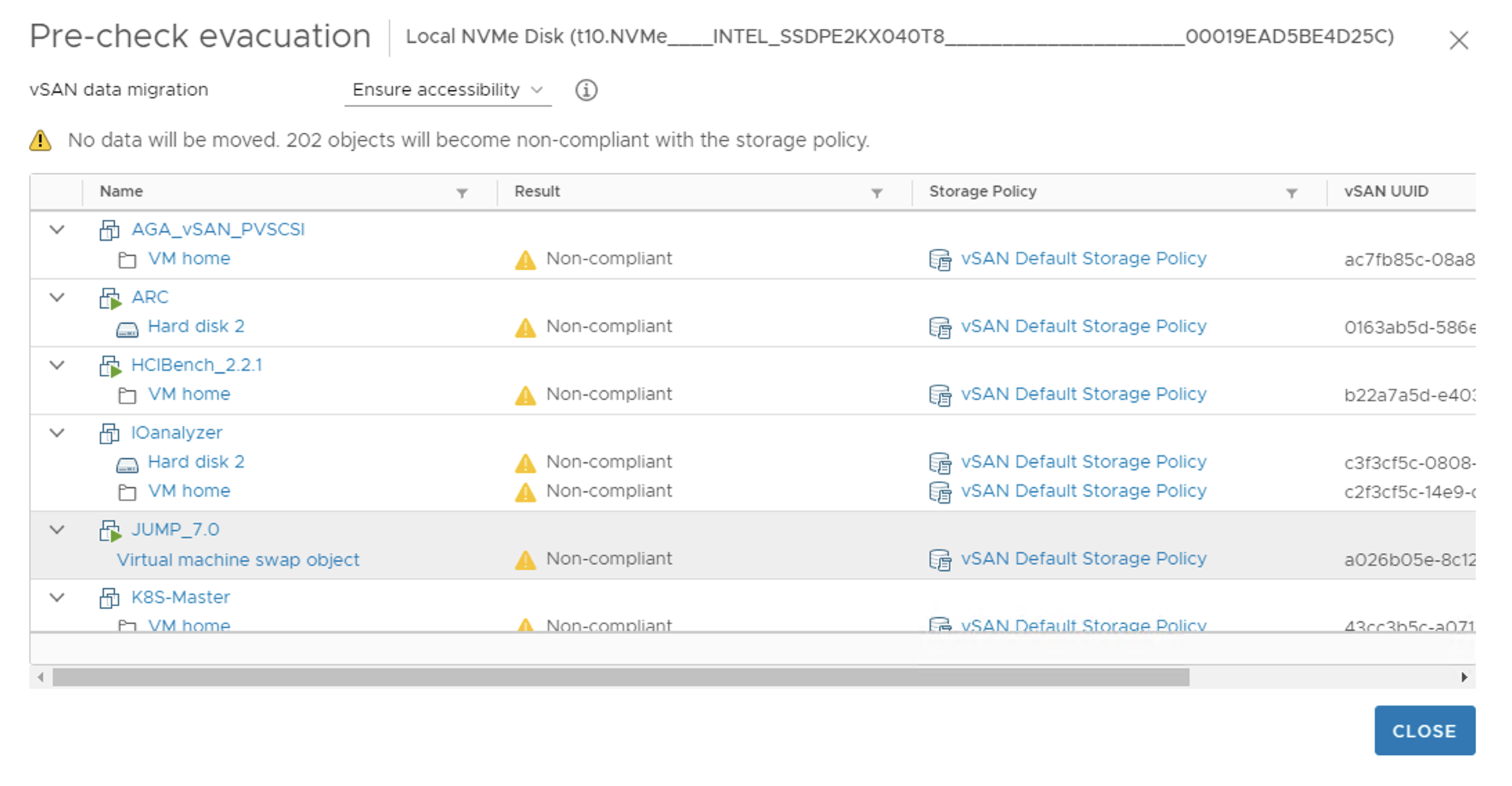
Pre-check evacuation option will help you to determine what components of the object can be potentially affected by the disk evacuation. You can select the preferred ‘vSAN data migration’ option: this can be a full migration, ensuring the accessibility of the object or no data migration at all.
The potential status of the components can vary. The pre-check will also let you know if you have enough space to move the data. Non-Compliant status of the object means the object will be accessible but it will not be compliant to the vSAN Storage Policy. At least for some time till the rebuild is finished.
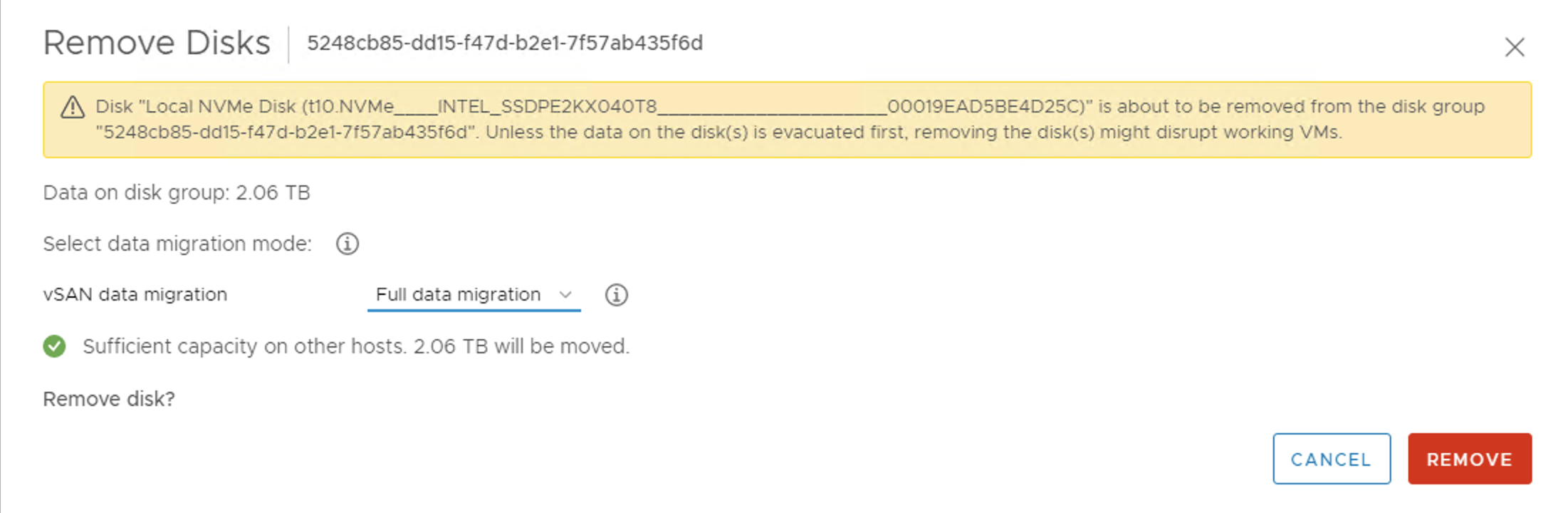
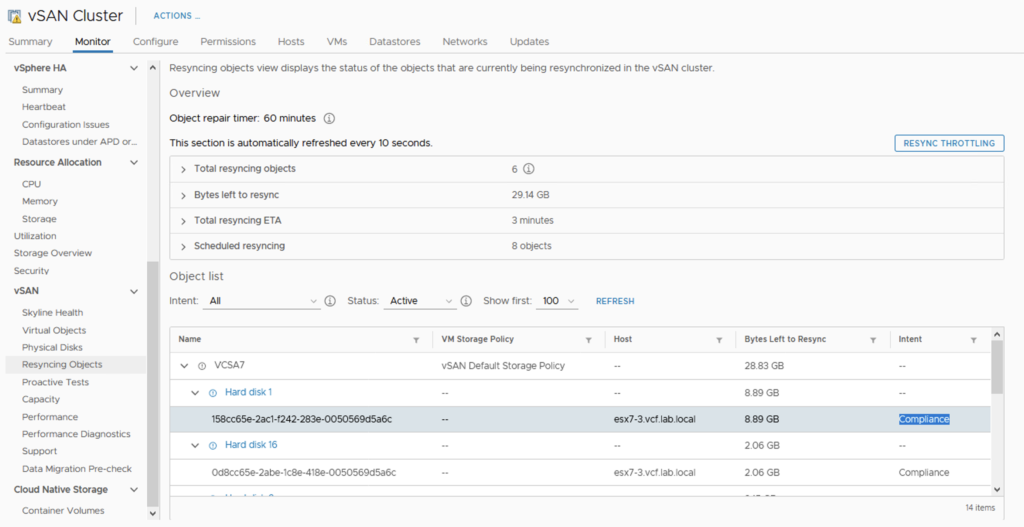
You can use resyncing objects dashboard to monitor the status if the vSAN background activities. With each activity you can check the reason for it. It can be a decommissioning like on the screen below when we remove a disk and evacuate data.
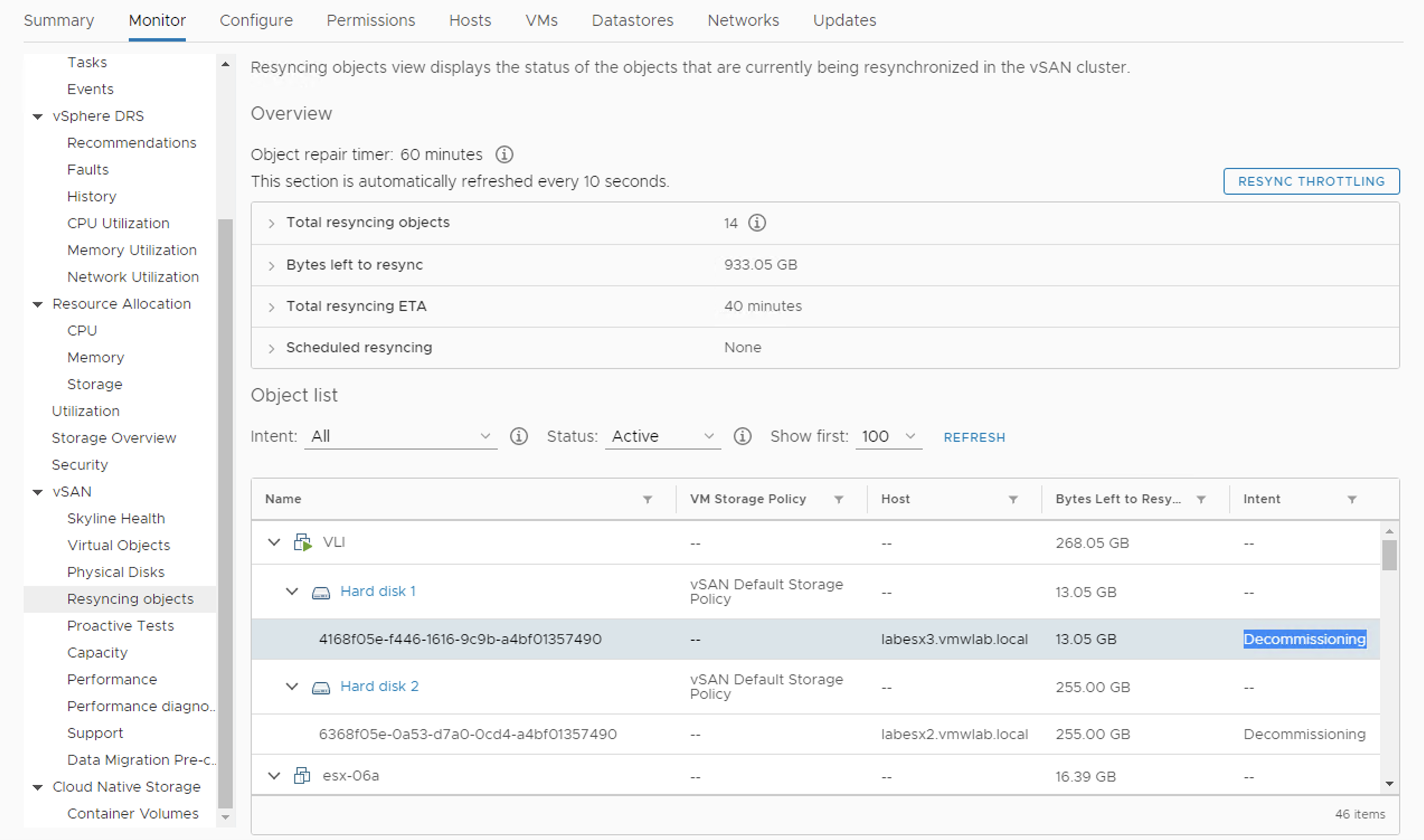
The full list of the reasons (from Resyncin objects tab):
Decommissioning: The component is created and is resyncing after evacuation of disk group or host, to ensure accessibility and full data evacuation.
Compliance: The component is created and is resyncing to repair a bad component, or after vSAN object was resized, or its policy was changed.
Disk evacuation: The component is being moved out because a disk is going to fail.
Rebalance: The component is created and is resyncing for cluster rebalancing.
Stale: Repairing component which are out of sync with it’s replica.
Concatenation merge: Cleanup concatenation by merging them. Concatenation can be added to support the increased size requirement when object grows.
You can also set Resync Throttling, if you wish to manually control the bandwidth. Usually with vSAN fairness scheduler we do not need to modify anything, but it is good to know we can control it in case the need arises.
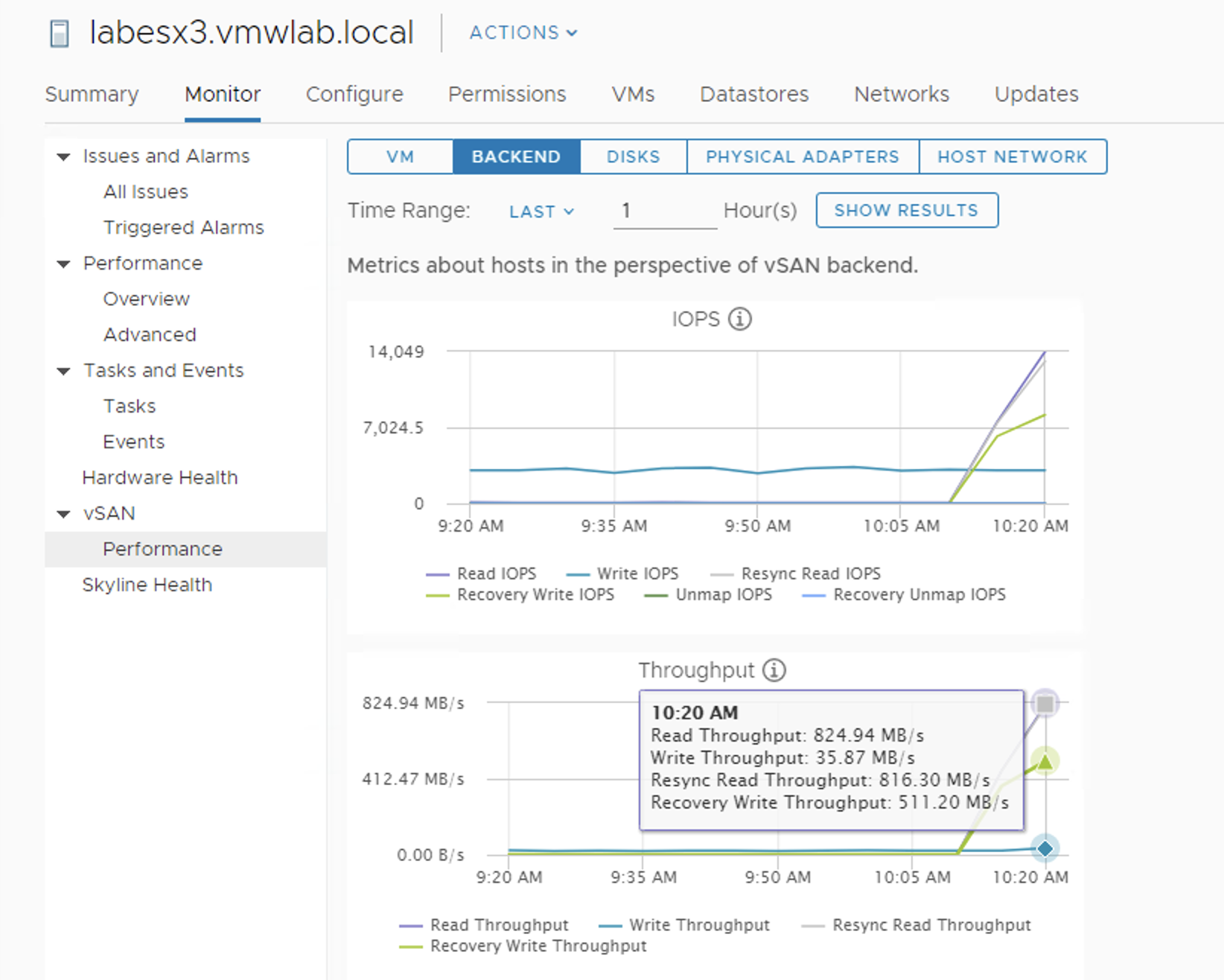
Frontend and backend traffic can be monitored with Performance Dashboard. It is very detailed. We can observe the traffic on the host level, disk group level or even on the disk level. All the traffic types are presented there.
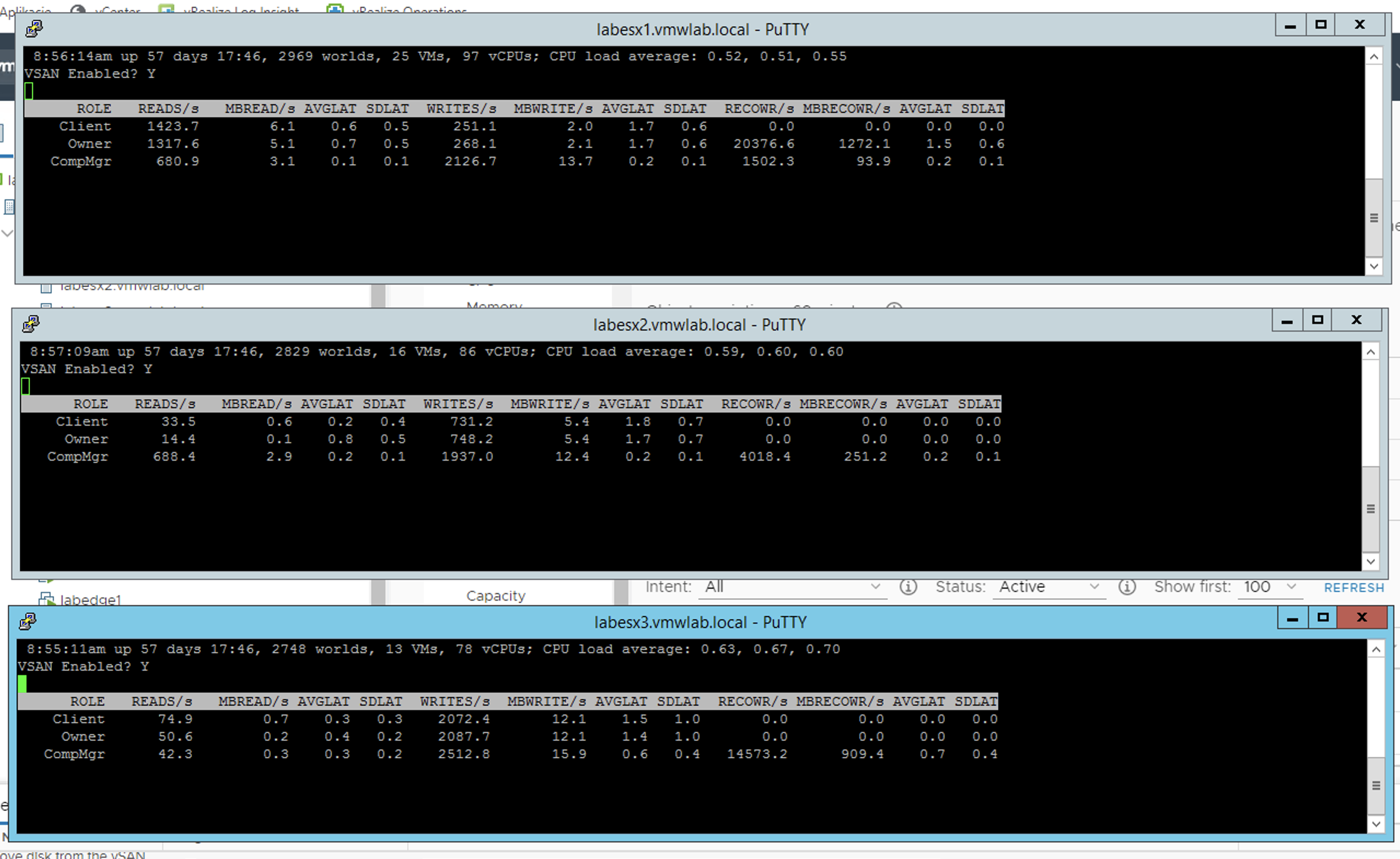
If 5-min granularity is not enough (this is what is being offered by vCenter), we can always ssh to an ESXi. esxtop + x will show near real-time vSAN stats per host. To be able to observe rebuild traffic we need to use option ‘f’ and select ‘D’ for ‘recovery write stats’.
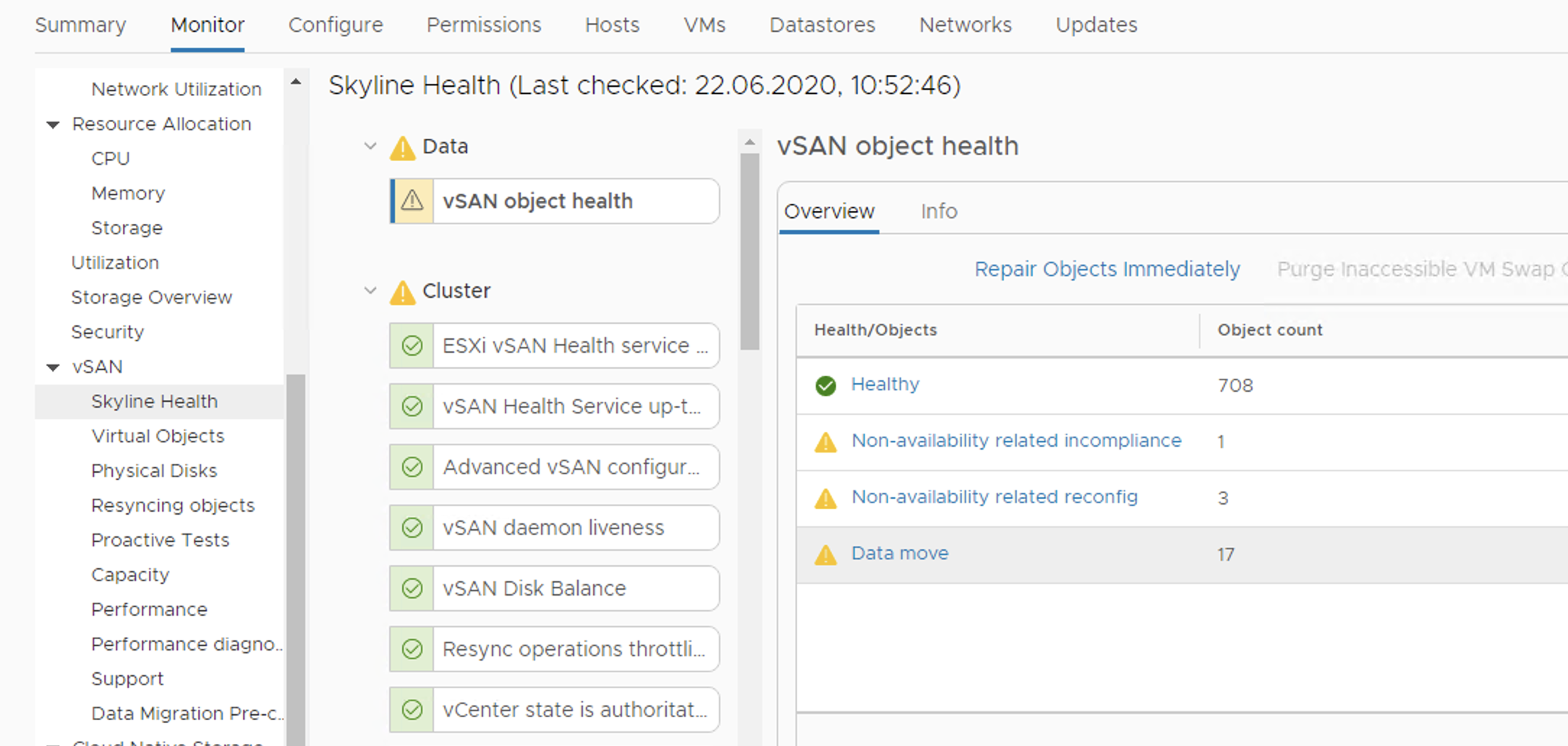
vSAN Health can be also used when we evacuate data from a disk. vSAN Object Health will show us how many objects are being rebuilt. And vSAN Health is also always a good place to check the overall status of the cluster.
Traffic Filtering and Marking is a vSphere Distributed Switch feature that protects virtualized systems from unwanted traffic and allows to apply QoS tags to certain type of traffic.
Distributed Switch requires Sphere Enterprise Plus license. But if you have vSAN, vDS is included in vSAN license so it will work on vSphere Standard license as well.
This tool is also great for a remote POC or your home lab. It will help you to invoke a controlled vSAN host partition or isolation and learn the behavior of HA or vSAN cluster. Or verify if HA your configuration is correct. This is a great tool especially for testing vSAN stretched cluster behaviour.
Sometimes creating a full site partition requires to involve a networking team, that may not be available on demand. This tool can help a virtualization team to test various scenarios on their own.
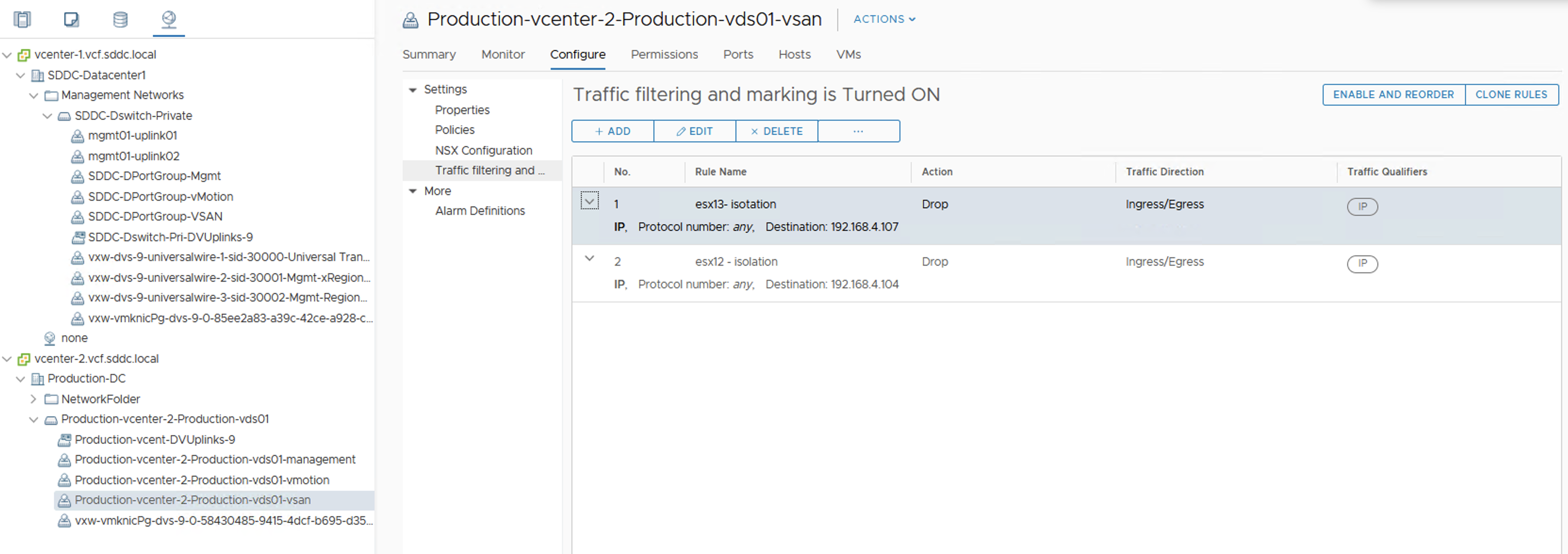
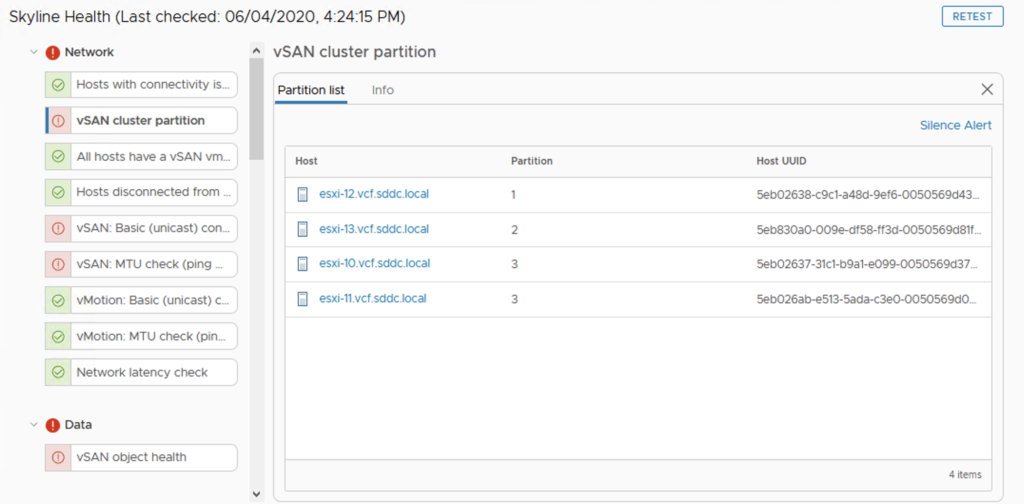
In the example below I used two DROP rules to discard the traffic coming to esx12 and esx13 in my 4-host cluster.
This way I created three cluster partitions: esx12, esx13 and the rest of the cluster (esx10 and esx11).
Right after I disabled the rules, cluster got back to normal.
Some time ago I had a booth duty during a conference. My task was to present VxRail demo. If you are familiar with it, you know that after successful installation of the whole VMware stack, you get the Hooray page.
And vSAN magic was so strong that event Geralt of Rivia couldn’t resist it. And if you are familiar with The Witcher you also know he was generally immune to magic 😉
During Proof of Concept tests, when we run various complex failure scenarios, we might be lucky to see some of the vSAN magic too…. 😉
For me Intelligent Rebuilds are pure magic. I really like the smart way vSAN handles resync, always trying to rebuild as little as possible. Imagine we have a disk group failure in a host. After Object Repair Time is up, vSAN starts to rebuild the components on other hosts. Do you know what happens when a failed disk group comes back in the middle of this process? vSAN calculates what will be more sufficient – updating existing components or building new ones.
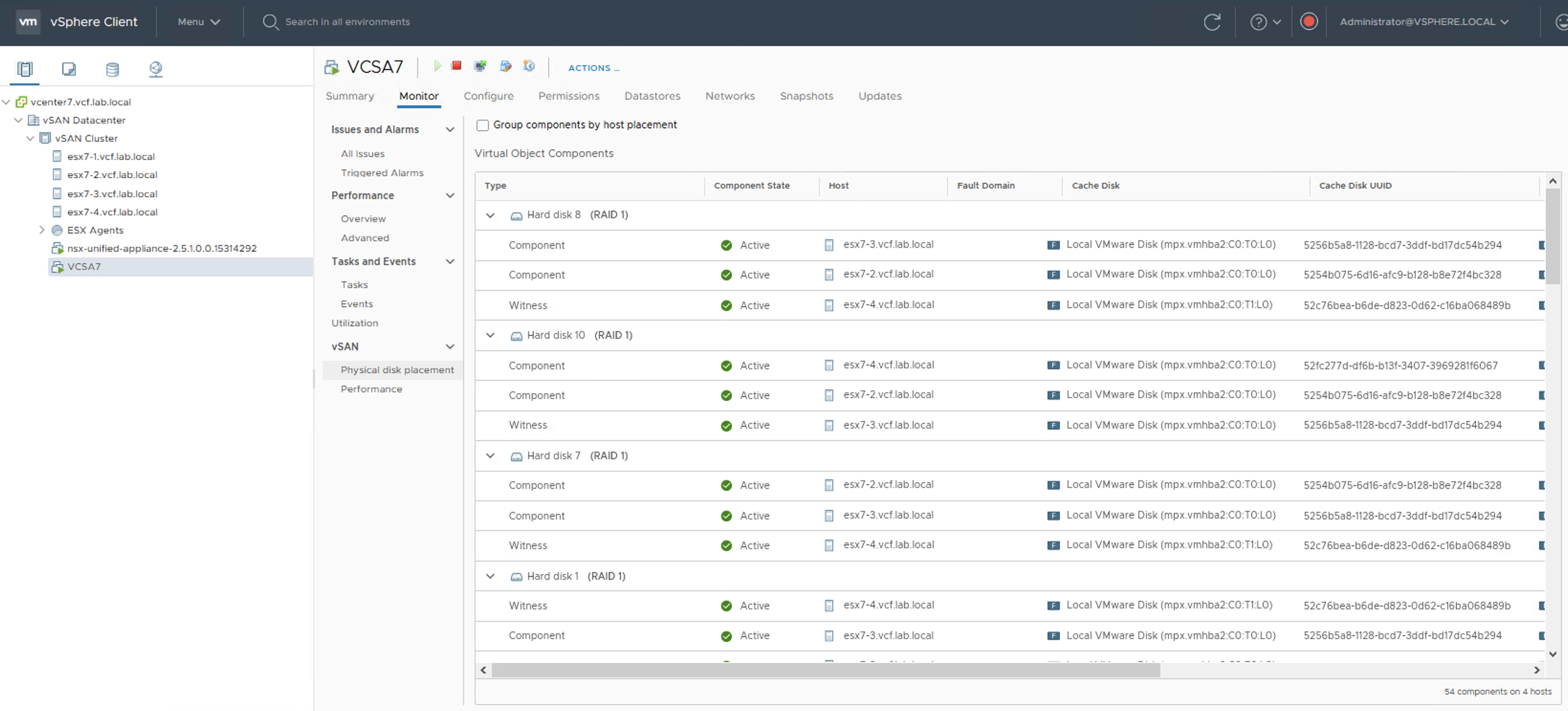
In the example below I have a vSAN cluster that consists of 4 hosts. Physical disk placement shows the components of the VMDK objects and all objects are ok.
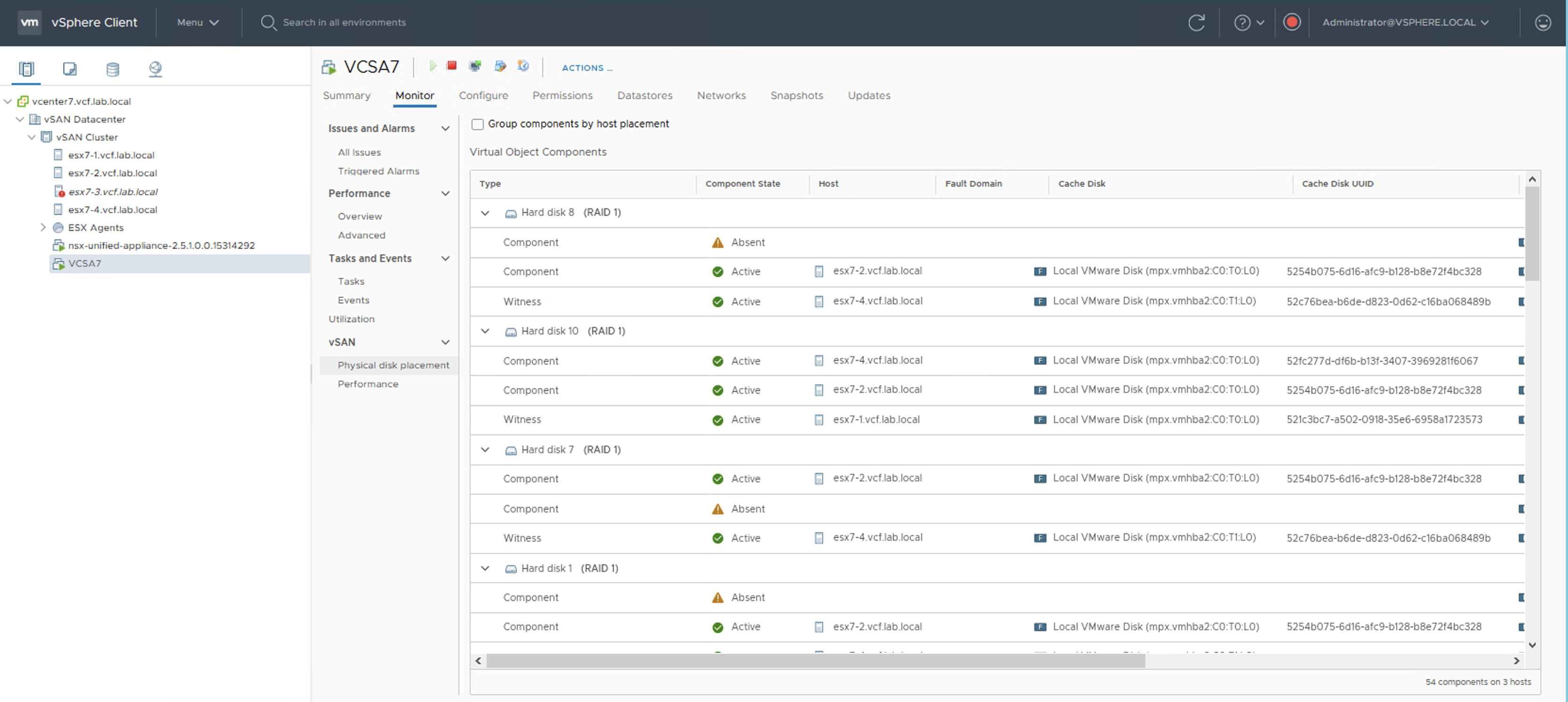
When I introduce a disk group failure on the host number 3 (esx7-3), disk placement reports that some components are absent but objects are still available, because those VMDKs have FTT-1 mirror policy (two copies and a witness).
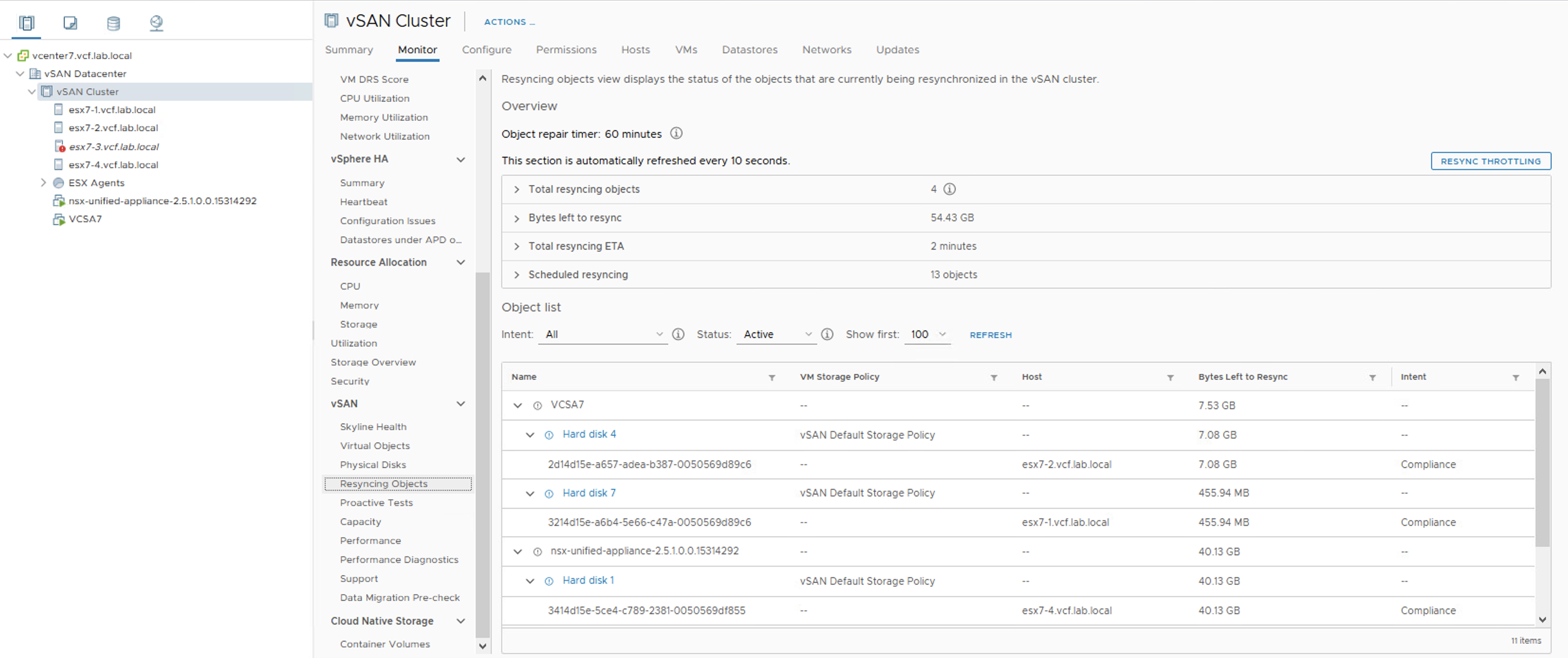
When the rebuild process kicks in, we can observe how vSAN resynchronizes objects:
In the meantime I put the disk group of the esx7-3 host back in. And here it is – for a brief second we can see two components in the Resync view. One is a new one on esx7-1 that still has 11.07 GB to resync and the second is an old one on esx7-3 that has only 262.19 MB of data to resync.
A couple of seconds later, resync process ends because vSAN chooses to resync an old object to make the process more efficient.
Ok, ok, this is not magic but it is awesome anyway 😉
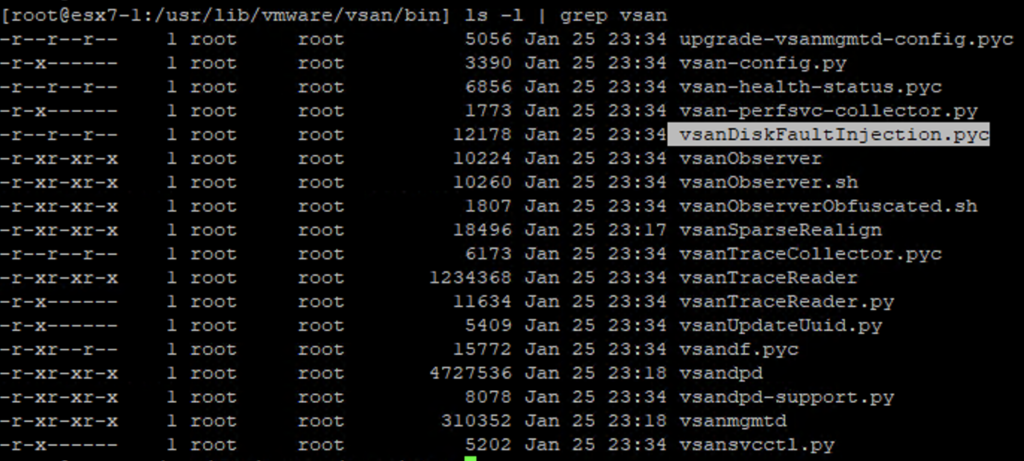
Remote Proof of Concept testing seems to be gaining in popularity recently. The major difference in on-site vs remote testing is the access to HW to test drive unplug or physical network failure. What I use in case of disk failure testing in a vSAN cluster is vSAN Disk Fault Injection script that is available on ESXi. There is no need to download anything, it is there by default, check your /usr/lib/vmware/vsan/bin path but use the script for POC/homelab only.
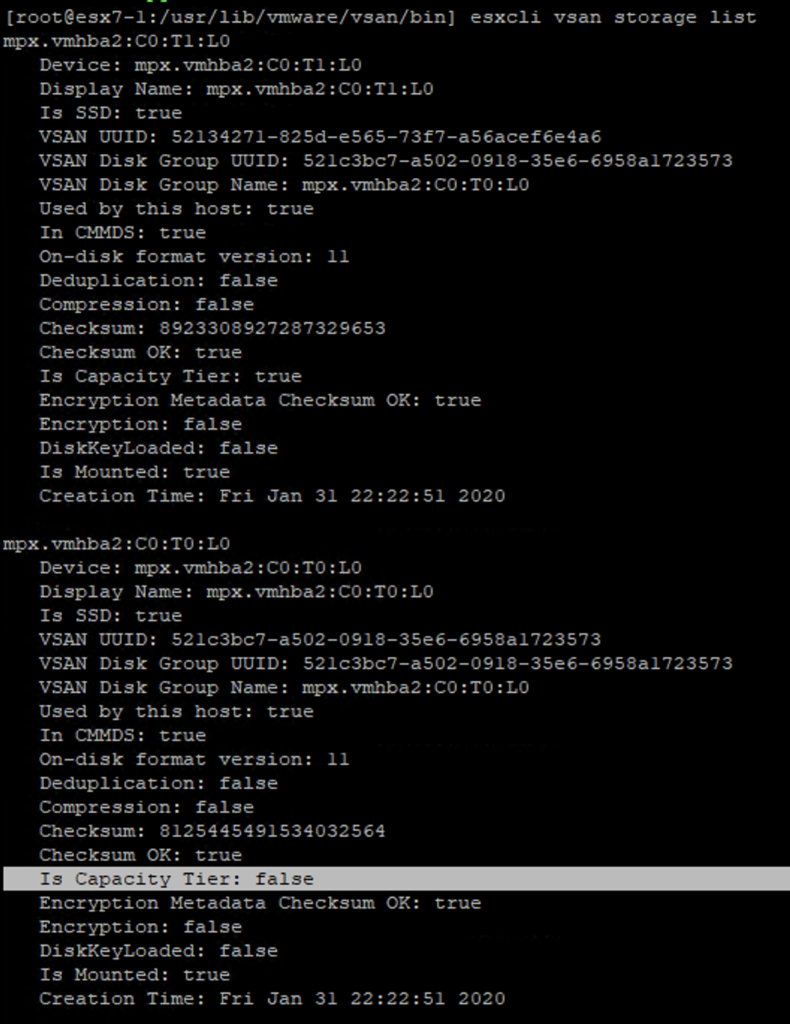
We need to have a device id do run the script, we can test a cache or capacity drive per chosen disk group. In the example below I picked mpx.vmhba2:C0:T0:L0 which was a cache drive (Is Capacity Tier:false).
You can use esxli vsan storage list for that:
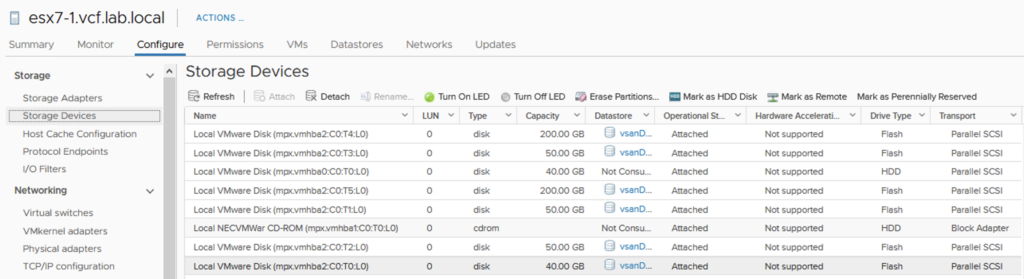
Or check in the vCenter console under Storage Devices:
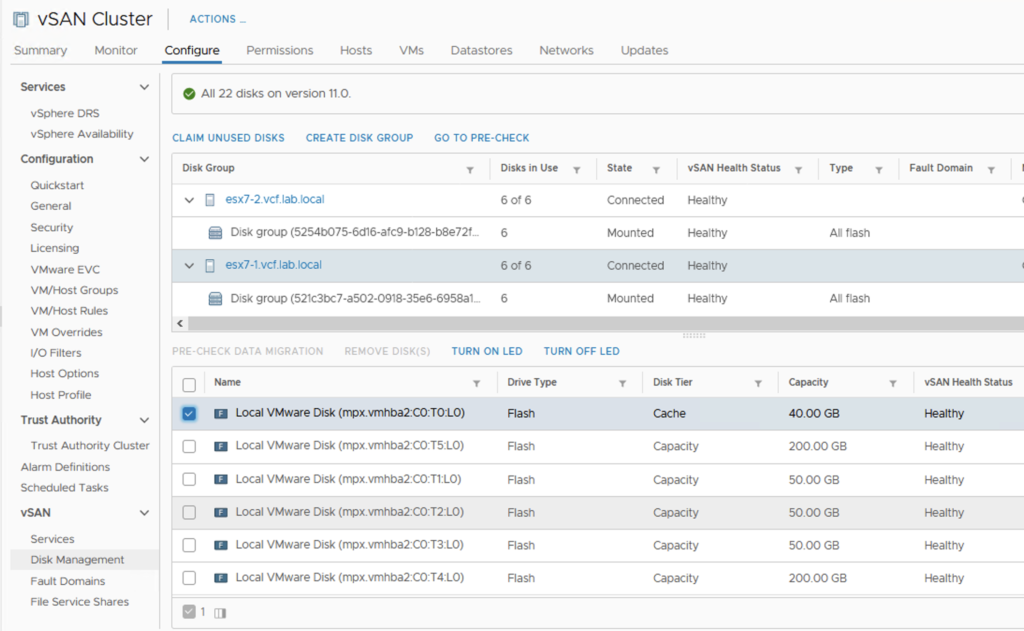
Or under Disk Management:
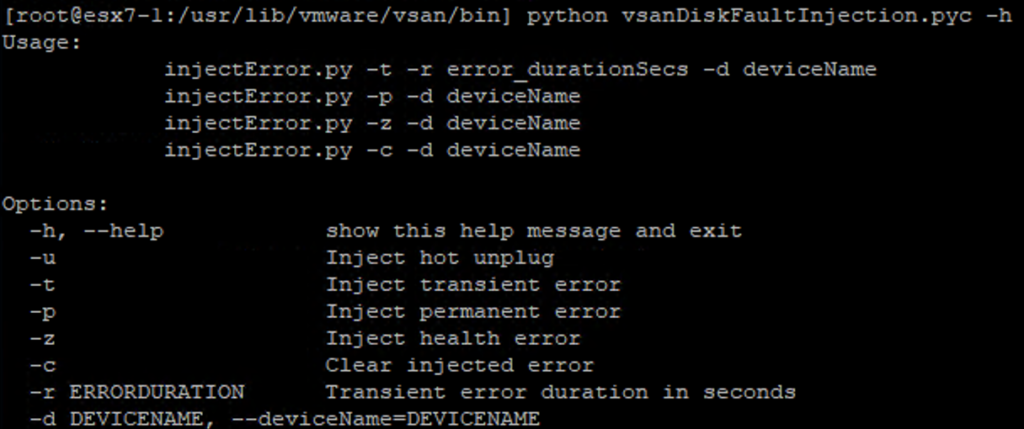
python vsanDiskFaultInjection.pyc has the following options:
I am using -u for injecting a hot unplug.
/var/log/vmkernel.log is the place you can verify the disk status:
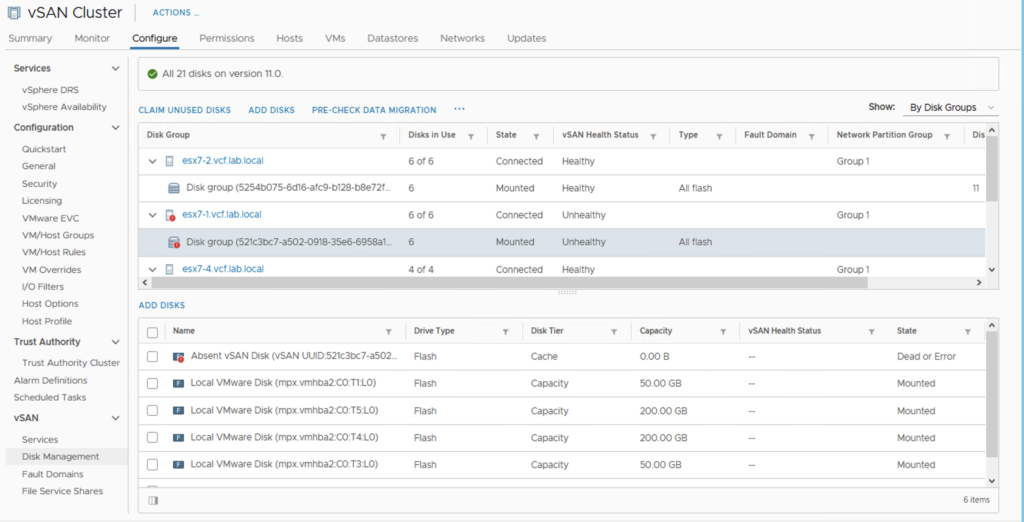
vSAN-> Disk Management will also show what is going on with a disk group that faced a drive failure.
And now we can observe the status of the data and the process of resyncing objects due to “compliance”.
After we are done with the testing, simple scan for new storage devices on the host will solve the issue.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.