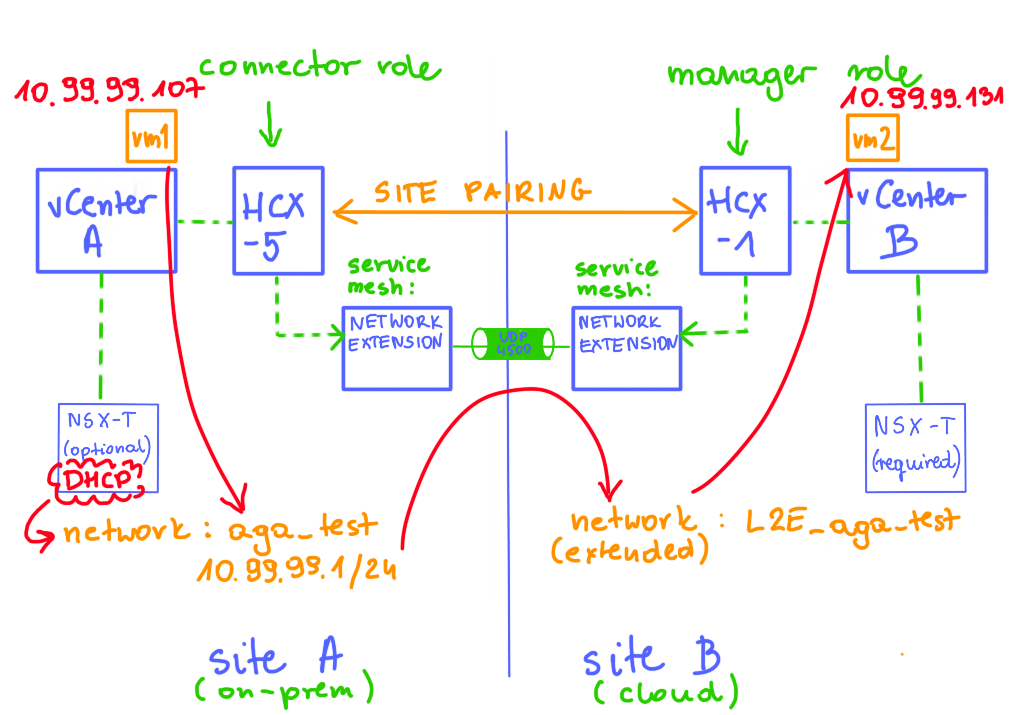
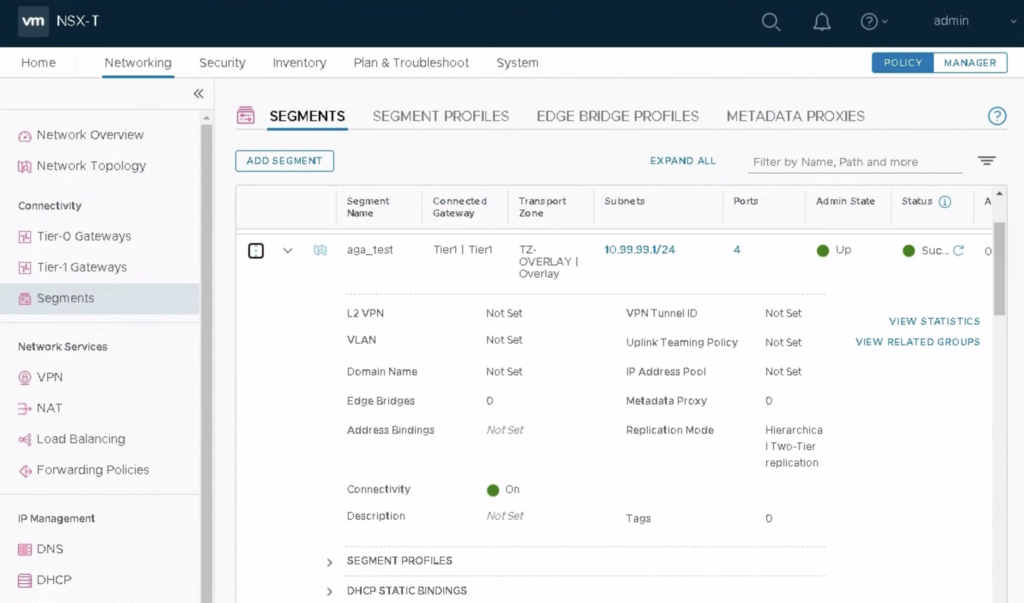
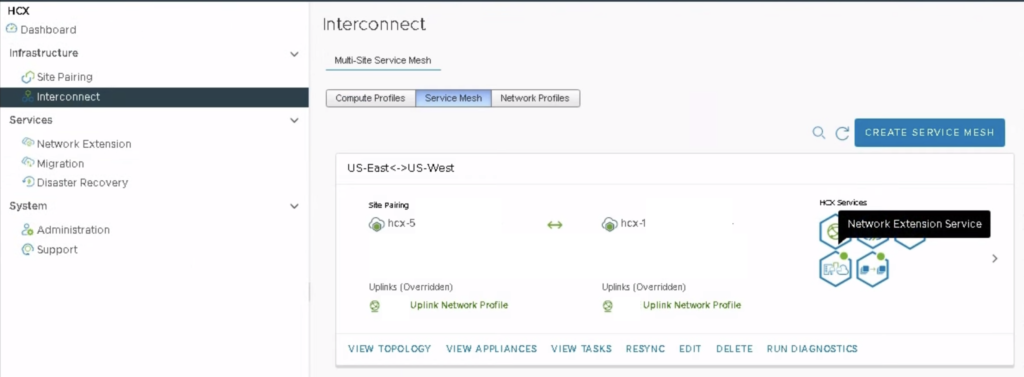
I believe the build-in HCX perftest tool should be used for every freshly deployed HCX Service Mesh before we start migrating VMs between sites. Although the test is just a benchmark (it uses iperf3, it is single threaded), it will give us an idea how fast the VM migration will be and what can be expected in production. With HCX perftest tool testing is easier than with native iperf3 because we don’t have to provide/remember any IP addresses of appliances on-prem and in the cloud ;-).
To start the test we have to ssh to HCX manager as admin and select the IX appliance we want to test:
>ccli
>list
> go x -> select your service mesh appliance
> perftest -> to check available options:
Available Commands:
all perftest uplink, ipsec, wanopt and site in one command
ipsec iperf3 perf testing against ipsec tunnels
perf iperf3 perf testing
reachability Ping remote peers to test reachability.
site iperf3 perf testing between sites
status Query the test status.
uplink iperf3 perf testing against uplink
wanopt tcpperf testing against WANOPT tunnels
Available flags are:
Flags:
-h, --help help for uplink
-i, --interval uint32 Interval in second to report. Default is 1 second. (default 1)
-m, --msgsize uint32 TCP maximum segment size to send.
-P, --parallel uint32 Number of parallel streams. Default is 1. (default 1)
-p, --port uint32 Listen port on server side. Default is 4500. -p 22 also allowed. (default 4500)
-T, --runtimeout uint32 Individual test duration in second. Default is 1 minute. (default 60)
-t, --timeout uint32 Total timeout in seconds. Default 10 min. (default 600)
-v, --verbose Show details during testing if set.
PERFTEST SITE: GENERAL TUNNEL CHECK
>perftest site
++++++++++ StartTest ++++++++++
---------- Site-0 [192.0.2.33 >>> 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-30.00 sec 13.8 GBytes 3.96 Gbits/sec 365 sender
[ 4] 0.00-30.00 sec 13.8 GBytes 3.95 Gbits/sec receiver
Done
---------- Site-0 [192.0.2.33 <<< 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-30.00 sec 14.8 GBytes 4.24 Gbits/sec 167 sender
[ 4] 0.00-30.00 sec 14.8 GBytes 4.23 Gbits/sec receiver
Done
The iperf3 native commands that are used for this test with default values :
iperf3 -c 192.0.2.34 -i 1 -p 9000 -P 1 -t 30
iperf3 -s -p 9000 -B 192.0.2.33
PERFTEST IPSEC: TEST INSIDE IPSEC
> perftest ipsec
++++++++++ StartTest ++++++++++
---------- Ipsec-0 [t_0, 192.0.2.37 >>> 192.0.2.45] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-30.00 sec 3.40 GBytes 973 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 3.39 GBytes 972 Mbits/sec receiver
Done
---------- Ipsec-0 [t_0, 192.0.2.37 <<< 192.0.2.45] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-30.00 sec 3.40 GBytes 974 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 3.40 GBytes 973 Mbits/sec receiver
Done
---------- Ipsec-1 [t_0, 192.0.2.38 >>> 192.0.2.46] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-30.00 sec 3.40 GBytes 973 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 3.40 GBytes 973 Mbits/sec receiver
Done
---------- Ipsec-1 [t_1, 192.0.2.38 <<< 192.0.2.46] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-30.00 sec 3.40 GBytes 974 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 3.40 GBytes 973 Mbits/sec receiver
Done
---------- Ipsec-2 [t_2, 192.0.2.39 >>> 192.0.2.47] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-30.00 sec 3.39 GBytes 971 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 3.39 GBytes 970 Mbits/sec receiver
Done
---------- Ipsec-2 [t_2, 192.0.2.39 <<< 192.0.2.47] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-30.00 sec 3.39 GBytes 971 Mbits/sec 1181 sender
[ 4] 0.00-30.00 sec 3.39 GBytes 970 Mbits/sec receiver
Done
The iperf3 native commands that are used for this test with default values :
iperf3 -c 192.0.2.45 -i 1 -p 9000 -P 1 -t 30
iperf3 -s -p 9000 -B 192.0.2.37
PERFTEST UPLINK: UPLINK INTERFACE CHECK
> perftest uplink
Testing uplink reachability…
Uplink-0 round trip time:
rtt min/avg/max/mdev = 66.734/67.081/68.135/0.578 ms
Uplink native throughput test is initiated from LOCAL site.
++++++++++ StartTest ++++++++++
---------- Uplink-0 [te_0, a.a.a.a >>> b.b.b.b] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 5.20 GBytes 745 Mbits/sec 5116 sender
[ 4] 0.00-60.00 sec 5.20 GBytes 744 Mbits/sec receiver
Done
---------- Uplink-0 [te_0, a.a.a.a <<< b.b.b.b] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 4.55 GBytes 652 Mbits/sec 6961 sender
[ 4] 0.00-60.00 sec 4.55 GBytes 651 Mbits/sec receiver
Done
The iperf3 native commands that are used for this test with default values :
iperf3 -c a.a.a.a -i 1 -p 4500 -P 1 -B b.b.b.b -t 60
iperf3 -c a.a.a.a -i 1 -p 4500 -P 1 -B b.b.b.b -t 60
Keep in mind that this is the only test that uses 4500 TCP port by default. If you have only 4500 UDP port open (this is the standard HCX Uplink requirement), your test will fail. You will see probably something like this:
"Command error occurs: Error calling peer [a.a.a.a.a:9445]: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp b.b.b.b:9445: connect: connection refused"
PERFTEST ALL: ALL TESTS COMBINED
This test will run iperf for uplink, ipsec, wanopt and site.
>perftest all
========== PERFTEST ALL STARTING ==========
== WanOpt is Present ==
== TOTAL # of TESTs : 11 ==
== ESTIMATED TEST DURATION : 12 minutes ==
-T option to change individual test duration [default 60 sec]
-k option to skip 'perftest uplink' if tcp port 4500 or 22 not opened
== Are you ready to start ?? [y/n]:
USEFUL FLAGS
You can use more streams to saturate the pipe (-P), but keep in mind the test uses a single thread.
>perftest site -P 2
++++++++++ StartTest ++++++++++
---------- Site-0 [ 192.0.2.33 >>> 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 16.8 GBytes 2.40 Gbits/sec 1498 sender
[ 4] 0.00-60.00 sec 16.8 GBytes 2.40 Gbits/sec receiver
[ 6] 0.00-60.00 sec 16.4 GBytes 2.35 Gbits/sec 1815 sender
[ 6] 0.00-60.00 sec 16.4 GBytes 2.35 Gbits/sec receiver
[SUM] 0.00-60.00 sec 33.2 GBytes 4.76 Gbits/sec 3313 sender
[SUM] 0.00-60.00 sec 33.2 GBytes 4.75 Gbits/sec receiver
Done
---------- Site-0 [ 192.0.2.33 <<< 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-60.00 sec 19.0 GBytes 2.72 Gbits/sec 937 sender
[ 4] 0.00-60.00 sec 19.0 GBytes 2.72 Gbits/sec receiver
[ 6] 0.00-60.00 sec 19.5 GBytes 2.80 Gbits/sec 806 sender
[ 6] 0.00-60.00 sec 19.5 GBytes 2.79 Gbits/sec receiver
[SUM] 0.00-60.00 sec 38.5 GBytes 5.52 Gbits/sec 1743 sender
[SUM] 0.00-60.00 sec 38.5 GBytes 5.51 Gbits/sec receiver
Done
>perftest site -P 4
++++++++++ StartTest ++++++++++
---------- Site-0 [ 192.0.2.33 >>> 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 9.22 GBytes 1.32 Gbits/sec 2108 sender
[ 4] 0.00-60.00 sec 9.21 GBytes 1.32 Gbits/sec receiver
[ 6] 0.00-60.00 sec 9.13 GBytes 1.31 Gbits/sec 2194 sender
[ 6] 0.00-60.00 sec 9.12 GBytes 1.31 Gbits/sec receiver
[ 8] 0.00-60.00 sec 9.20 GBytes 1.32 Gbits/sec 2288 sender
[ 8] 0.00-60.00 sec 9.19 GBytes 1.32 Gbits/sec receiver
[ 10] 0.00-60.00 sec 8.71 GBytes 1.25 Gbits/sec 2396 sender
[ 10] 0.00-60.00 sec 8.70 GBytes 1.25 Gbits/sec receiver
[SUM] 0.00-60.00 sec 36.3 GBytes 5.19 Gbits/sec 8986 sender
[SUM] 0.00-60.00 sec 36.2 GBytes 5.19 Gbits/sec receiver
Done
---------- Site-0 [ 192.0.2.33 <<< 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-60.00 sec 10.2 GBytes 1.45 Gbits/sec 2071 sender
[ 4] 0.00-60.00 sec 10.1 GBytes 1.45 Gbits/sec receiver
[ 6] 0.00-60.00 sec 10.0 GBytes 1.43 Gbits/sec 1932 sender
[ 6] 0.00-60.00 sec 10.0 GBytes 1.43 Gbits/sec receiver
[ 8] 0.00-60.00 sec 10.2 GBytes 1.47 Gbits/sec 2149 sender
[ 8] 0.00-60.00 sec 10.2 GBytes 1.47 Gbits/sec receiver
[ 10] 0.00-60.00 sec 10.3 GBytes 1.47 Gbits/sec 2366 sender
[ 10] 0.00-60.00 sec 10.3 GBytes 1.47 Gbits/sec receiver
[SUM] 0.00-60.00 sec 40.7 GBytes 5.83 Gbits/sec 8518 sender
[SUM] 0.00-60.00 sec 40.7 GBytes 5.82 Gbits/sec receiver
Done
You can change MTU to test the best option (-m) and identify any MTU mismatch issues. You can also modify MTU settings in HCX Network Profile for Uplink profile.
> perftest site -m 1390
++++++++++ StartTest ++++++++++
---------- Site-0 [ 192.0.2.33 >>> 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 30.6 GBytes 4.37 Gbits/sec 518 sender
[ 4] 0.00-60.00 sec 30.5 GBytes 4.37 Gbits/sec receiver
Done
---------- Site-0 [192.0.2.33 <<< 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-60.00 sec 31.1 GBytes 4.46 Gbits/sec 270 sender
[ 4] 0.00-60.00 sec 31.1 GBytes 4.45 Gbits/sec receiver
Done
perftest site -m 9000
++++++++++ StartTest ++++++++++
---------- Site-0 [ 192.0.2.33 >>> 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
server workload started
[ 4] 0.00-60.00 sec 29.4 GBytes 4.21 Gbits/sec 341 sender
[ 4] 0.00-60.00 sec 29.4 GBytes 4.20 Gbits/sec receiver
Done
---------- Site-0 [ 192.0.2.33 <<< 192.0.2.34] ----------
Duration Transfer Bandwidth Retransmit
[ 4] 0.00-60.00 sec 29.3 GBytes 4.19 Gbits/sec 307 sender
[ 4] 0.00-60.00 sec 29.2 GBytes 4.19 Gbits/sec receiver
Done